Building a Role Specified Open-Domain Dialogue System Leveraging Large-Scale Language Models
NAACL 2022
분야 및 배경지식
Synthetic Data Gegeration, Language Model, Dialogue System
- Sythetic Dialogue Generation
- 데이터 수집의 비용을 줄이기 위해, 실제와 유사한 가짜 데이터를 생성하여 이를 이용해 모델을 학습하는 방법이 Synthetic Data Generation
- 특정 태스크(예: 식당 예약)를 위한 대화 데이터 생성의 경우 대개 태스크의 스키마, 규칙, 템플릿 등을 정의해야 함
- 최근 사전학습된 언어모델(Language Model; LM)을 사용해 데이터를 생성하는 연구가 많이 진행되고 있음
- Role in Dialogue
- 대화의 자연스러움을 위해서는 대화 시스템, 챗봇에 역할(Role)을 부여하는 것이 필요
- 주어진 페르소나/정체성을 유지함과 동시에 시스템의 정책 또한 만족해야 함
문제점
- 오픈도메인 대화시스템에 특정한 역할(예: 성격, 스타일 등)을 부여하는 것은 어려움
- 챗봇이 사람과 자연스럽게 대화하기 위해서는 굉장히 많은 수의 대화 데이터가 필요함
해결책
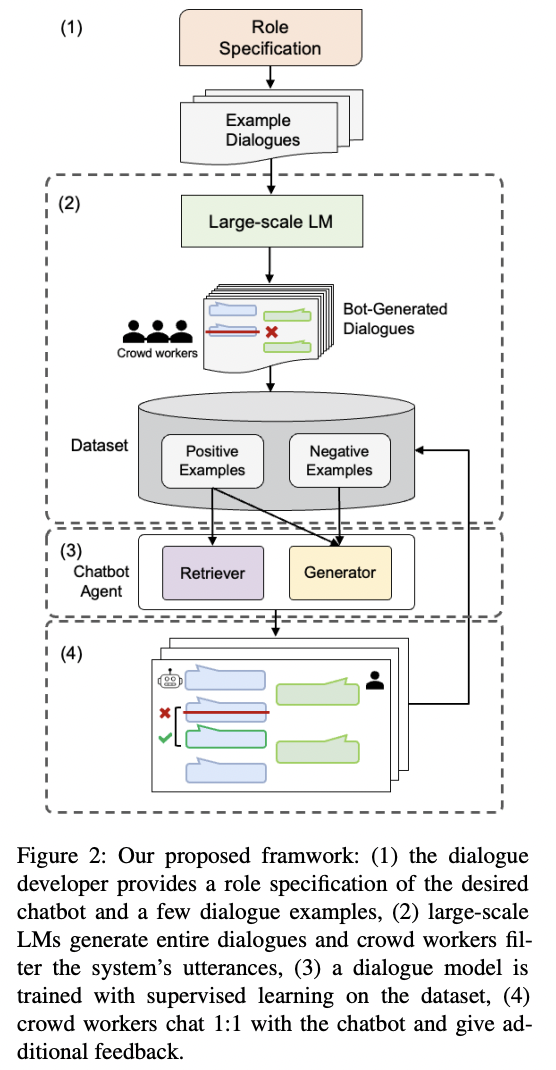
RSODD (Role Specified Open-Domain Diaologue) 시스템을 위한 대화생성 프레임워크
- 1) 인풋 생성
- 역할 설명서(role specification), 몇몇 대화 예시를 이용해 one-shot in-context learning을 위한 인풋 프롬프트 생성
- 2) 데이터 생성 및 필터링
- LM이 주어진 인풋을 바탕으로 데이터 생성
- 해당 데이터에 대해 사람이 직접 필터링 및 annotation 진행 (어디에서 처음 out-of-bound 발생했는지)
- 3) 모델 학습
- out-of-bounds detection(범위를 넘는 데이터 감지)
- 데이터셋의 긍정, 부정 예시를 구분할 수 있는 분류기 학습
- response selection(답변 선택)
- retriever(poly-encode)가 top-k의 가능한 답변들을 찾아내고, reranker(cross-encoder)가 답변들의 순위를 다시 매김
- thresholding을 이용해 답변할 수 없는 문맥을 파악해 최종 결정
- response generation(답변 생성)
- 긍정 데이터셋에 대해서는 maximum likelihood estimation(MLE)
- 부정 데이터셋에 대해서는 unlikelihood(UL) 학습을 통해 답변 생성 학습
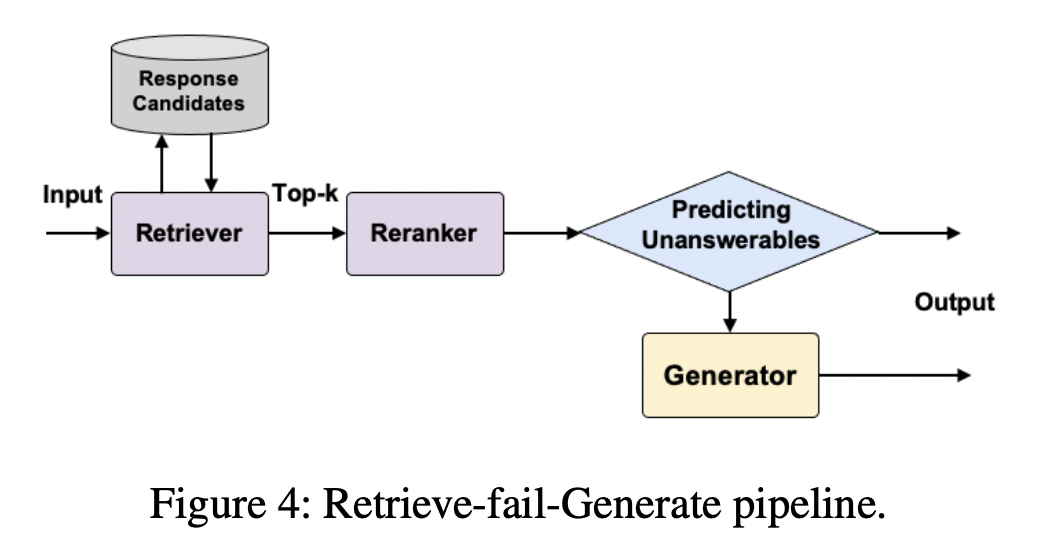
- retrieve-fail-generate(답변 선택, 실패 시 답변 생성) 파이프라인
- 답변 선택 모델이 적절한 답변을 선택
- 만약 이 과정을 실패하면 답변 생성 모델이 주어진 문맥에 맞는 답변을 생성해 리턴 (답변 선택 모델이 대부분의 답변을 담당)
- out-of-bounds detection(범위를 넘는 데이터 감지)
- 4) 평가 및 피드백
- 사람과 봇 사이의 대화 추가 수집해 데이터 증가 및 out-of-bounds 데이터 수정 (피드백 제공)
평가
- 데이터셋
- 한국어 데이터셋, 89개 주제에 대한 250개 대화 예시 활용
- 평가기준
- 답변 선택에 대해서는 Hits@1/K 활용
- 답변 생성에 대해서는 perplexity 활용
- 답변의 품질에 대해서는 SSA 사용
의의
- 특정한 태스크가 아닌 열린 주제의 대화를 자연스럽게 수행하면서도, 역할 정체성(role specification; persona, style...)을 유지하는 데이터 생성 프레임워크 제안
- 큰 규모의 언어모델(Language Model; LM)의 in-context learning 활용 방식을 제시
- 한국어 RSODD 데이터셋 공개
한계
- adversarial attack(적대적인 공격) 미고려
- 챗봇 사용자가 일반적인 질의를 진행한다고 전제하고 평가
- 사용자가 이상한 질문을 하는 등의 행동을 했을 때 성능 보장 어려움
- human filtering efficiency
- 사람이 필터링하는 과정은 사람이 직접 데이터셋을 만드는 것보다 약 13배 효율적이나, 더 효율적으로 해당 과정을 수행할 수 있는 여지 존재
- ethical considerations
- PLM은 사회적 편견, 해로운 컨텐츠 등을 포함할 수 있음 (RSODD 데이터셋 생성에 있어서는 해당 데이터들을 제외하고자 노력)
- 챗봇 시스템을 개발할 때에는 사용자의 현실도피 이용가능성/범죄 이용 가능성/개인, 민감정보 문제 등에 안전하고 도덕적으로 대응해야 함
- 개인적으로 최근 AI 분야에서 이런 fairness, ethical considerations에 대한 논의가 많아지는 추세라 관심이 많은데, 해당 부분을 상술하는데 약 1page 가량을 사용하는 것이 흥미로웠음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab