Editable Neural Networks
ICLR 2020
분야 및 배경지식
- Meta-learning
- 특정한 머신러닝 셋업을 위해 적절한 학습 알고리즘을 만들어내는 방법
- 효과적인 패칭을 배움 (learn to allow effective patching)
- Adversarial training
- 적대적인 공격을 막기 위한 방법(adversarial attack defense) 중 하나
- 특정한 input의 변화(perturbation)에 강건한 모델을 학습하는 것이 목표
- 이 논문에서 제시하는 학습방법은 adversarial training과 유사점이 있으나, 몇몇 샘플들에 대한 예측이 효과적으로 수정될 수 있도록 모델을 학습시킨다는 점에서 주요한 차이가 존재
문제
- 인공지능 모델의 사용도와 신뢰가 높아질수록, 모델이 발생시키는 오류는 심각한 비용을 초래
- 단일 input의 예측이 전체 모델 파라미터에 의존하기 때문에, 예측을 바꾸기 위해 파라미터를 업데이트하는 것은 다른 input의 성능을 떨어뜨릴 수도 있음
해결책
Editable Training
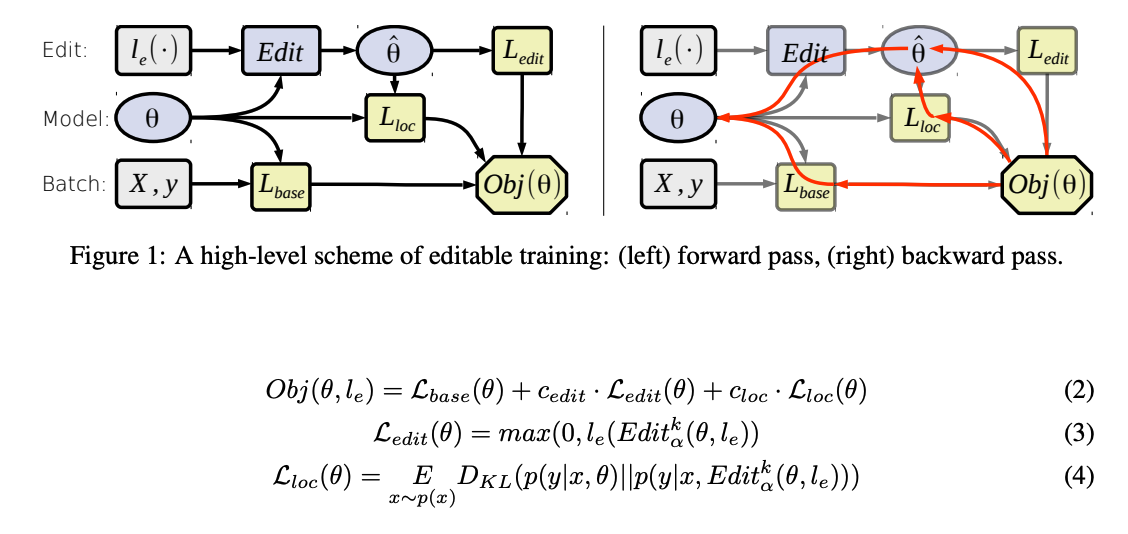
- 특정 모델에 국한되지 않는(model-agnostic) 학습 기법
- 학습된 모델의 빠른 수정을 가능케 하도록 meta-learning
- 에디터 함수(editor function)
- gradient descent 사용
- 핵심은 에디터 함수가 원하는 부분을 잘 수정하고, 수정이 이루어지지 않는 부분에 대해서 영향도를 최소화하며, 효율적일 수 있도록 파라미터를 학습하는 것(The core idea is to enforce the model parameters to be prepared for the editor function)
- L base: 특정 태스크에 대한 목적함수
- L edit: k번의 gradient step 내로 신뢰할 수 있고 효율적인 수정을 가능케 함
- L loc: 본래의 모델과 수정한 모델의 예측 사이의 KL divergence를 최소화
평가
- 평가지표
- Drawdown
- 수정을 가하기 전/후에 대한 분류 오류의 평균절대편차 (mean absolute difference of classification error before and after performing an edit)
- Success Rate
- 10번의 gradient step 내에서 editor가 성공한 비율
- Num Steps
- 단일 수정을 진행할 때 필요한 gradient step의 평균
- Drawdown
- 태스크 및 데이터셋
- ILSVRC 이미지 분류
- ImageNet, Natural Adversarial Examples
- 독일어-영어 번역
- IWSLT 2014
- ILSVRC 이미지 분류
의의
- 미분가능한 목적함수를 최소화하는 모델에 국한되지 않는(model-agnostic)한 학습 기법
- 이미지, 자연어 태스크에 범용적으로 적용 가능
- c edit, c loc의 경우 충분히 작더라도 main training objective에 deterioration을 야기하지 않으며, editor function의 성능을 증진시킴
한계
- 이미지 태스크에 비해 자연어처리 태스크에 대한 분석 비중이 현저히 적음
- 번역 태스크에서 제시한 평가기준이 실제 사람이 느끼기에도 훌륭한 품질을 보장할 수 있는가?

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab