Qwen2.5 Technical Report (report link)
Qwen 2.5 개요
- Open-weight (공개) 모델
- 7개 사이즈의 dense model
- 0.5B, 1.5B, 3B, 7B, 14B, 32B, 72B
- 다양한 precision
- bfloat16의 원본 모델
- 다양한 precision의 양자화(quantized) 모델
- 7개 사이즈의 dense model
- Proprietary (독점, 미공개) 모델
- Mixture-of-Experts 모델
- Qwen2.5-Turbo, Qwen2.5-Plus
- 특화 모델
- Qwen2.5-Math, Qwen2.5-Coder, QwQ, 멀티모달 모델
- 사전학습, 사후학습 데이터 개선
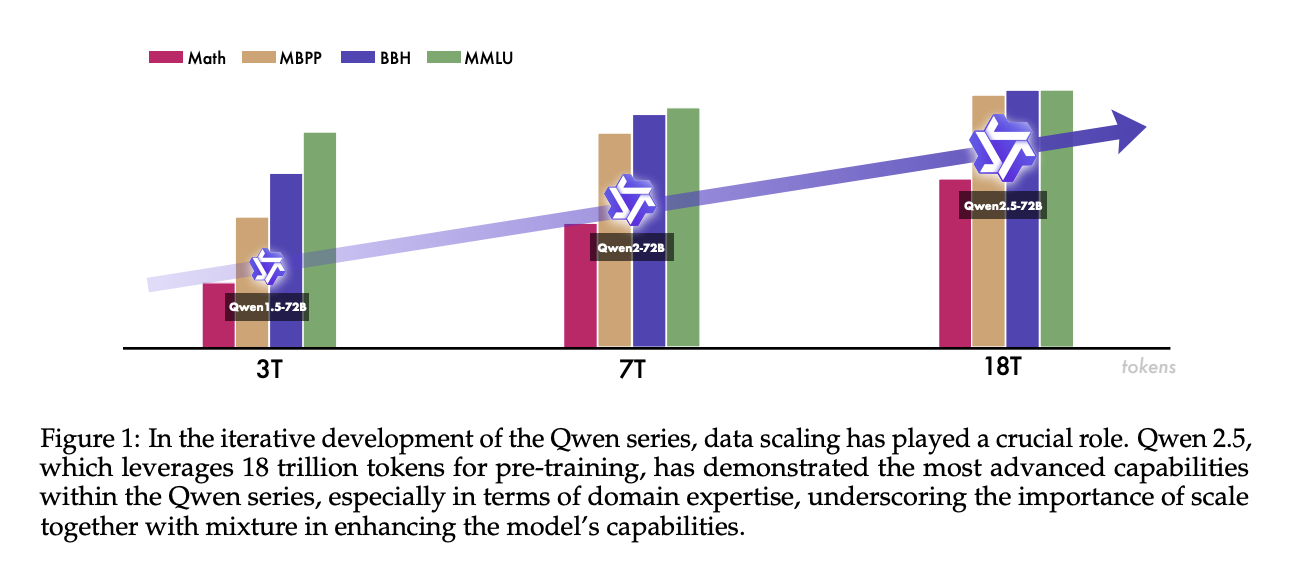
- 사전학습 시 18조 (18trillion) 개의 토큰 사용
- 지식, 수학, 코딩에 중점
- 사후학습 시 백만 (1 million) 개의 예시 사용
- 사전학습 시 18조 (18trillion) 개의 토큰 사용
- 개선된 사용성
- 생성 길이 8k 토큰으로 증가
- Qwen2.5-Turbo의 경우 백만 토큰 context length 지원
- 구조화된 인풋, 아웃풋 지원 개선 (e.g. 표, json)
- 도구 사용 개선
- 생성 길이 8k 토큰으로 증가
모델 아키텍처 및 토크나이저
아키텍처
- Open-weight 모델 (dense)
- Grouped Query Attention
- 효율적인 KV 캐시 사용을 위함
- SwiGLU activation
- Rotary Positional Embeddings
- QKV bias, RMSNorm
- 안정적인 학습을 위함
- 관련한 배경지식은 해당 링크에서도 다룬 바 있음
- Grouped Query Attention
- Mixture-of-Experts 모델
- 일반적인 feed-forward network(FFN)를 특별한 MoE 레이어로 대체
- 각 레이어는 여러 개의 FFN 전문가와 top-K 전문가에게 토큰을 보내는(dispatch) 라우팅 메커니즘으로 구성됨
- fine-grained expert segmentation과 shared experts routing 활용
- 일반적인 feed-forward network(FFN)를 특별한 MoE 레이어로 대체
토크나이저
- byte-level byte-pair encoding 활용한 Qwen 토크나이저 활용
사전학습 (pre-training)
사전학습 데이터
- 데이터 필터링
- Qwen2-Instruct 모델을 데이터 품질 필터로 활용
- 수학 및 코딩 데이터
- Qwen2.5-Math, Qwen2.5-Coder의 학습 데이터들을 Qwen2.5 모델 학습에도 활용
- 가상 데이터
- Qwen2-72B-Instruct, Qwen2-Math-72B-Instruct를 활용해 고품질의 가상 데이터 생성
- Qwen 내부적으로 확보한 일반적인 보상 모델과 특화된 Qwen2-Math-RM-72B 모델을 활용해 데이터 필터링
- 데이터 혼합
- Qwen2-Instruct 모델을 활용해 다른 도메인을 분류
- 데이터 양이 많은 이커머스, 소셜 미디어, 엔터테인먼트 분야 데이터 다운샘플링
- 데이터 양이 부족한 기술, 과학, 학계 연구 분야 데이터 업샘플링
하이퍼 파라미터를 위한 Scaling Law
- 배치 사이즈, 학습률(learning rate) 등 주요한 학습 파라미터들을 결정할 때 스케일링 법칙 활용
- 사전학습 데이터셋 크기 D, 모델 사이즈 N이 달라짐에 따라 최적의 학습률, 배치사이즈가 어떻게 달라지는지 분석
긴 문맥(long-context) 사전학습
- 두 단계의 사전학습 진행
- 처음에는 4,096 토큰 컨텍스트 길이 학습
- 두 번째는 32,768 토큰 컨텍스트 길이 학습 (Qwen2.5-Turbo 제외)
- RoPE의 base frequency를 10,000에서 1,000,000로 증가 (ABF 활용)
- Qwen2.5 Turbo의 경우 4번에 걸쳐 점진적으로 컨텍스트 길이 확장
- 32,768 -> 65,536 -> 131,072 -> 262,144 토큰
- RoPE base frequency 10,000,000
- 학습 시 40% 문장은 최대 길이로, 나머지 60%는 더 짧은 문장들로 구성
- 추론 시 더 긴 문장을 처리하도록 2가지 전략 도입
- YARN, Dual Chunk Attention
- Qwen2.5-Turbo가 최대 백만 토큰, 다른 모델들은 최대 131,072 토큰 처리 가능
사후학습 (post-training)
지도 파인튜닝 (Supervised Fine-tuning)
- 고품질의 지도 파인튜닝 데이터셋 확장
- 총 백만 개가 넘는 SFT 데이터셋 확보
- 이전 모델의 한계 보완
- 긴 문장 생성
- 아웃풋 컨텍스트 길이를 8,192 토큰까지 확장
- 긴 응답 데이터셋 생성
- 사전학습 코퍼스에서 긴 텍스트 데이터를 위한 쿼리를 생성 (back-translation 활용)
- 아웃풋 길이 제한을 부여
- Qwen2를 활용해 저품질 데이터를 필터링
- 수학
- Qwen2.5-Math의 chain-of-thought 데이터 도입
- rejection sampling, reward modeling, annotated answers 등 활용
- 코딩
- Qwen2.5-Coder의 instruction tuning 데이터 도입
- 여러 개의 언어 특화 에이전트 활용해 데이터 생성
- 코드 관련된 QnA 웹사이트로부터 새로운 예시를 합성하거나, GitHub에서 알고리즘 코드 스니펫을 모아 데이터셋을 확장
- 자동화된 단위 테스트 등을 통해 데이터 품질 검수
- 지시사항 준수 (instruction following)
- LLM이 지시사항과 이에 상응하는 검증 코드, 교차 검증을 위한 통합적 단위 테스트 생성
- 실행 피드백 기반의 rejection sampling을 통해 데이터 선정
- 구조화 데이터 이해
- 테이블 QnA, 사실 검증, 오류 수정, 구조적 이해 등 전통적인 태스크 및 구조화/반구조화 데이터를 포함한 복잡한 태스크를 위한 데이터셋 개발
- 모델의 응답에 추론 체인을 포함
- 논리적 추론
- 다양한 도메인을 포함하는 7만 개의 새로운 쿼리
- 다지선다, 참/거짓, 개방형 질문 등
- 연역, 귀납, 유추, 인과, 통계적 추론 등 다양한 추론 방식 활용
- 다양한 도메인을 포함하는 7만 개의 새로운 쿼리
- 언어 간 전환 (cross-lingual transfer)
- 자원이 풍부한 (high-resource) 언어의 지시사항을 번역 모델을 활용해 자원이 부족한 언어로 번역
- 지시사항에 상응하는 후보 답변 생성
- 원래 응답과 다국어 응답 사이의 의미적 유사성이 잘 align되었는지를 평가
- 강건한 시스템 지시사항
- 사후 학습 시 시스템 프롬프트의 다양성을 개선하기 위해 수백 개의 시스템 프롬프트 생성
- 응답 필터링
- critic model, 멀티 에이전트 평가 시스템 등 자동화된 평가 시스템 활용
