BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
language-model
목록 보기
5/20
분야 및 배경지식
- 사전학습(pre-train) 언어모델
- GPT
- language model 목적함수를 사용해 autoregressive 방식으로 학습
- 다시 말해, 왼쪽의 텍스트만을 참고해 오른쪽의 새로운 토큰을 예측하는 방식으로 학습
- BERT
- masked langauge model 목적함수를 사용해 bidirectional 방식으로 학습
- 다시 말해, 가려진 토큰 양쪽의 텍스트를 모두 참고하여 가려진 토큰을 예측하는 방식으로 학습
- GPT
문제점
- 기존의 모델들은 특정한 종류의 목적 태스크에 초점을 두어 적용가능성(=applicability)을 제한
해결책
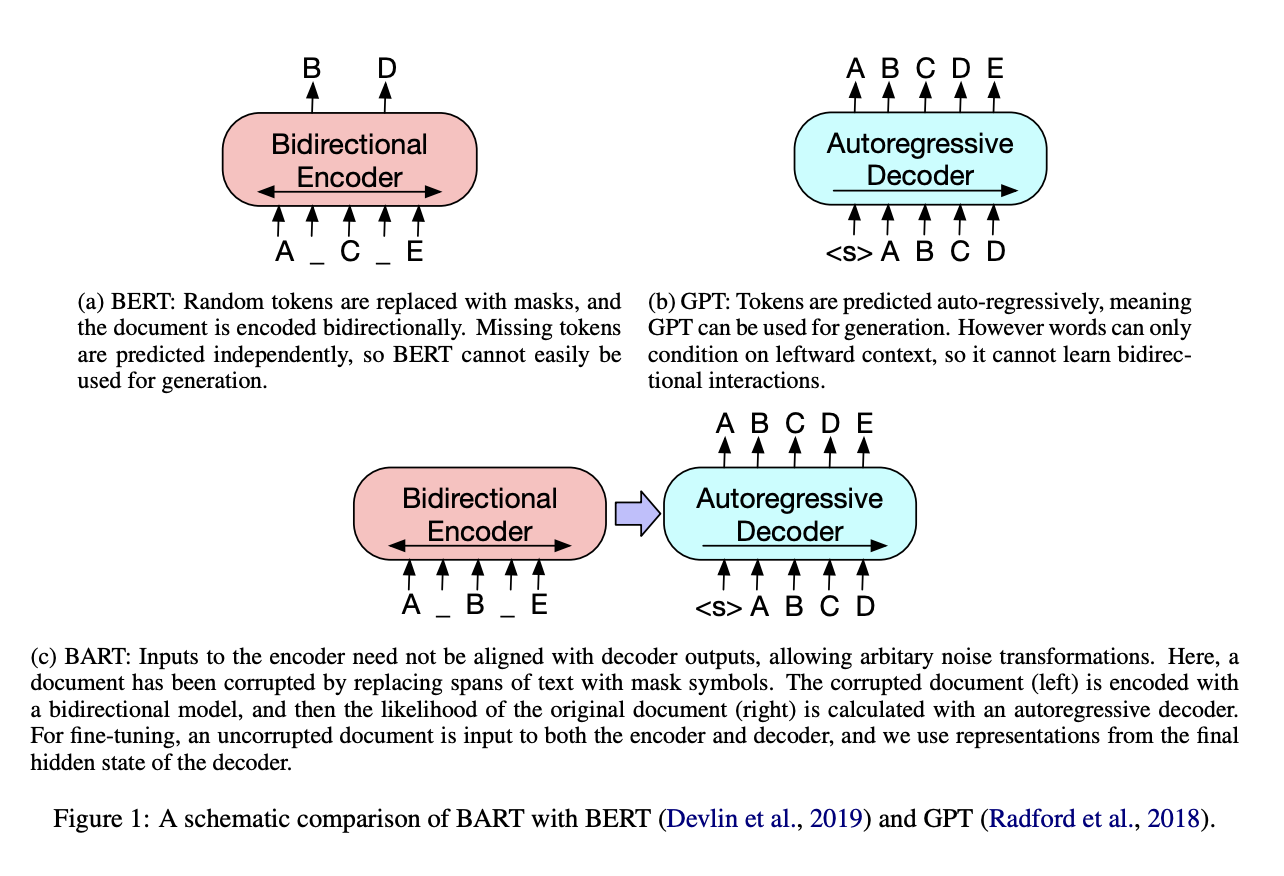
BART
- 시퀀스-시퀀스 모델을 사전학습하기 위한 denoising autoencoder
- BERT로 대표되는 양방향(bidirectional) 모델과 GPT로 대표되는 자동회귀(Autoregressive) 모델을 결합
- Transformer 아키텍처 사용
- 임의의 노이즈를 이용해 텍스트를 변형시키고, 원문을 복원하는 법을 모델로 하여금 배우도록 사전학습
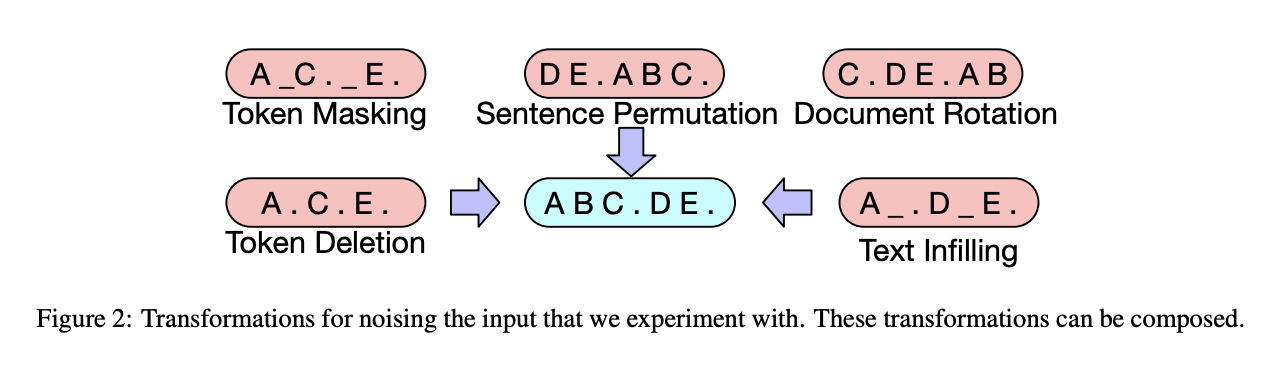
- 토큰 마스킹
- 랜덤한 토큰을 샘플링해 [MASK] 토큰으로 치환
- 토큰 삭제
- 랜덤한 토큰을 삭제
- 텍스트 채우기
- 하나의 토큰이 아닌 특정 범위(span)를 단일한 [MASK] 토큰으로 치환
- 모델로 하여금 얼마나 많은 토큰이 소실되었는지 예측하도록 함
- 문장 순서 치환(permutation)
- 랜덤하게 문장 순서 변경
- 문서 회전(rotation)
- 특정 토큰으로 문서가 시작하도록 문서 내 토큰의 순서를 변경
- 토큰 마스킹
평가
- 태스크
- SQuAD: 추출형(extractive) 질의응답
- MNLI: 문장 사이의 포함(entailment) 관계 분류
- ELI5: 긴 형태의 추상형(abstractive) 질의응답
- XSum: 뉴스 요약
- ConvAI2: 대화 응답 생성
- CNN/DM: 뉴스 요약
- 결과
- 사전학습 방식의 효용성은 태스크에 따라 달라짐
- 하지만 전반적으로 토큰 마스킹이 중요한 역할
- 전반적으로, BART가 모든 태스크에 있어서 좋은 성능
- 사전학습 방식의 효용성은 태스크에 따라 달라짐
의의
- 텍스트 생성 태스크와 이해 태스크 모두에서 좋은 성능을 보임
- 생성 태스크의 경우, 질적 평가에 있어서도 좋은 성능
한계
- 다양한 사전학습 방식을 탐구하였으나, 태스크에 따라 사전학습 방식의 성능이 달라지기 때문에 일반화가 어려워 아쉬움

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab