EXAONE 3.5: Series of Large Language Models for Real-world Use Cases (Report link, HuggingFace Model Hub, Demo)
Technical Report 이해에 도움이 될 배경지식
- 모델 configuration 관련
- SwiGLU (관련 논문)
- Swish의 부드러운 비선형성과 GLU의 게이팅 특성을 결합한 활성함수
- LLaMA와 같은 대규모 언어모델에서 우수한 성능 입증
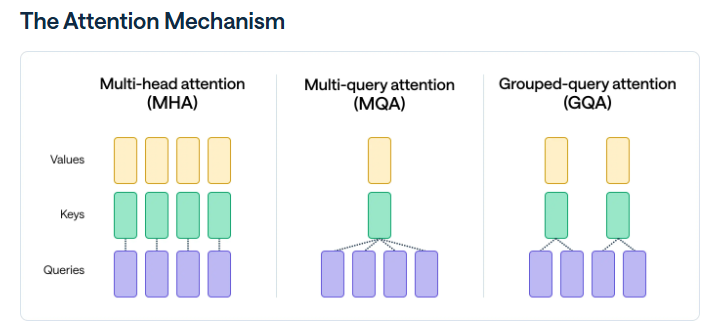
- GQA (Grouped Query Attention)
- 유사한 attention head를 묶어 메모리 로드를 줄이면서도 텍스트 내의 복잡한 관계성이나 패턴을 유지하는 방식 (참고 링크)
- RoPE theta
- RoPE란, Rotary Position Embedding의 약자로 고차원 공간에서 토큰 임베딩을 회전시킴으로써 효과적으로 상대적 위치 관계를 인코딩하려는 방식 (참고 링크)
- theta는 RoPE에서 위치 인코딩을 위한 중요한 하이퍼파라미터
- Tied Word Embedding
- 임베딩 가중치(vocab size X hidden size)가 디코더(hidden size X vocab size)와 엮여있어 하나의 행렬만 학습하도록 하는 임베딩 방식 (참고 링크)
- SwiGLU (관련 논문)
- 사전학습 관련
- catastrophic forgetting
- 모델이 연속해서 학습을 진행하면서, 이전에 배운 지식을 까먹는 현상
- continual learning 분야에서 지속적으로 연구되어 온 분야
- 이전에 학습한 데이터의 일부를 이후 학습에 다시 활용하는 replay 방법론을 포함해 여러 방법론이 존재
- catastrophic forgetting
EXAONE 3.5 개요
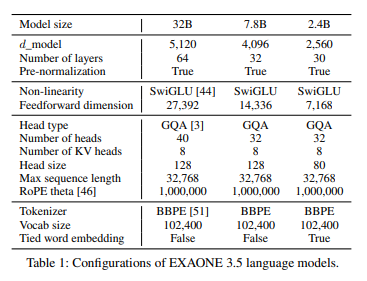
- 2.4B, 7.8B, 32B의 세 가지 크기 모델 제공
- 7.8B와 32B의 경우 Real-World Use case, Long Context 벤치마크에서 우수한 성능
- 2.4B의 경우 General Domain 벤치마크에서 뛰어난 성능
- 32K 토큰까지 처리 가능 (긴 문맥; long context 처리 가능)
- 유사한 크기의 다른 모델들 대비 학습 비용이 낮음
- Exaone 3.5 32B: 학습 토큰 6.5T
- Qwen 2.5 32B: 학습 토큰 18T
- Gemma 2 27B: 학습 토큰 13T
모델 학습
사전 학습 (Pre-training)
- 거대한 학습 코퍼스로 1차 사전학습 진행
- 평가 후 강화가 필요한 도메인의 데이터를 수집해 2차 사전학습 진행
- 2차 사전학습 시 긴 문맥 처리 능력을 강화하기 위한 long-context fine-tuning 활용
- 1차 사전학습 단계에서 사용한 데이터의 일부를 활용해 replay 기반 방법론을 도입, catastrophic forgetting 방지
- 학습 시 벤치마크 테스트 데이터셋이 사용되는 것을 방지하기 위해, decontamination 진행
- 단순한 substring-level matching 방식을 활용
사후 학습 (Post-training)
지도 파인튜닝 (Supervised Fine-tuning)
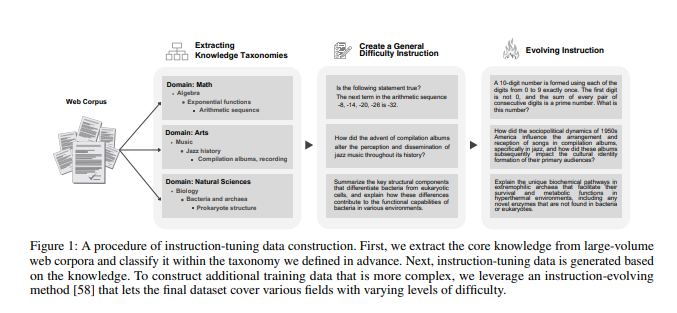
- 분류 시스템(taxonomic system)을 활용해 8M 웹 코퍼스에서 핵심 지식 추출
- 추출된 지식을 기반으로 instruction-tuning 데이터셋 생성
- 다양한 복잡도를 가진 instruction 생성
선호 최적화 (Preference Optimization)

- 사람의 선호를 학습하기 위해, DPO, SimPO와 같은 Direct alignment algorithm (DAA) 활용
- 가상(synthetic) 데이터 및 사전에 수집한 데이터 활용해 선호 데이터셋 생성
- 여러 모델들을 활용해 N개의 답변을 샘플링
- reward model을 활용해 최고 답변과 최악 답변을 선정
- 추가적인 reward model을 활용해 두 개의 reward model이 결정한 순위 사이의 일관성(agreement)을 확인한 후 threshold를 넘지 못한다면 해당 데이터 제외
모델 평가
Real-world Use Case
- 다양한 사용자 지시사항을 이해하고 수행할 수 있는지를 판단
- MT-BENCH, KOMT-BENCH, LOGICKOR (멀티턴)
- ARENA-HARD, ALPACAEVAL (GPT-4와 같은 기준 모델과 평가할 모델 사이의 답변 비교)
- LIVEBENCH, IFEVAL (ground-truth 정답과 모델 답변 비교)
Long Context (긴 문맥)
- 긴 문맥을 이해하는 능력을 판단
- Needle-in-a-Haystack
- 긴 문서 내에 무작위적 위치에 숨어있는 정보를 모델이 잘 찾아내서 검색하는지 여부 판단
- LONGBENCH, LONGRAG, KO-LONGRAG
General Domain (일반 도메인)
- 수학 문제: GSM8K (CoT), MATH (CoT)
- 코드 작성: HUMANEVAL (Evalplus base), MBPP (Evalplus base)
- 파라미터 지식: MMLU (CoT), KMMLU (CoT), GPQA (CoT), ARC-C, BBH (CoT)
책임감있는 AI
- 데이터 거버넌스, 윤리적 고려사항, 리스크 관리 등 Responsible AI를 위한 원칙 준수

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab