LoRA: Low-Rank Adaptation of Large Language Models
ICLR 2022
분야 및 배경지식
Language Model Adaptation
(+ related works에 NLP 연구의 큰 흐름을 쉽게 이해할 수 있는 내용들이 잘 정리되어 있어서, 내용이 많지만 여기에 추가)
Transformer Language Models
- Transforme란 self-attention을 위주로 사용한 sequence-to-sequence architecture
- Transformer를 기반으로 BERT와 GPT-2라는 중요한 패러다임 등장, 두 언어모델 모두 거대한 규모의 텍스트를 기반으로 학습. 이렇듯 일반적인 도메인의 데이터에 대해 거대한 규모로 사전학습을 진행한 후 태스크 특화 데이터에 대해 파인튜닝을 진행하면 뛰어난 성능향상이 이루어진다는 것이 밝혀짐
Fine-Tuning
- 일반적인 도메인에 대해 사전학습한 모델을 특정한 태스크(downstream task)에 대해 재학습하는 방법
Prompt Engineering
- GPT-3 175B가 오직 몇 개의 추가적인 학습예시를 갖고도 adaptation이 가능하다는 것이 드러났으며, 결과는 input prompt에 크게 의존적이라는 사실이 밝혀짐
- 원하는 태스크에 대해 모델의 성능을 최대화하는 프롬프트를 고안하고 만드는 것이 중요한데, 이를 prompt engineering 혹은 prompt hacking이라고 부름
Adaptation Methods (Baselines에서 발췌, 위 작성내용과 overlap 있음)
- Fine-Tuning: adaption의 일반적인 방식. 모든 모델 파라미터를 gradient updates. 단순한 변형으로는 다른 Layer는 고정시키고 일부 layer에 대해서만 update
- Bias-only or BitFit: bias vector만 학습
- Prefix-embedding tuning: input token에 학습가능한 word embedding을 가진 특별한 token을 추가. 해당 토큰은 일반적으로 모델의 단어사전에 포함되지 않음. 해당 토큰을 어느 위치에 놓을 것이냐가 성능에 영향을 미치는데, prompt의 앞쪽에 토큰을 붙인다면 Prefixing이라고 일컬음. 만약 word embedding을 학습하는 것이 아니라 transformer layer의 activation을 배운다면, Prefix-layer tuning
- Adapter Tuning: self-attention module에 adapter layer와 residual connection을 추가하는 방식. 다양한 변형 존재 (parameter efficient adpatation!)
문제점
- 최근 거대한 하나의 사전학습 모델을 이용하여 여러 개의 downstream task를 수행하는 방법이 일반적이나, 기존의 finetuning은 기존 모델만큼 많은 수의 파라미터를 가지는 한계 존재 (not parameter efficient)
- 적은 수의 태스크 특화 파라미터를 사용하는 방법(예: adapter)이 해결책으로 제시되었으나, 1) inference latency가 생기며 2) 모델의 품질과 효율성 사이 trade-off가 발생
Adapter의 한계
- 트랜스포머 블록마다 2개의 adapter layer를 추가하거나, 블록 당 하나의 adapter layer와 LayerNorm을 추가하는 등의 방식
- adapter layer에서의 추가적인 연산을 bypass할 직접적인 방법이 없음. adapter가 적은 수의 파라미터를 가지고 있지만, 거대한 NN은 latency를 낮추기 위해 하드웨어 병렬화(parallelism)가 필요, adapter layer는 순차적으로(sequentially) 처리되어야 함. 병렬화 없이 단일 GPU에서 inference가 수행될 시 adapter 사용했을 때 latency 증가
Prompt Tuning의 한계
- Prefix tuning은 최적화하기 어려우며 학습가능한 파라미터들에 대해 비단조적으로(non-monotonically) 변화
- adaptation을 위해 sequence length 일부를 사용하는 방식으로 downstream task를 위한 sequence length를 감소시켜 성능에 영향
해결책
LoRA(Low-Rank Adaptation)
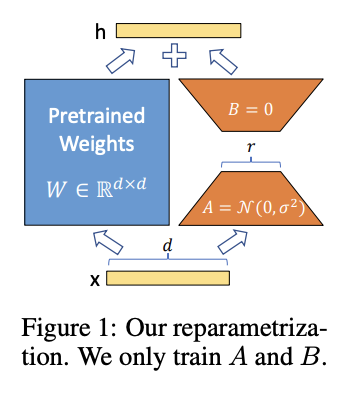
- motivation: Learned over-parameterized models in fact reside on a low intrinsic dimension. The authors hypothesize that the change in weights during model adaptation also has a low "intrinsic rank"
- 사전학습된 모델의 weight은 고정, Transformer 아키텍처의 각 레이어에 학습가능한 rank decomposition matrices를 주입하여 Downstream task를 위한 학습가능한 파라미터의 수를 감소시킴 (low-rank structure 활용)
Understanding Low-Rank Updates
- low-rank structre의 장점: hardware barrier 낮춤, 병렬로 여러 실험 가능케 함, 사전학습된 weight와 update weight가 어떠한 관련성을 가지는지 더 나은 해석가능성(interpretability) 보임
- self-attention module에서 query, value에 대한 weight matrix를 adapt하는 것이 가장 좋은 성능을 보임 (더 큰 rank를 가진 단일 형식의 weight를 adapt하는 것보다는 더 많은 수의 weight matrices를 adapt하는 것이 바람직)
- update matrix는 굉장히 작은 intrinsic rank를 가질 수 있으며, low-rank adaptation matrix로 충분
- low-rank adaptation은 일반적인 사전학습 모델에서는 학습되었으나 강조되지 않았던 특정 downstream task에 대한 중요 feature들을 잠재적으로 amplify
평가
- Models: RoBERTa, DeBERTa, GPT-2, GPT-3 175B
- Tasks: GLUE benchmark, WikiSQL, SAMSum, ...
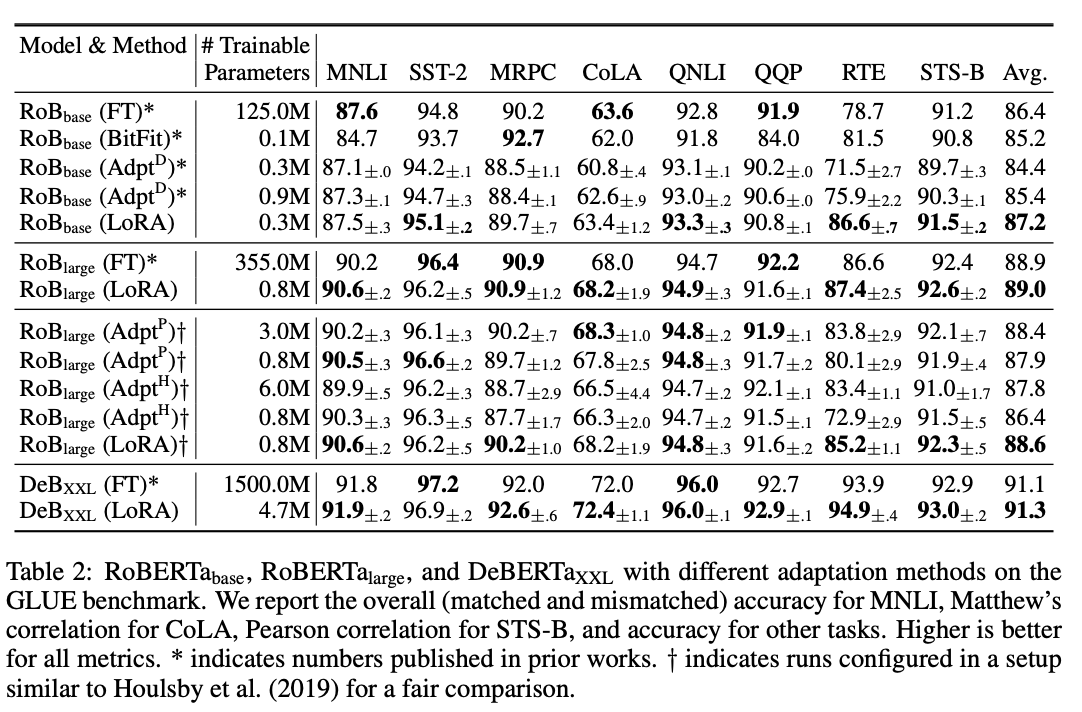
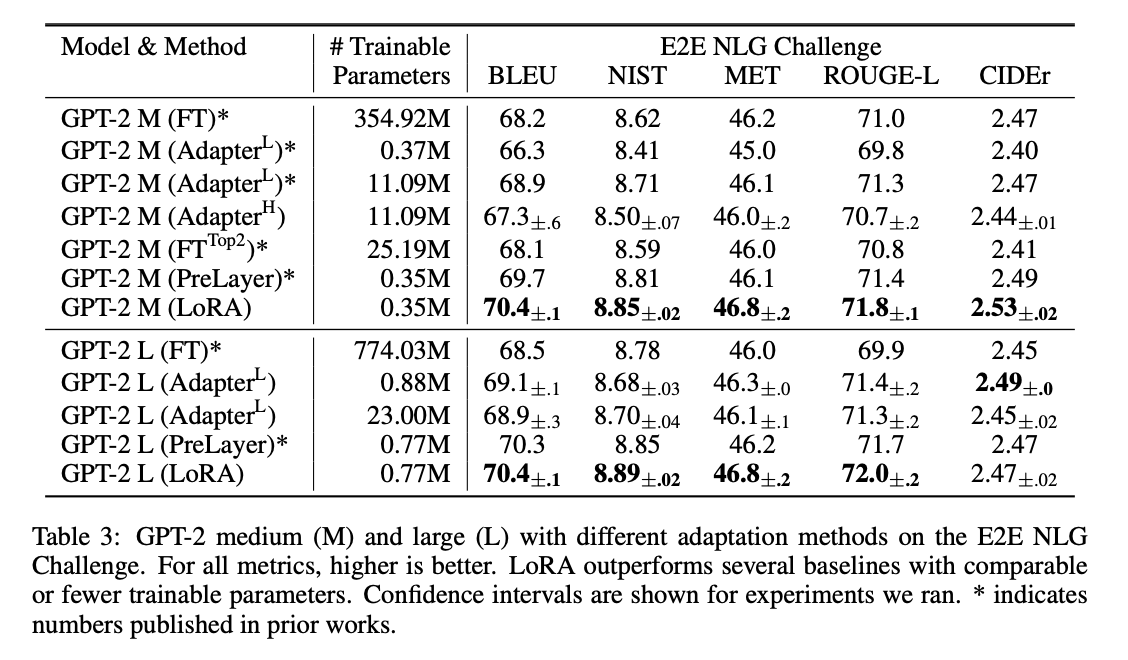
한계
- 각기 다른 A, B를 가진 다른 태스크들에 대한 인풋들을 어떻게 함께 batch로 만들어 단일 forward pass에 통과시킬지가 직관적이지 않음 (다만, weights를 합치고 LoRA module을 다양하게 선택해보는 방식 사용해볼 수 있음)
- 파인튜닝보다는 낫지만, 여전히 LoRA 또한 성능을 내는 메커니즘을 명확하게 이해할 수 없음
- LoRA에 적용할 weight matrix를 선택하는 데에 heuristics에 의존
의의
- 더 적은 학습가능한 파라미터를 가짐으로써 효율성을 증대시키고 hardware barrier를 낮추는 동시에, 뛰어난 학습 성능을 보여줌 (reduction in memory and storage usage)
- adapter와 다르게 추가적인 inference latency를 필요로 하지 않음 (배포되었을 때 frozen weight와 trainable matrices merge 가능)
- 각기 다른 태스크들을 위한 작은 LoRA 모듈을 만듦으로써 하나의 사전학습모델을 공유하고 사용할 수 있음 (can switch between tasks while deployed at a much lower cost by only swapping the LoRA weights)
- 다른 adaptation 방법들과 결합하여 사용될 수 있음 (orthogonal)
- model-agnostic (다양한 아키텍처의 모델에 사용 가능)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab