Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
parameter-efficient-finetuning
목록 보기
7/7
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning
NeurIPS 2022
분야 및 배경지식
- in-context learning (=ICL)
- gradient를 이용한 학습 없이 몇 개의 예시를 input에 넣음으로써 이전에 학습하지 않은 태스크를 해결하는 방식
- 모델이 사전학습 시 얻은 능력에 기반, 하나의 모델로 다양한 태스크를 수행할 수 있음
- input의 길이가 늘어나기 때문에 모델이 예측을 수행할 때마다 비용이 증가
- 프롬프트의 형태가 태스크의 성능에 영향을 미치며, 파인튜닝 대비 성능이 좋지 않음
- parameter-efficient fine-tuning (=PEFT)
- 적은 수의 추가된 혹은 선택된 파라미터를 학습하는 방식
- e.g. adapter, prompt tuning, prefix tuning, lora, ...
문제점
- ICL은 새로운 태스크를 수행하기 위해 PEFT 대비 더 많은 저장용량과 연산 비용을 필요로 함
해결책
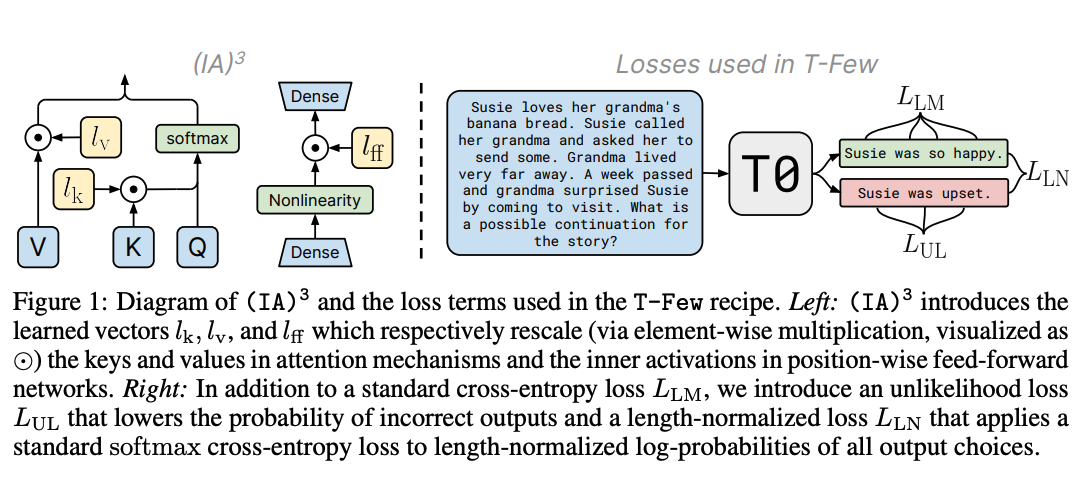
T-Few
unlikelihood training and length normalization
- 언어모델의 few-shot finetuning 성능을 높이고자 두 가지 추가적인 loss term 도입
- unlikelihood training
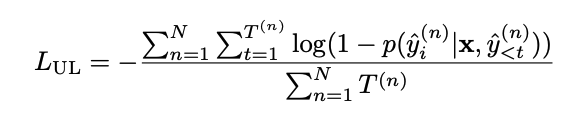
- 모델이 정확하지 않은 선택지에 대해 낮은 확률을 할당하도록 학습하는 방식
- length normalization
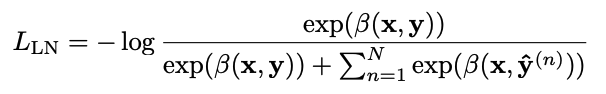
- 각각의 선택지를 확률에 기반하여 순위를 나누면 짧은 선택지를 선호할 수 있기 때문에 정규화 도입
(IA)^3
- Infused Adapter by Inhibiting and Amplifying Inner Activations
- 모델의 일부에 learned rescaling vector (l)를 도입하여 PEFT 수행
- self-attention의 key, value
- encoder-decoder attention의 key, value
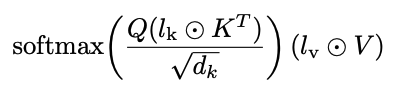
- position-wise feed-forward network의 intermediate activation
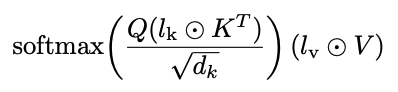
- (IA)^3에 의해 도입된 새로운 파라미터들을 T0 학습을 위해 사용한 데이터셋들을 이용해 사전학습할 시 성능이 증가
평가
- 모델
- T0: MLM 방식으로 사전학습된 encoder-decoder 기반의 T5에 기반
- zero-shot 일반화가 가능하도록 하기 위해 다양한 태스크들의 프롬프트를 사용해 T5를 파인튜닝
- 데이터셋
- RAFT: real-world few-shot task
의의
- 각기 다른 파인튜닝 데이터셋에 대해 별도의 하이퍼파라미터 튜닝이나 수정 없이도 훌륭한 성능을 보임
- 비단 성능(accuracy)뿐만 아니라, 추론 비용, 학습 비용, 저장 비용, 메모리 사용량 등 computation cost에 대해서도 이점을 가지고 있음을 보임

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab