배경지식
- 추론 (Reasoning)
- 단순한 태스크를 넘어, 일반적으로 수학, 과학 등 고난이도의 태스크를 해결하기 위해 필요한 심도 있는 사고(think) 능력
- 일반적으로 reasoning이 가능한 모델들은 더 많은 생성 토큰을 소모함
- 한국어로 번역할 때는 일반적인 생성인 inference와 동일하게 번역되나, 그 뜻이 다름에 유의
- 해당 글에서는 의미의 차이를 명시하게 위해 reasoning, inference로 표기 예정
- 단순한 태스크를 넘어, 일반적으로 수학, 과학 등 고난이도의 태스크를 해결하기 위해 필요한 심도 있는 사고(think) 능력
- 테스트 시점 스케일링 (test-time scaling)
- 학습 단계가 아닌, inference 시 더 많은 연산을 수행해 성능을 높이는 방식
- 모델에게 사고를 요구하거나, 자기 반성(self-reflection)을 요구하거나, 여러 번의 추론 후 가장 좋은 응답은 선택하는 등의 방식이 사용됨
- 자기 일관성 (self-consistency)
- reasoning을 여러 번 수행하고, 다수결(majority voting)을 통해 최종 정답을 취합하는 방식
- 병렬 사고(parallel thinking) 방식이라고도 칭함
문제점
- 자기 일관성 방식의 한계
- reasoning 트레이스의 개수가 늘어날수록 성능이 포화되거나 저하
- 모든 reasoning 트레이스를 동일하게 취급, 품질 차이를 무시
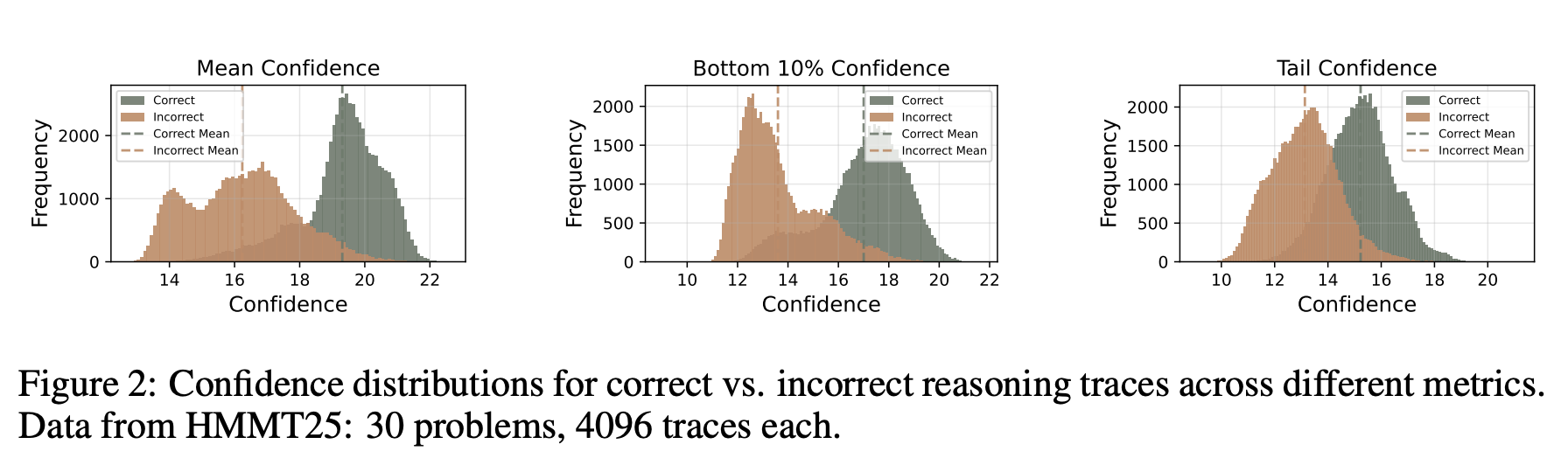
- 전역 신뢰도 측정 (global confidence measure) 방식의 한계
- 최근 논문들에 따르면, 다음에 올 토큰 예측(next-token prediction)의 분포를 활용하여 reasoning 트레이스의 품질을 평가할 수 있다고 함
- 더 높은 예측 신뢰도는 낮은 엔트로피, 즉 감소된 불확실성을 의미
- 다시 말해, 모델이 예측한 다음 토큰의 확률(=신뢰도)이 높다면 모델이 정답을 말할 가능성이 높다는 것임 (불확실성과 오답 사이 상관성 존재)
- 하지만 생성된 reasoning 트레이스 전체에 대한 전역 신뢰도 측정은
- 1) 국지적인 추론 단계에서의 신뢰도 변동을 제대로 측정할 수 없으며,
- 2) reasoning 트레이스 전체 생성이 완료되어야만 계산이 가능하다는 한계 존재
해결책
Deep Think with Confidence
신뢰도 측정 방식
- 그룹 신뢰도 (Group Confidence)
- reasoning trace를 중복되는 범위(span)로 나눠 이에 대한 신뢰도를 측정
- 더 국지적인(localized) 시그널 측정 가능
- 굉장히 낮은 신뢰도를 보일 경우 최종 응답의 정답 유무에 영향을 미침
- e.g. wait, however, think again 등의 신뢰도가 낮은 토큰
- 최하 10% 그룹 신뢰도 (Bottom 10% Group Confidence)
- 그룹 신뢰도 중 최하 10%의 신뢰도를 보이는 그룹만을 활용
- 최저 그룹 신뢰도 (Lowest Group Confidence)
- 그룹 신뢰도 중 가장 낮은 신뢰도를 보이는 그룹만을 활용
- 꼬리 신뢰도 (Tail Confidence)
- trace의 가장 마지막 부분(e.g. 최종 2048 토큰)의 신뢰도를 활용
오프라인 신뢰도 측정
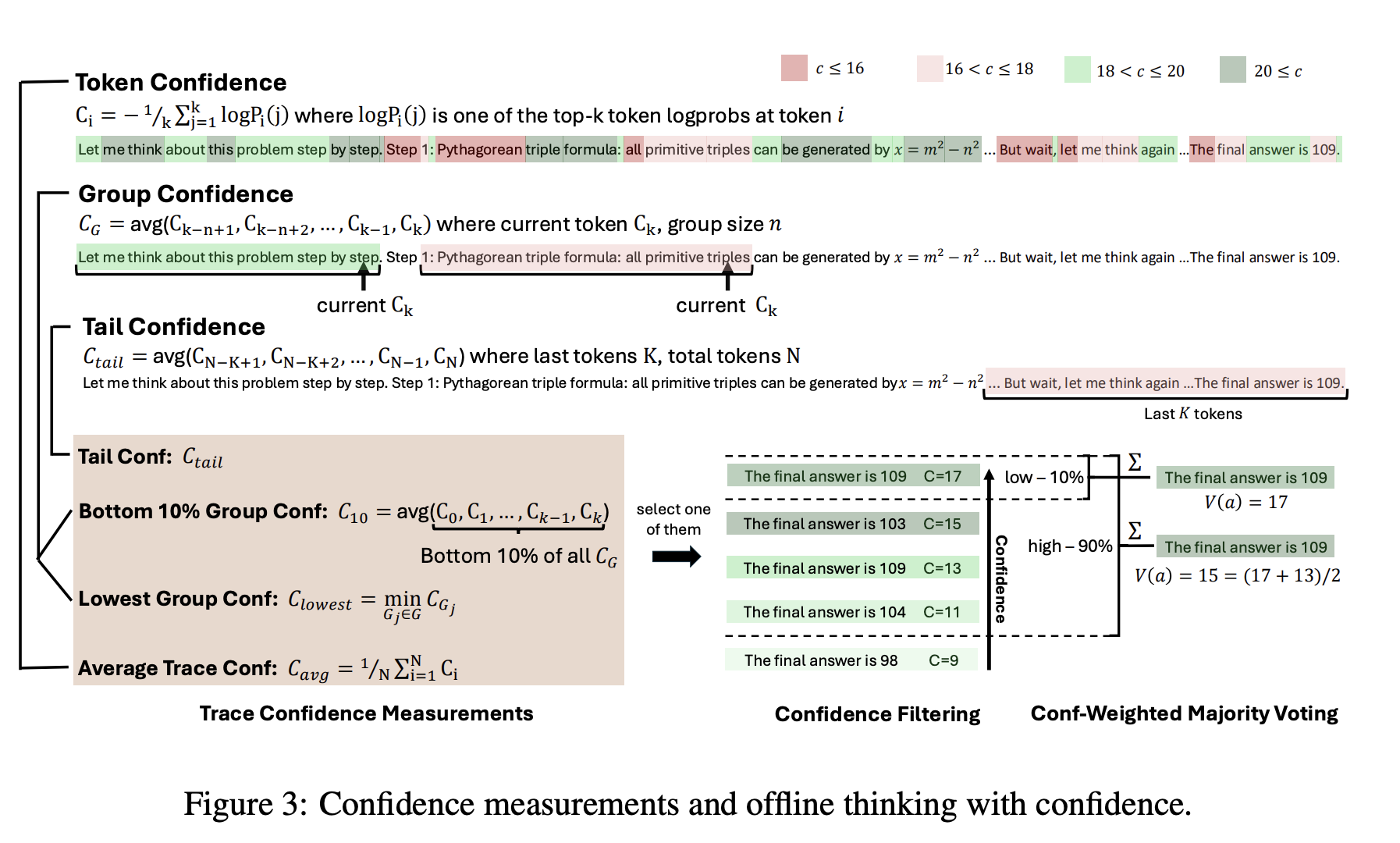
- 오프라인 신뢰도 측정이란, 생성이 완료된 reasoning trace 기반으로 신뢰도를 측정하는 방식
- 다수결 (Majority Voting)
- 여러 개의 reasoning trace 중 가장 많이 정답으로 뽑힌 응답을 선택
- 신뢰도 가중치 기반 다수결 (Confidence-Weighted Majority Voting)
- 연관된 trace의 신뢰도를 가중치로 부여 후 다수결 선택
- 신뢰도 기반 필터링
- 신뢰도를 기반으로 상위 10% 혹은 상위 90% 필터링
- 신뢰도 가중치 기반 다수결과 신뢰도 기반 필터링을 함께 적용
온라인 신뢰도 측정
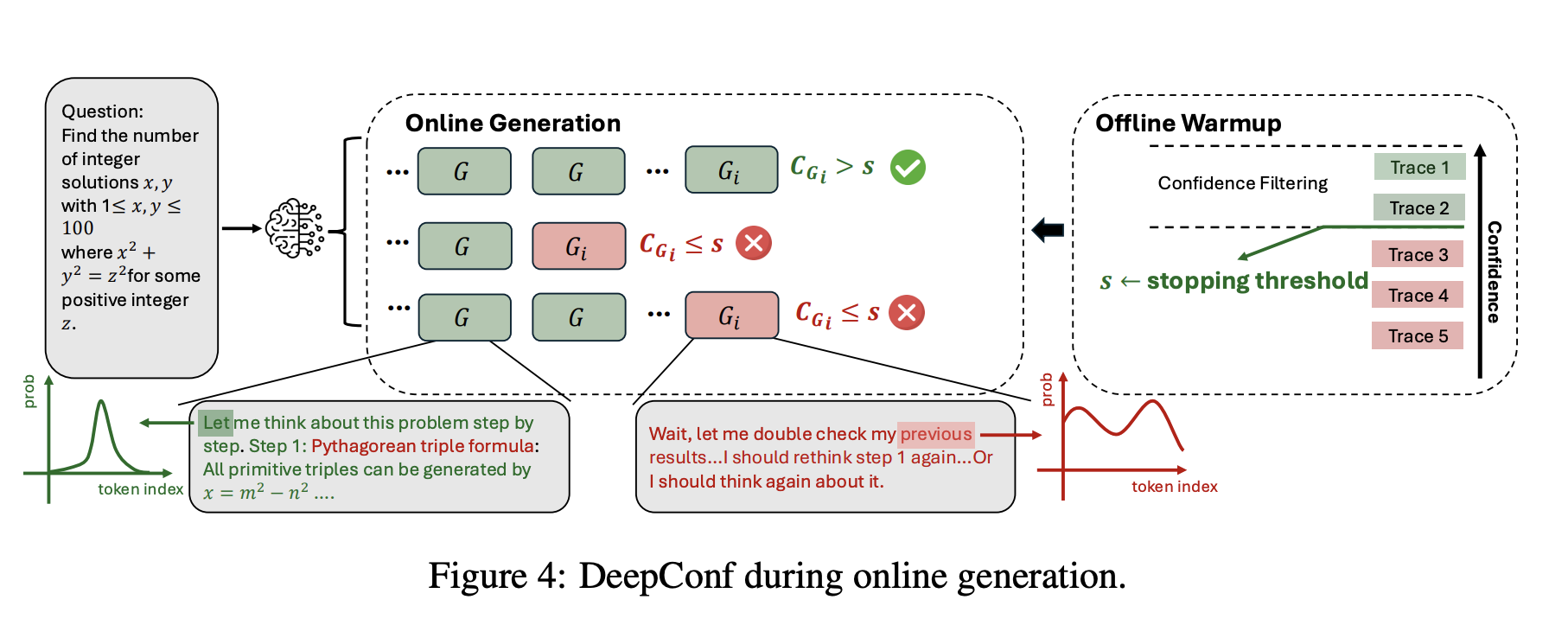
- 온라인 신뢰도 측정이란, 모델이 실시간으로 생성하는 reasoning trace를 기반으로 신뢰도를 측정하는 방식
- 자원이 제한적이거나, 빠른 응답이 필요할 때 유용
DeepConf-low, DeepConf-high
- 실시간 필터링
- 최저 그룹 신뢰도를 기반으로 생성 중 응답을 멈춤 (일종의 필터링)
- 오프라인 웜업 (Offline Warmup)
- 응답 생성을 언제 멈출지 중단 임계값(stopping threshold)을 지정하기 위해 오프라인 웜업 시행
- N_init(e.g. 16)개의 생성이 완료된 reasoning trace를 대상으로 임계값 지정
- DeepConf-low는 상위 10%, DeepConf-high는 상위 90% 활용
- 트레이스 버짓 조정
- 적응 표본 샘플링 (Adaptive Sampling)
- 문제 난이도에 따라 생성하는 트레이스의 수를 동적으로 조정
- 난이도는 생성된 트레이스 중 합의(consensus)된 개수로 측정
- 적응 표본 샘플링 (Adaptive Sampling)
평가
- 모델
- 오픈소스 Reasoning 모델 활용
- DeepSeek-8B, Qwen3-8B, Qwen3-32B, GPT-OSS-20B, GPT-OSS-120B
- 평가 벤치마크
- 고난이도 수학: AIME24, AIME25, BRUMO25, HMMT25
- 대학원 수준 STEM: GPQA
- 비교 베이스라인
- 자기 일관성 (다수결) 방식
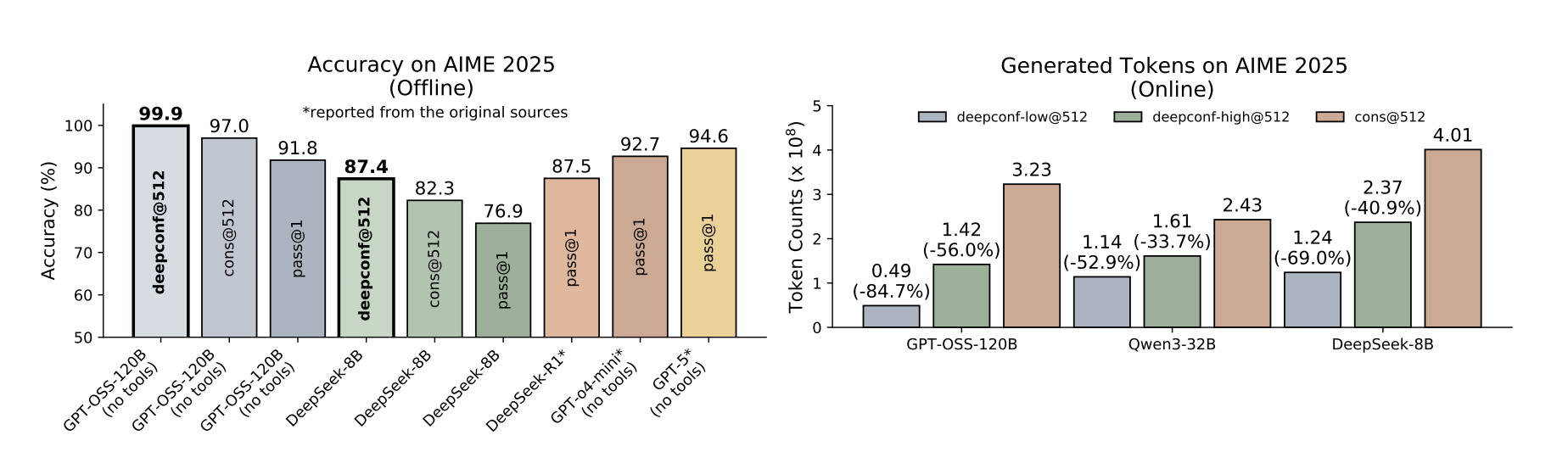
- 오프라인 신뢰도 평가
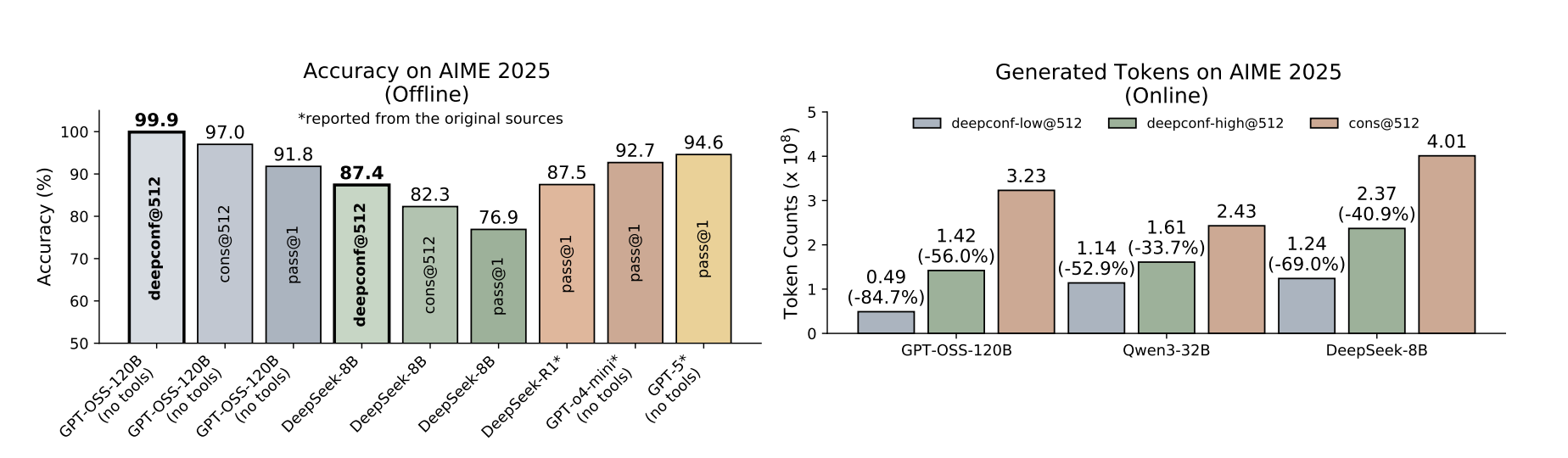
- 베이스라인 대비 성능 향상
- 필터링 시, 상위 10%만 사용하는 것보다 보수적으로 상위 90%를 사용하는 것이 안전
- 온라인 신뢰도 평가
- 베이스라인 대비 정확도는 유사
- 베이스라인 대비 DeepConf-low는 약 43-79%의 토큰 절약, DeepConf-high는 약 18-59%의 토큰 절약
한계
- 불확실성과 모델 응답의 정확성 사이 상관성이 존재하나, 여전히 모델이 높은 확신을 가지고 오답을 생성하는 경우 존재함
- 기본적으로 다수결을 기반으로 하는 연구 방식으로, 베이스라인 대비 토큰을 절약했다고 하나 여전히 많은 연산량을 요구
- production-level 적용의 어려움
참고
- 논문: Deep Think with Confidence (link)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab