How Language Model Hallucinations Can Snowball
arXiv, 2023
분야 및 배경지식
- Hallucination (=환각, 그럴듯한 거짓말)
- 없는 사실을 만들어내거나 존재하지 않는 출처를 만드는 등 그럴듯한 거짓말을 생성하는 문제
- produce plausible-sounding falsehoods
- 일반적으로 언어모델의 지식 차이(=knowledge gap) 때문에 야기되는 문제로 알려짐
- 언어모델이 사전학습 시 학습한 지식과 실제 지식이 다를 수 있음 (e.g. outdated, ...)
- 없는 사실을 만들어내거나 존재하지 않는 출처를 만드는 등 그럴듯한 거짓말을 생성하는 문제
문제점
Hallucination Snowballing

- 언어모델이 부정확한 응답을 먼저 제시한 후 이에 따라 옳지 않은 설명을 생성해내는 문제
- 처음 생성된 오류가 언어모델의 이후의 성능에도 전파됨 (error propagation)
- 언어모델이 생성한 잘못된 설명은 독립적으로 언어모델에게 주어질 시 언어모델은 해당 설명이 잘못되었음을 판별할 수 있음
문제의 원인
두괄식 대답 (initial committal)
- 정답이 먼저 나오고 이에 대한 설명이 뒤따르는 형태의 데이터를 기반으로 학습하였기 때문에, 언어모델은 정답을 먼저 생성하곤 함
- 생성된 정답이 이후 생성하는 문장의 문맥(context)으로 작용하기 때문에, 이후의 설명 또한 앞서 생성한 정답을 정당화하는 방향으로 만들어짐
내재적 순차성 (inherently sequential)
- 순차적인 추론을 필요로 하는 태스크를 단일한 타임스텝 내에서 해결할 수 없음
- e.g. 소수 찾기, 그래프 연결성
실험
- 모델
- ChatGPT, GPT-4
- 데이터셋 (QA)

- 소수 찾기
- 1,000 - 20,000 사이 500개의 랜덤한 소수를 이용
- 정답은 모두 Yes
- 상원 의원 검색
- 미국 상원의원이 어떤 대학교를 나왔는지 질의
- 정답은 모두 No
- 그래프 연결성
- 14개 도시 사이의 12개의 비행정보를 제시, 도시 간 이동 가능한지 질의
- 정답은 모두 No
- 소수 찾기
실험 결과
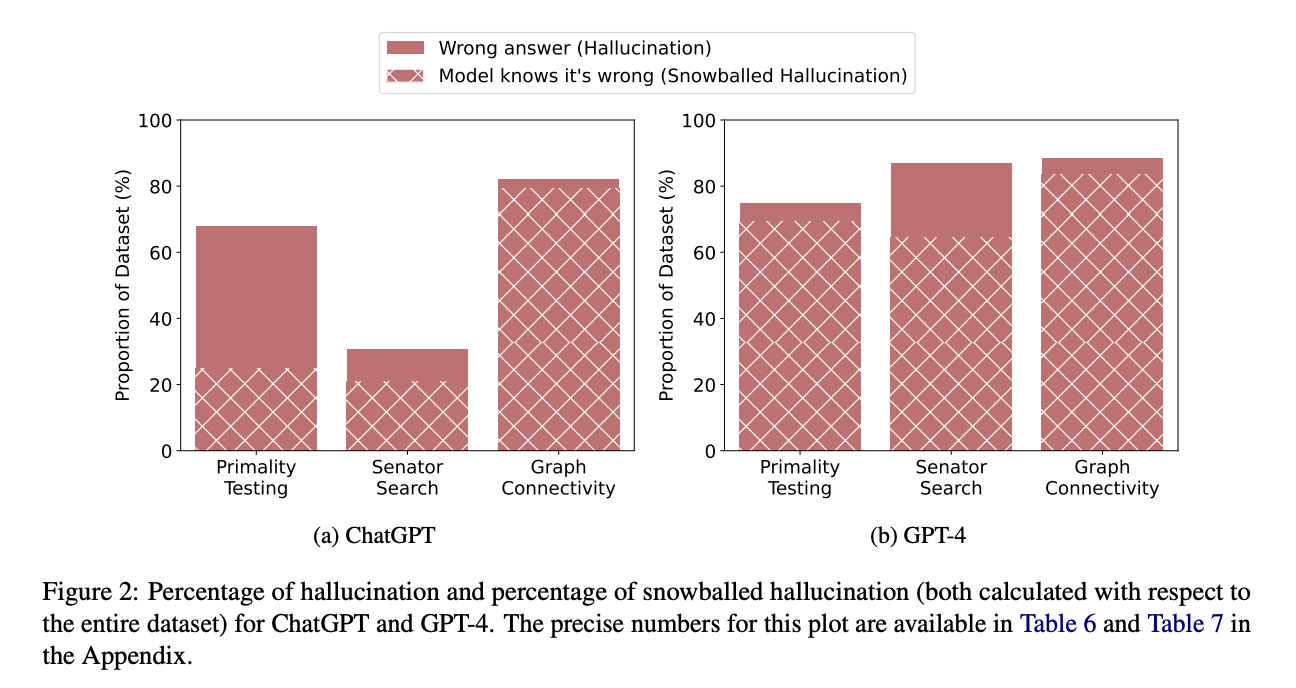
- 굉장히 낮은 정확도(accuracy)를 보임
- ChatGPT의 상원 의원 검색 결과를 제외하면 모두 50% 미만
- 반면 틀린 설명을 언어모델에게 보여주었을 때 해당 주장이 잘못되었음을 상당히 높은 수준으로 판단
- ChatGPT는 67.37%, GPT-4는 87.03%
가능한 해결책
- 더 나은 프롬프트 사용
- Let's think step-by-step 프롬프트 추가
- 상원 의원 검색은 완벽하게 수행, 소수 찾기의 오류는 10% 이하, 그래프 연결성 오류는 30% 이하로 줄어듦
- 다만, 여전히 hallucination snowballing 문제는 존재
- Let's think step-by-step 프롬프트 추가
- 알고리즘 수정
- temperature, top-k sampling, nucleus sampling 등은 문제 해결에 큰 도움이 되기 어려움
- beam search가 가장 타당한 해결책으로 보이나, API에서 제공하지 않는 기능으로 실험 불가
- 모델이 정답을 생성하기 전 일련의 추론을 수행하도록 하거나, 역추적(backtracking) 탐색을 활용하는 등 새로운 학습 전략 도입 가능 (but API 제한으로 실험 불가)
한계
- 질의응답 (QA) 태스크에 한정된 실험 결과
- API로 접근해야 하는 언어모델의 태생적 한계 때문에 파인튜닝 등 모델 학습 방법을 실험해볼 수 없음

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab