Do Language Models Have Beliefs? Methods for Detecting, Updating, and Visualizing Model Beliefs
knowledge-edit
목록 보기
10/15
Do Language Models Have Beliefs? Methods for Detecting, Updating, and Visualizing Model Beliefs
분야 및 배경지식
- model edit
- 모델이 학습한 parameter 내의 knowledge를 수정하고자 하는 방법 (implicit edit)
- retrieval이나 별도의 memory를 이용해 잘못된 지식을 수정하고자 하는 external edit 방식과 구별됨
- 언어모델이 학습한 시점과는 다른 미래의 정보에 대해 어려움을 겪으며, 틀리거나 옳지 않은(e.g.편견) 정보를 학습할 수 있다는 점에서 모델의 수정이 중요한 화두로 떠오름
- 해당 논문에선 model이 갖고 있는 knowledge를 belief라는 단어로 명명
문제점
- 기존에 제안되었던 hypernetwork (=learned optimizer) 방식인 KnowledgeEditor의 경우 한 번의 수정만 가능
- 다른 지식을 업데이트하기 위해서는 원래의 모델로 rollback 수행 후 edit 진행
- sequential(일련의, 연속적인) model edit에 대한 고려 부족
해결책
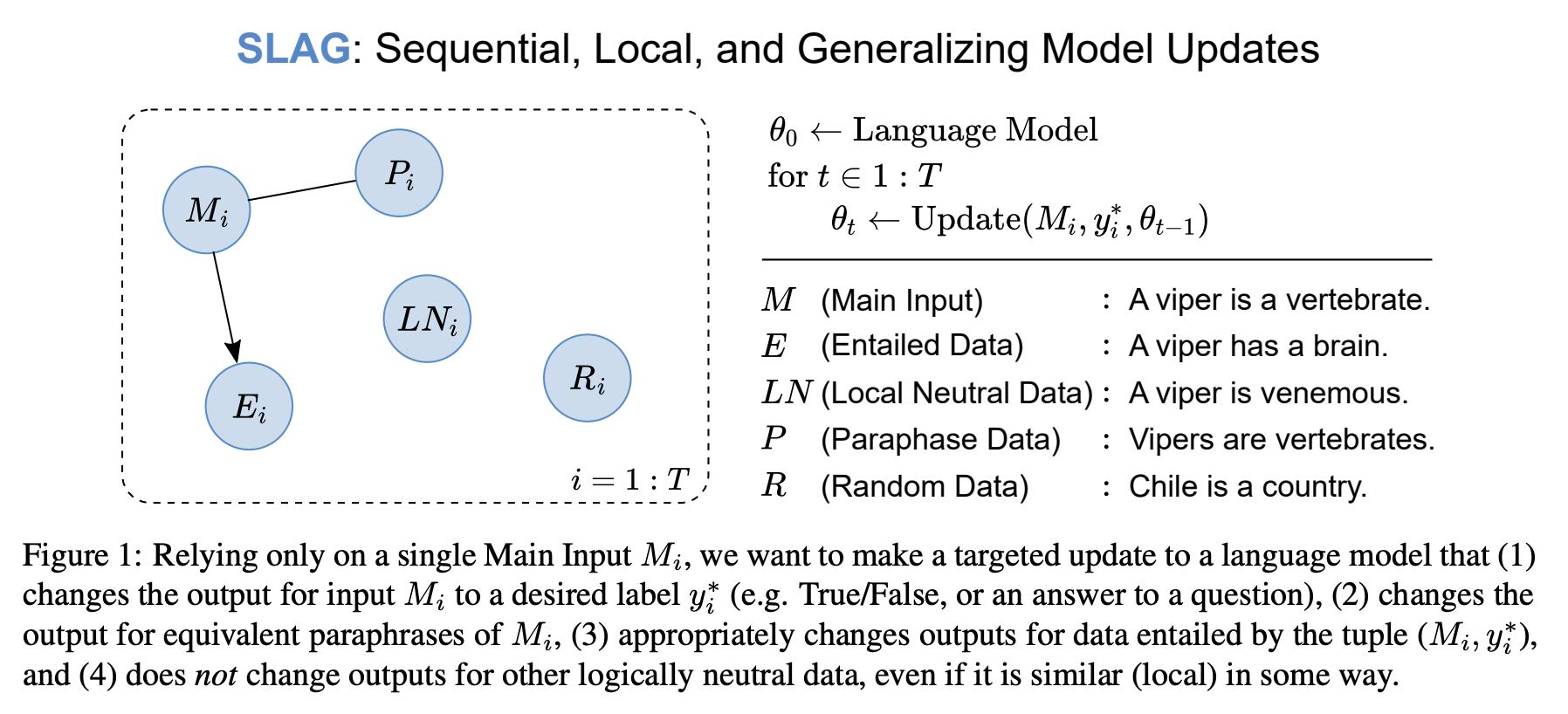
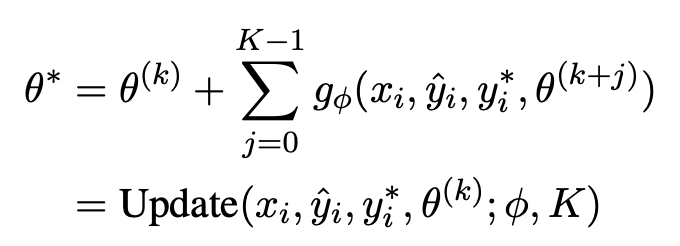
SLAG (Sequential, Local, and Generalizing Model Updates)
- KnowledgeEditor의 learned optimizer와 유사하나 발전된 형태
- 단일 지식만 업데이트할 수 있는 게 아니라 연속적으로 여러 개 업데이트 가능 (e.g. 10개)
- g는 learned optimizer, model parameter theta를 update할 때 여러 개의 knowledge에 대한 연속적인 학습도 처리할 수 있게끔 loop 상황을 가정하고 이를 objective에 반영
- 실제 데이터 레이블을 가지고 학습 진행
- sequence-to-sequence task에서 update를 위해 label을 변경할 때 모델의 예측값이 틀리다면 정답 레이블을 사용하고 그렇지 않다면 학습 데이터에서 다른 레이블을 무작위로 선택
- 기존 연구에서는 모델의 예측값과 beam search로 대체 레이블(update할 label)을 선택하였는데, 이는 쉬운 세팅임을 증명함
- We find that correcting model outputs is harder than simply changing them to a plausible alternative. ... This suggests that past work has overestimated the efficacy of belief update methods for actually fixing models
- 단일 지식만 업데이트할 수 있는 게 아니라 연속적으로 여러 개 업데이트 가능 (e.g. 10개)
평가
- 평가기준
- update success rate (main input): input에 대해 원하는(변경된) output이 나오는지
- update success rate (paraphrase): 유사한 input에 대해서도 원하는 output이 나오는지
- update success rate (entailed data): main input과 논리적으로 함의 관계에 있는 데이터들에 대한 예측이 정확한지
- 예를 들어 main input x_i가 참이라는 명제는 수반된(entailed) input x_e가 레이블 y_e를 갖고 있다는 사실을 암시
- retain rate (all data): update와 관련없는 다른 데이터들의 대한 결과가 변하지는 않았는지 (무작위 데이터)
- retain rate (local neutral): 전혀 관련없는 무작위 부분집합이 아니라 main input과 유사해 보이지만 논리적으로 관련 없는 데이터에 대해 결과가 변하지는 않았는지 (위 항목보다 어려운 상황 가정)
- 예를 들어 (subject, relation, object)가 하나의 knowledge라면 subject는 update할 것과 동일한데 relation, object가 다른 경우
- Δ-acc (all data): main input 이외의 다른 데이터들에 대해 정확도가 얼마나 변화하였는지

- 데이터셋
- zsRE, Wikidata5m, FEVER, LeapOfThought
- 모델
- RoBERTa-base (binary tasks)
- BART-base (sequence-to-sequence tasks)
한계
- 기존 연구들과 다르게 knowledge가 아니라 belief라는 단어를 선택해 사용하면서 그 이유에 대해 상세히 설명하였으나, 개인적으로는 그다지 설득력 있게 들리지 않음
- optimizer 학습을 위해 main input, paraphase, entailment, local neutral, retain 등 평가 기준에 사용되는 모든 데이터셋에 대한 loss를 결합, novelty 부족
- training objective에 대한 ablation이 있으나 단순히 실험 결과 나열에 불과 (관계성, 포함 이유, 상호간의 관계 등에서는 자세한 고찰 없음)
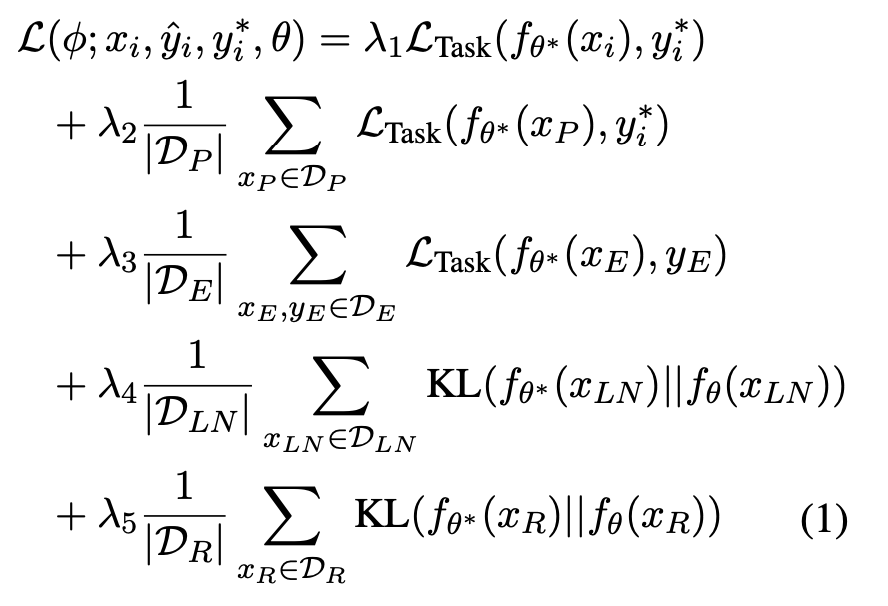
- training objective에 대한 ablation이 있으나 단순히 실험 결과 나열에 불과 (관계성, 포함 이유, 상호간의 관계 등에서는 자세한 고찰 없음)
- model edit은 모델에 잘못된 지식을 주입할 수 있는 ethical concern이 존재
의의
- off-the-shelf optimizer가 잘 튜닝된다면 기존에 제안되었던 hypernetwork (learned optimizer) 방식인 KnowledgeEditor보다 더 좋은 성능을 보일 수 있음을 밝힘
- 다른 baselinee들을 상회하는 연속적인 model edit을 위한 새로운 objective 제시 (SLAG)
- 다양한 실험을 통한 흥미로운 결과 제시
- retain rate는 데이터에 대한 예측이 옳은지 여부에 크게 영향을 받음
- 옳지 않은 예측은 모델의 업데이트에 굉장히 민감
- local neural belief가 단순히 랜덤 데이터에 비해 변화를 피하기 어려움
- retain rate는 데이터에 대한 예측이 옳은지 여부에 크게 영향을 받음
- belief graph를 통해 모델이 가지고 있는 믿음 사이의 관계성 파악
- 몇몇 belief는 많은 belief들의 변화에 민감 (쉽게 변화 가능)
- 몇몇 belief는 변화할 시 많은 수의 belief에 영향을 미침
- A를 업데이트할 때 B가 변화하고, B를 업데이트할 때 C가 변화하면 A가 업데이트할 때 C가 변화해야 하는데, 이러한 transitivity(타동성)은 쉽게 일어나지 않음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab