Locating and Editing Factual Associations in GPT
NeurIPS 2022
분야 및 배경지식
- Factual Knowledge
- 방대한 코퍼스로 사전학습한 모델은 사실관계에 대한 지식을 갖고 있음이 연구를 통해 증명됨
- 일반적으로 사실관계를 (주어, 관계, 목적어) 형태의 튜플로 표현
- (s, r, o)에 대해 (s, r, o*)처럼 새로운 목적어에 대해 학습하는 연구가 일반적으로 model edit 연구로 분류됨
문제
- 모델이 갖고 있는 지식은 시간이 지남에 따라 outdated될 수 있으며, 모델이 잘못 학습한 지식은 수정이 가능해야 함
- 모델이 내부적으로 어떻게 동작하는지 알기 어려워 문제 해결이 어려움 (black-box)
해결책
Causal Traces (Causal Intervention)
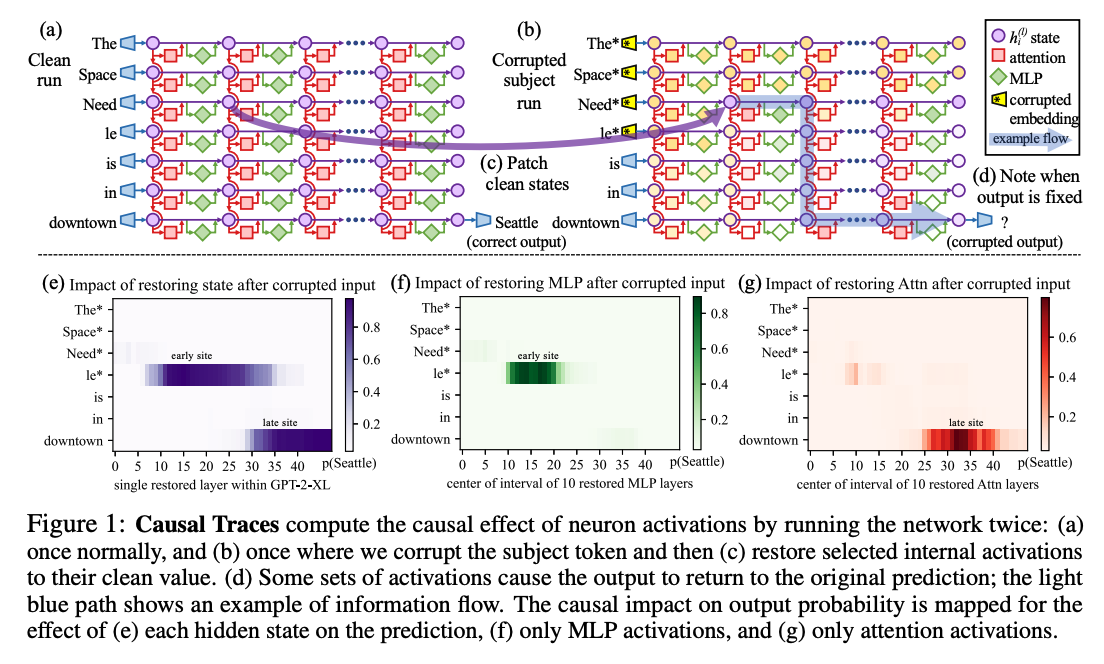
- causal mediation analysis
- causal graph에서 중간 변수들의 공헌도를 측정하기 위한 방법
- 총 3개의 run에서 internal activation을 관찰해 각 state의 사실관계 예측에 대한 기여도를 계산
- clean run: 사실을 예측하는 경우
- corrupted run: 예측에 손상을 입은 경우
- 주어 개체에 상응하는 embedding vector에 epsilon을 더해 값을 변경(obfuscate)
- 주어에 대한 정보 일부를 잃어버렸기 때문에 틀린 답을 내놓을 확률이 높아짐
- corrupted-with-restoration run: 단일 상태(single state)가 예측을 복구할 수 있는지 확인
- corrupted run과 유사하나 layer l의 token i를 예외로 함
- computation graph에서 인과적인 중요도 파악 가능
- causual tracing results
- 주어의 마지막 토큰이 초반부(early site)에서 인과관계에 큰 영향을 미친다는 사실을 파악
- MLP 모듈이 초반부(early site)에 결정적인 역할을 수행함을 파악
- 사실관계를 기억할 때 중간 레이어에 위치한 MLP 모듈이 중요한 역할을 수행
- causal tracing은 integrated gradients와 같은 gradient-based 방식보다 더 많은 정보를 제공하며 다양한 noise configuration에 대해 강건(robust)
- localized factual association hypothesis
- 위와 같은 분석을 토대로 중간 레이어의 MLP 모듈이 주어를 input으로 받으면 해당 주어에 대해 저장했던 특성들을 output으로 제공한다고 가정
- factual association을 1) MLP module 2) 특정 중간 레이어 3) 주어의 마지막 토큰을 처리할 때라는 3가지 차원으로 국한시킴
ROME (Rank-One Model Editing)

- 이전 연구들을 바탕으로 MLP가 linear associative memory로 여겨질 수 있음을 가정
- W_proj가 linear associative memory라는 것은 W가 key-value를 저장함을 의미
- constrained least-square 문제를 풀음으로써 메모리에 최적의 new key-value pair를 삽입할 수 있음
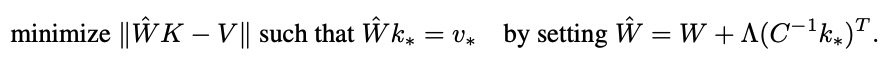
- W는 본래의 행렬
- C=KK^T는 위키피디아 텍스트의 일부로부터 계산한 uncentered covariance k를 활용
- Λ는 본래의 메모리 행렬에 대한 새로운 key-value 쌍의 residual error에 비례하는 벡터
- Λ = (v*-Wk*)/(((C^-1)k*)^T)k* (k*, v*은 새로운 key-value 쌍)
- k*, v*를 계산하면 직접적으로 특정 사실을 삽입할 수 있음
Step 1. 주어를 선택하기 위해 k*을 선택
- activation을 모음으로써 k*를 계산
- 주어를 포함하고 있는 텍스트를 통과시켜, 특정 레이어 l에 마지막 주어 토큰의 인덱스 i에 대해 MLP 내부에 위치한 non-linearity 직후의 값을 확인 (figure 4(d))
- 주어의 마지막 토큰 앞에 어떤 토큰들이 나오는지에 따라 상태가 변하기 때문에, 몇 개의 텍스트에 대한 평균값을 활용해 k* 지정 (e.g. 50개의 랜덤 토큰 시퀀스 활용)
Step 2. 사실을 기억하기 위해 v* 선택
- 동일한 주어에 대해 새로운 사실인 (r, o*)을 학습하도록 value v*를 선택
- argmin L(z)를 활용
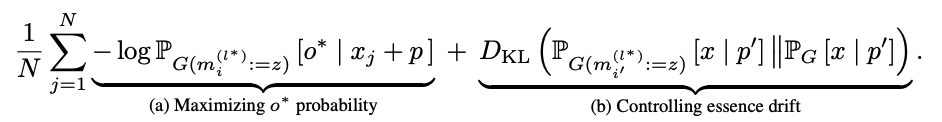
- factual prompt p에 대해 새로운 목적어인 o*를 예측할 수 있도록 관련 확률을 최대화
- 다른 factual prompt p'에 대해 예측이 크게 변하지 않도록 KL divergence를 최소화
- 이러한 최적화는 모델의 weight을 직접 수정하는 것이 아니라, v*를 나타내기 위한 것임
- k*를 선택하는 것과 유사하게, v*를 최적화하는 것 또한 여러 random texts를 활용
Step 3. 사실을 삽입
- 특정 사실 (s, r, o*)를 나타내는 (k*, v*) 쌍을 계산하면 이를 직접적으로 삽입할 수 있는 rank-one update를 통해 MLP weight인 W_proj를 업데이트
평가
metrics
- efficacy: 학습한 문장을 잘 맞추는지
- efficacy score(ES): P[false fact(o*)] > P[correct fact(o_c)] 비율
- efficacy magnitude(EM): P[false fact] - P[correct fact] (mean difference)
- generalization: 학습한 문장과 동일 사실을 표현하는 다른 문장(유사 문장)또한 잘 맞추는지
- paraphrase score(PS)
- paraphrase magnitude(PM)
- specificity: 학습한 사실관계와 관련이 없는 사실관계의 경우 예측이 그대로 유지되는지 (학습하는 주어와 유사한 nearby subject를 활용)
- neighborhood score(NS)
- neighborhood magnitude(NM)
- semantic consistency: 생성한 문장이 일관성을 보이는지
- RS: 생성된 텍스트의 unigram TF-IDF 사이의 cos similarity
- fluency: 생성한 문장이 자연스러운지
- GE: bigram, trigram 엔트로피의 가중평균. 반복이 많을수록 값이 낮아짐
dataset
-
zero-shot Relation Extraction (zsRE)
- 10,000개의 record는 각각 하나의 사실관계 문장, 유사문장(paraphrase), 연관성이 없는 문장으로 이루어짐
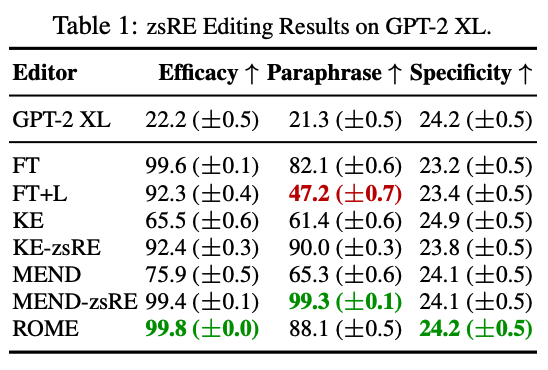
- model edit에서 사용되는 hypernetwork와 finetuning 방식 대비 경쟁력이 있음을 밝힘
-
CounterFact
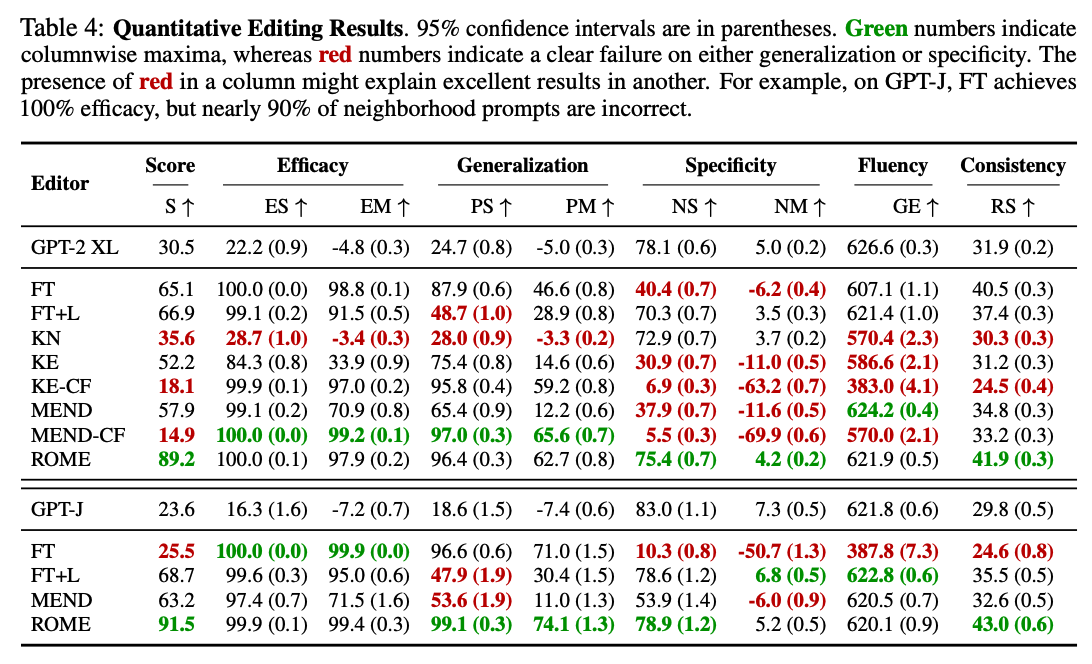
- 기존의 model edit 연구가 사용한 zsRE와 같은 데이터셋은 지식을 변경할 때 모델이 쉽게 예측하는 값으로 o*를 설정해 실제 지식을 변경할 때 발생 가능한 어려움을 과소평가
- 이를 해결하기 위해 더욱 어려운 false fact를 설정 (false fact로 지식을 업데이트)
- 18번째 레이어에서 generalization이 최고치를 달성
한계
- 사람이 평가하기에도 괜찮은 평가를 받았으나, constrained finetuning에 비해 유창성이 떨어짐
- constrained finetuning 방식보다는 삽입한 사실에 대해 더욱 consistent하다고 평가받음
- 하지만 fluency가 떨어진다는 것은 이와 같은 model edit 방식이 language modeling ability를 저하시킬 수 있다는 사실을 의미
- 한 번에 1개의 사실에 대해서만 수정이 가능
의의
- GPT의 국지적인 연산(localized computation)을 통해 사실 관계(factual association)의 직접적인 수정이 가능함을 제시
- Midlayer MLP module이 특정 주어에 국한되면서도 문장의 피상적인 형태를 넘어서 일반화가 가능한 사실관계(factual association)를 저장하고 있음을 보임
- 문장의 피상적인 형태를 넘어선다는 것은 학습한 문장 이외에 동일한 사실관계를 표현하는 다른 문장들에 대해서도 적용 가능함을 의미
- 언어모델의 interpretability(해석가능성)에 기여
- Midlayer MLP module이 특정 주어에 국한되면서도 문장의 피상적인 형태를 넘어서 일반화가 가능한 사실관계(factual association)를 저장하고 있음을 보임
- 이전 연구들과는 다르게 일반화(generalization)와 국지화(specificity)를 동시에 달성

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab