language-model
1.[Transformer] Attention Is All You Need
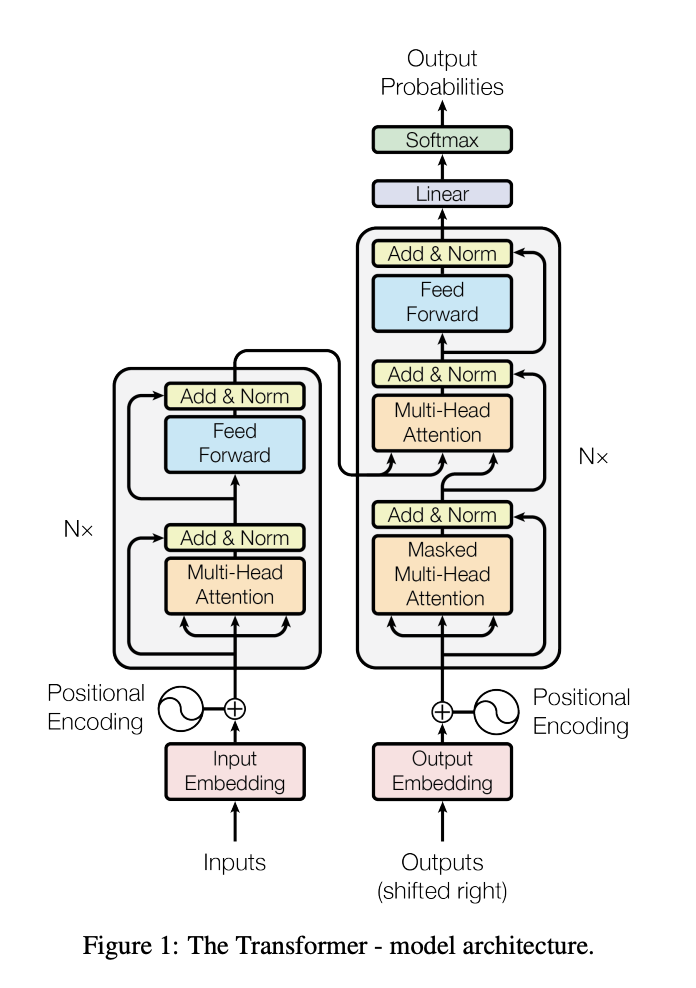
Attention Is All You Need, NIPS 2017
2.[GPT] Improving Language Understanding by Generative Pre-Training
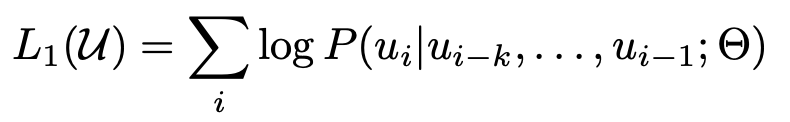
Improving Language Understanding by Generative Pre-Training
3.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, arXiv 2018
4.RoBERTa: A Robustly Optimized BERT Pretraining Approach

RoBERTa: A Robustly Optimized BERT Pretraining Approach, Facebook AI
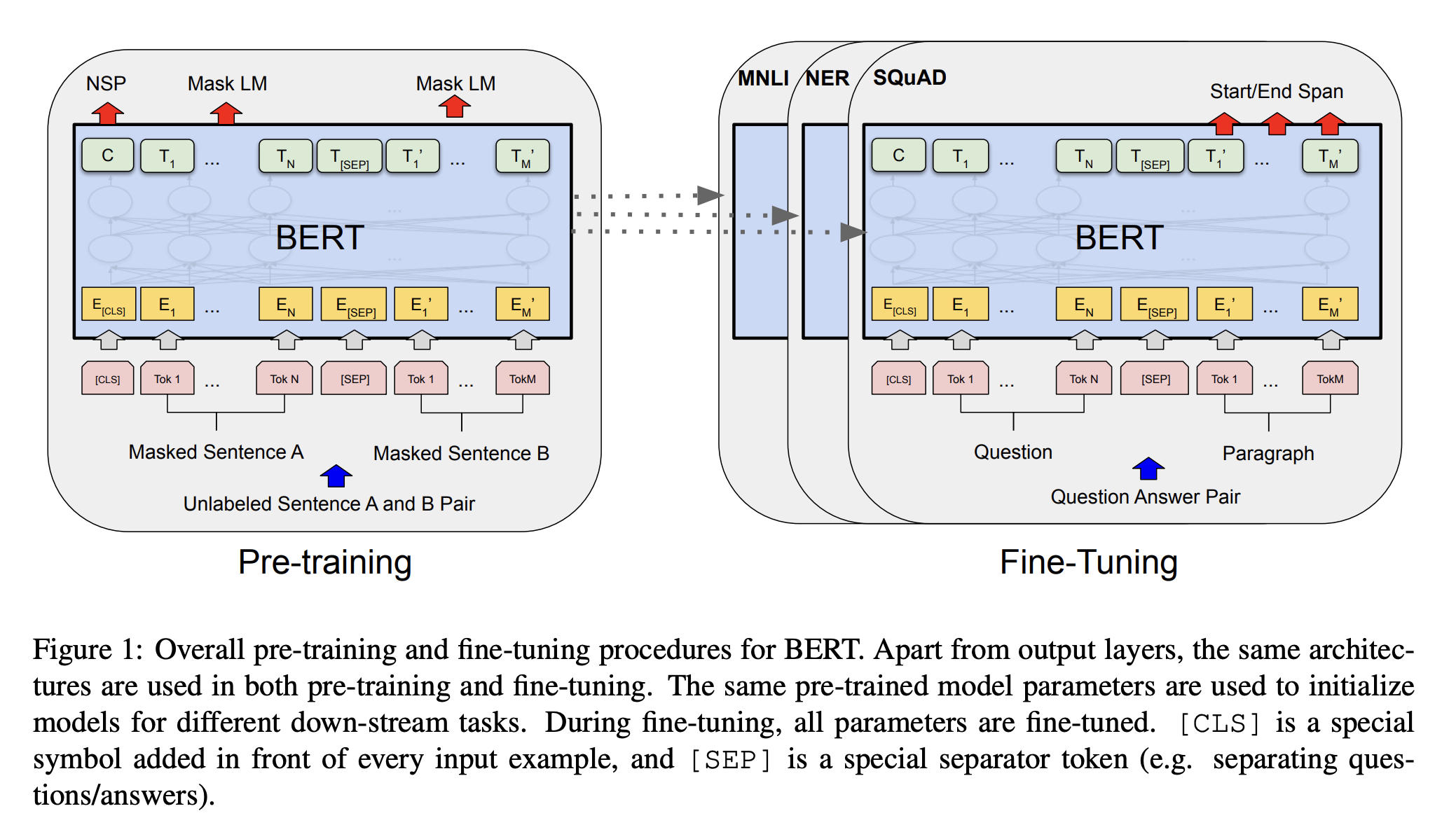
5.BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
6.[T0] Multitask Prompted Training Enables Zero-Shot Task Generalization
Multitask Prompted Training Enables Zero-Shot Task Generalization, ICLR 2022
7.LLaMA: Open and Efficient Foundation Language Models
LLaMA: Open and Efficient Foundation Language Models, arXiv 2023
8.Sparks of Artificial General Intelligence: Early experiments with GPT-4
Sparks of Artificial General Intelligence: Early experiments with GPT-4, arXiv 2023
9.OPT: Open Pre-trained Transformer Language Models
OPT: Open Pre-trained Transformer Language Models, arXiv 2022
10.Self-Attention with Relative Position Representations
인풋들 사이의 상대적인 거리 정보를 반영하는 Relative Position Representation 논문 정리 (+ Self-Attention 설명)
11.Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation

학습 시 사용한 토큰 수보다 추론 시 더 큰 토큰을 처리해야할 때, extrapolation을 도와주는 ALiBi attention (ICLR 2022)
12.KERPLE: Kernelized Relative Positional Embedding for Length Extrapolation
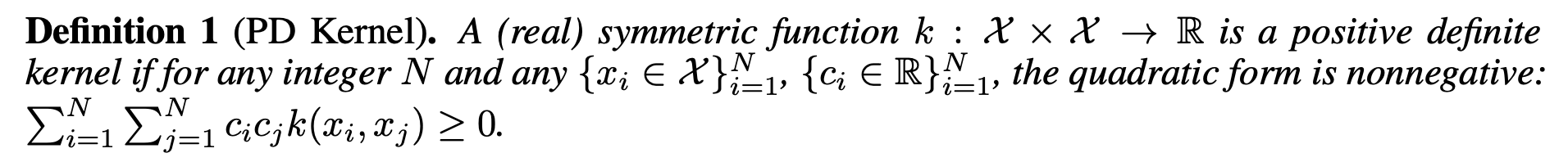
상대적 위치 임베딩 (RPE) 방법론 탐색: composite kernel (합 커널)을 활용하여 위치 정보를 포함하는 KERPLE 논문 정리
13.FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
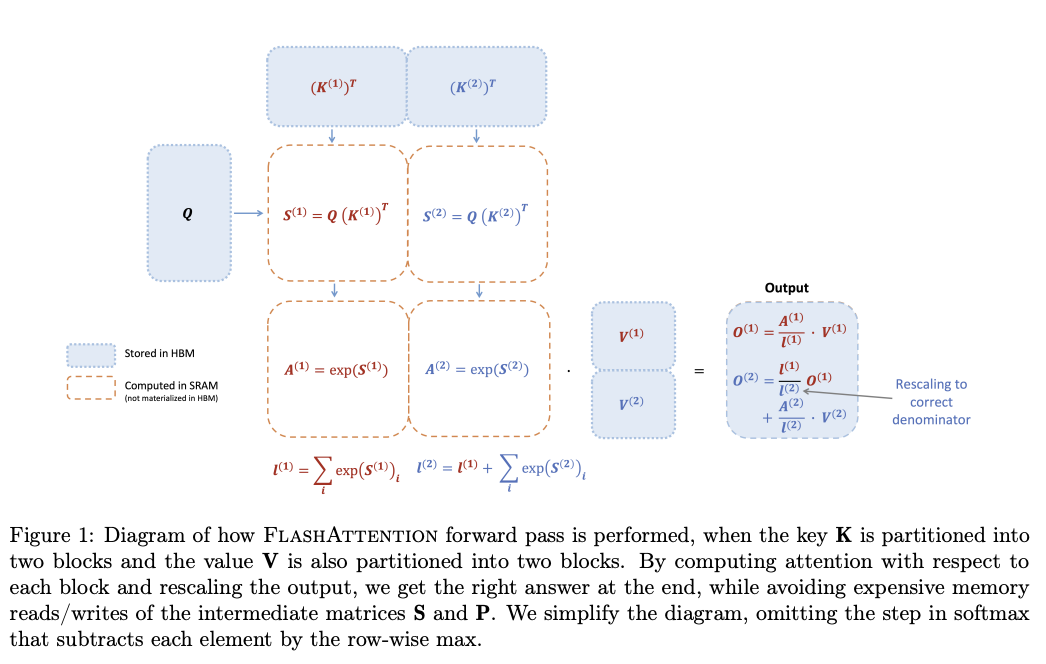
Attention 연산을 효율적으로 바꾼 Flash Attention 알고리즘 소개
14.LLM 사전학습 강의 by Upstage - 0. Introduction
DeepLearning.AI 강의 | LLM 사전학습 (Upstage) - 0. Introduction
15.LLM 사전학습 강의 by Upstage - 1. 왜 사전학습이 필요한가?

DeepLearning.AI 강의 | LLM 사전학습 (Upstage) - 1. 왜 사전학습이 필요한가?
16.LLM 사전학습 강의 by Upstage - 2. 데이터 준비
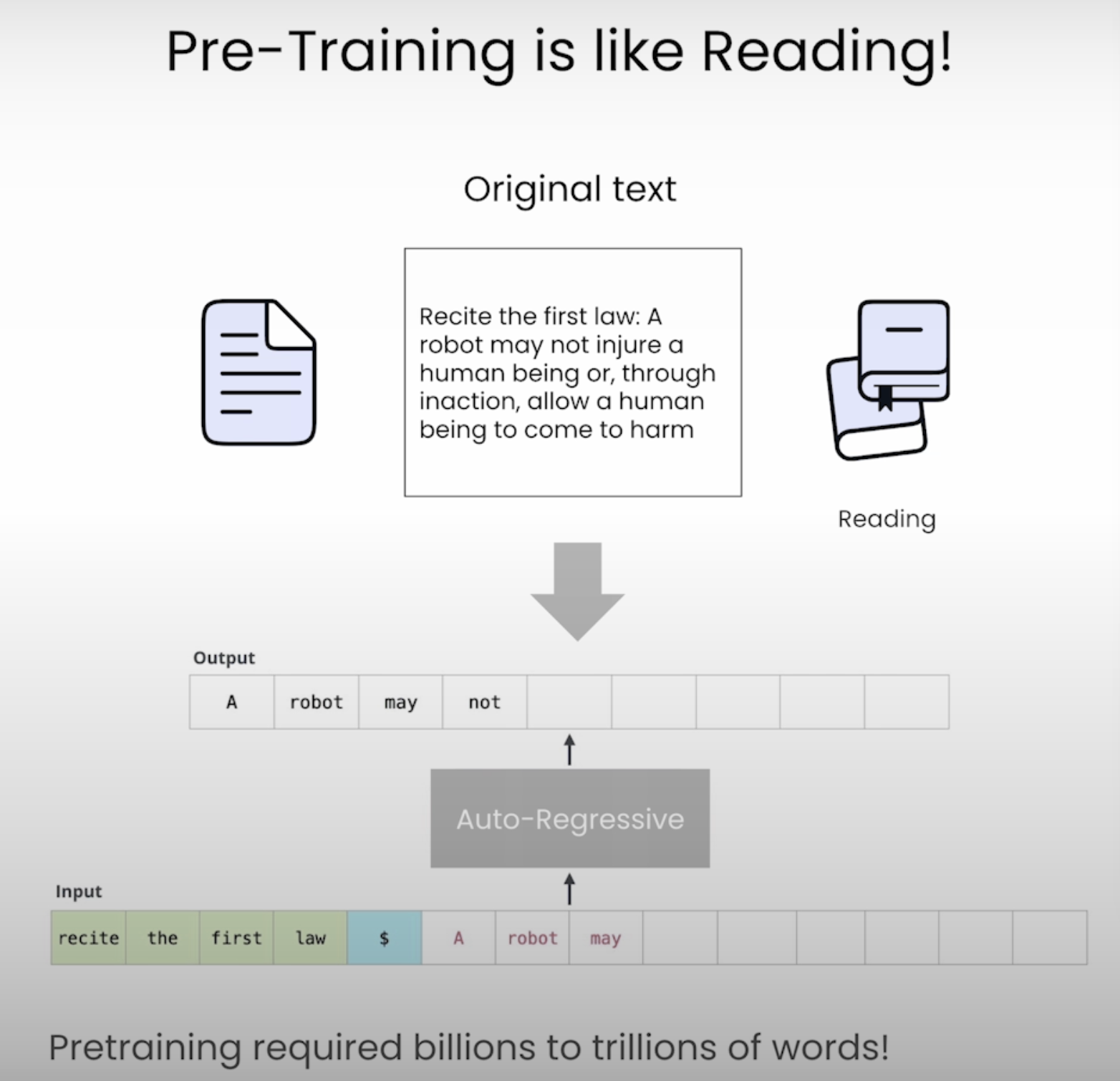
DeepLearning.AI 강의 | LLM 사전학습 (Upstage) - 2. 데이터 준비
17.STEM: FFN의 up projection에서 토큰 인덱스 임베딩 벡터를 활용하는 새로운 모델
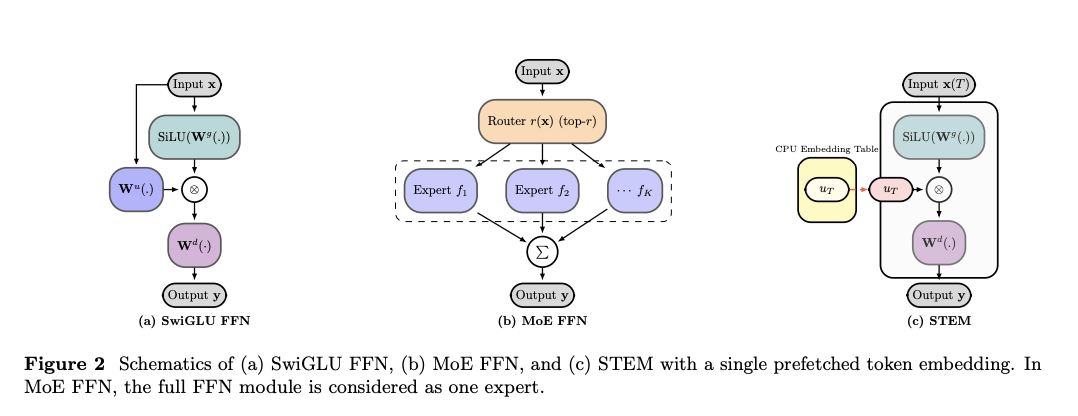
학습 및 추론 효율성을 높이고 모델의 파라미터 지식 수정의 가능성을 높인 새로운 모델 패러다임: STEM 논문 리뷰
18.HyperCLOVA X THINK: 네이버의 새로운 Reasoning 모델 논문 정리
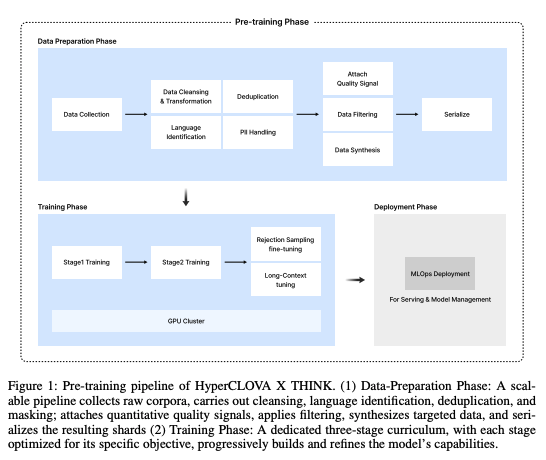
Hyper CLOVA X THINK 테크니컬 리포트 핵심내용 정리
19.HyperCLOVA X 32B Think: Vision-to-Text로 확장한 네이버의 멀티모달 모델
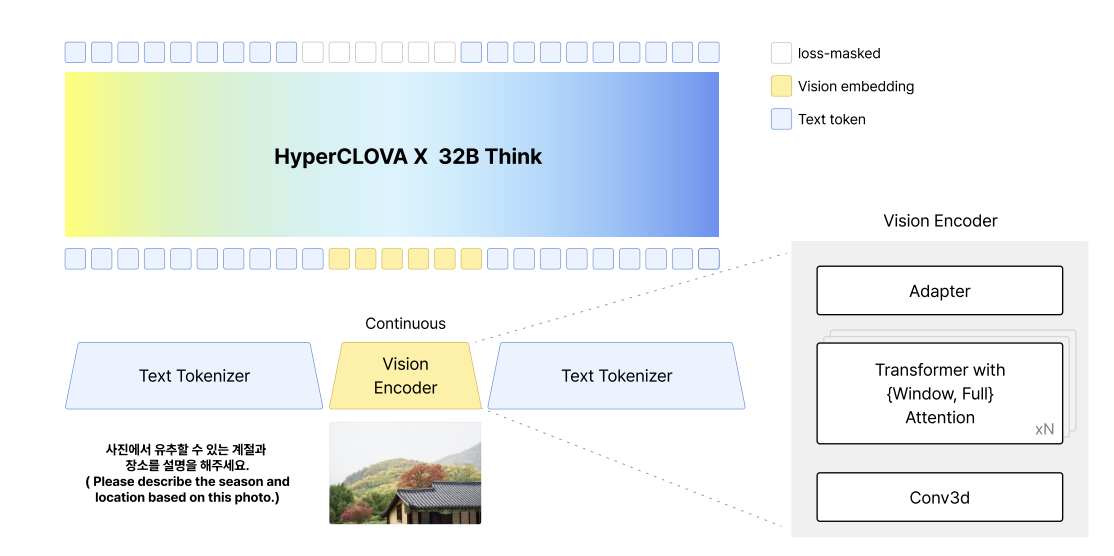
Visual Encoder로 비전 역량을 확장한 HyperCLOVA X 32B Think 모델 논문 정리
20.HyperClova X 8B Omni: 네이버의 첫 옴니모델 논문 정리
네이버의 첫 옴니모델 테크니컬 리포트 요약 정리