오프라인 강화학습
- 일반적인 정답이 있으나 보상 모델이 평가하기 어려운 태스크에 초점
- e.g. 수학, 코딩, 지시사항 준수, 논리적 추론
- 품질 기준을 통과하면 긍정적 예시, 그렇지 않으면 부정적 예시로 취급해 DPO (Direct Preference Optimization) 학습
- SFT 모델을 활용해 새로운 쿼리 셋에 대한 응답을 리샘플링하고, 실행 피드백과 정답 매칭과 같은 전략을 품질 기준 파이프라인에 활용
- 약 15만 개 학습 데이터 확보
온라인 강화학습
- 윤리적, 사용자 중심적 기준에 부합하는지 여부에 초점
- 진실한가 (Truthfulness)
- 사실적으로 정답인지
- 제공된 문맥과 지시사항을 잘 반영하는지
- 도움이 되는가 (Helpfulness)
- 사용자에게 유용한지
- 사용자의 쿼리에 대해 관련이 있고, 교육적이며, 긍정적인 내용을 제공하는지
- 간결한가 (Conciseness)
- 불필요한 내용 없이 초점에 맞게 응답하는지
- 관련성이 높은가 (Relevance)
- 사용자의 질문, 대화 기록, 어시스턴트의 문맥 등과 직접적으로 관련이 있는지
- 해를 끼치는가 (Harmlessness)
- 불법이거나, 도덕적으로 문제가 있거나, 해로운 행동을 유발하는 내용을 제외하고 있는지
- 편견은 없는가 (Debiasing)
- 성별, 인종, 국가, 정치 등 편견으로부터 자유로운지
- 오픈소스 데이터 및 내부적으로 확보한 쿼리에 대해 Qwen 모델들로 응답 생성
- 여러 체크포인트, 여러 학습 단계 (SFT, DPO, RL)의 모델 사용
- temperature도 다양하게 활용
- 사람과 자동화 방식을 활용해 선호 데이터셋 생성
- DPO 학습 시 사용되었던 데이터들도 함께 사용
- Group Relative Policy Optimization (GRPO)로 학습
긴 문맥 파인튜닝 (Long Context Fine-tuning)
- Qwen2.5-Turbo 문맥 확장을 위해 더욱 긴 SFT 데이터셋 도입
- 첫 번째 단계에서는 최대 32,768 토큰을 갖는 짧은 지시사항 활용
- 두 번째 단계에서는 짧은 지시사항, 긴 지시사항 모두 활용
- RL 단계에서는 짧은 지시사항만을 활용
- 긴 문맥에 대해서 RL 학습은 연산 비용이 높음
- 긴 문맥의 태스크에 대해 적절한 보상 시그널을 제공하는 보상 모델의 부재
평가
- 평가 태스크, 베이스라인 모델들이 굉장히 많아서 궁금한 부분이 있다면 논문을 참고하기를 추천
- 사전학습 모델에 대해서는 일반, 수학 및 과학, 코딩, 다국어에 대해 성능 측정
- Instruction 튜닝 모델에 대해서는 아래에 대해 성능 측정
- 벤치마크 데이터셋 (일반, 수학 및 과학, 코딩, 지시사항 준수, 사람 선호 일치(align) 여부 등)
- 내부 데이터셋 (지식 이해, 문장 생성, 코딩 (영어, 중국어))
- 보상 모델에 대해서도 평가 진행
- 긴 문맥 능력에 대해서도 평가 진행
- 몇 가지 강조하는 내용만 요약하자면,
- Qwen2.5-72B-Instruct 모델이 Llama-3-405B-Instruct 모델과 유사한 성능 (5배 작음에도)
- Qwen2.5-Turbo, Qwen2.5-Plus는 각각 GPT-4o-mini, GPT-4o와 상응하는 성능 보임
- Qwen2는 물론 비슷한 크기의 다른 Open-weight 모델 대비 우수한 성능

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab