Mass Editing Memory in a Transformer
ICLR 2023
분야 및 배경지식
- Model Edit (=knowledge edit)
- 언어모델에 새로운 지식을 업데이트하기 위해 특정 모델 파라미터에 해당 지식을 주입하는 방식
- 이전 연구들은 constrained fine-tuning, hypernetwork, rank-one model editing 등의 방식을 사용
- 일반적으로 사실적 지식(factual knowledge)의 형태를 (주어 s, 관계 r, 목적어 o)의 triplet으로 설정하며 목적어(o)를 업데이트함으로써 edit 성능을 측정
- Knowledge Base
- 일반적으로는 전통적으로 사용되던 구조화된(structured) 지식 베이스(KB)를 의미
- 구조화된 지식 베이스는 정확하게 쿼리되고, 측정되며, 업데이트가 가능하다는 장점이 있지만 이를 사용하기 위해 훈련이 필요하며, 상식과 같은 분류되지 않은 지식에 대해서는 제한적으로 커버함
- Language Model as Knowledge Base
- 언어모델이 대량의 코퍼스를 통해 학습함으로써 세상에 대한 많은 지식들을 저장한다는 사실이 밝혀지자 언어모델이 전통적인 지식 베이스와는 다른 형태의 KB로 여겨짐
- 지식의 분류, 저장, 업데이트가 어렵고 프롬프트를 어떻게 작성하느냐에 따라 답변이 달라지는 단점이 존재하나, 확장 가능하며 고정된 틀에 의해 제약받지 않는다는 장점이 존재
문제점
- model edit의 중요성
- 언어모델이 가진 오래된(obsolete) 정보를 대체하거나 특별한 지식을 더하는 등 언어모델이 가진 기억(지식)을 업데이트하는 것은 중요
- 이전 연구의 한계
- 이전 연구들은 한 번에 하나 혹은 적은 수의 지식을 업데이트 (제한적 규모)
해결책
MEMIT
- 새로운 지식을 주입하기 위해 명시적으로(explicitly) 계산된 파라미터 업데이트를 수행하는 확장 가능한 multi-layer update algorithm
- 주어의 마지막 토큰에서 사실관계 기억을 담당하는 일련의 중요한 MLP 레이어들이 있다는 이전 연구를 바탕으로 vector association을 계산해 이를 이용해 파라미터 업데이트
MLP 레이어의 주요 path 확인

- GPT에서 사실관계(factual association)에 대한 지식을 관장하는 중요한 MLP 레이어를 확인
- GPT-J에서는 {3, 4, 5, 6, 7, 8}
단일한 linear associative memory(=single layer)에 batch update
- MLP layer를 linear associative memory로 가정한다면 W는 input key와 이에 대해 상응하는 memory value를 저장하고 있으며 minimal squared error 문제를 풀음으로써 최적의 W0를 구할 수 있음
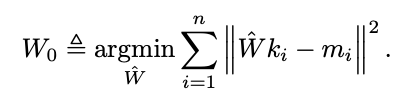
- normal equation을 통해 풀 수 있음 (WKK^T = MK^T)
- 하나의 association(지식)이 아니라 여러 개의 association도 함께 고려하여 W0에 약간의 변화(∆)를 더해 새로운 행렬 W1로 업데이트
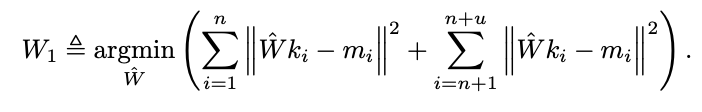
- 정규 방정식을 이용해 풀면 아래와 같은 결과가 나옴
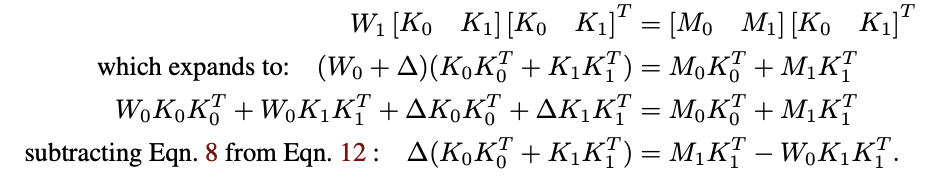
- K0K0^T를 C0으로 치환, 이는 기존에 존재하는 key의 uncentered covariance에 비례하는 상수
- C0의 경우 임의로 뽑은 실제 샘플들을 활용해 계산
- M1-W0K1을 R로 치환, 이는 이전 weight W0에 대해 평가된 새로운 association들의 residual error

- 정규 방정식을 이용해 풀면 아래와 같은 결과가 나옴
여러 레이어 업데이트

-
파라미터 변화의 정도가 최소화될 때 강건성이 증가한다는 이전 연구를 바탕으로 update를 여러 레이어에 골고루 나누어 진행(spread evenly)
- i: memory, L: layer, z: hidden vector (new), h: hidden vector (original), delta: change (residual vector)
-
1) z_i 계산
- L 레이어의 주어의 마지막 토큰 S에서 h를 대체할 시 원하는 association을 표현할 수 있는 벡터
- z = h+delta로 표현할 수 있으며, residual vector delta는 gradient descent를 이용해 최적화
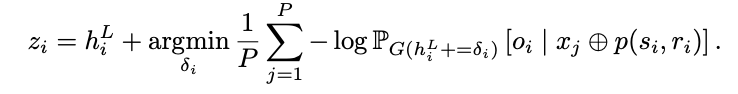
- x는 random prefix(일반화를 위해 사용), p는 factual prompt
-
2) z_i - h_i(L)를 레이어에 분할
- 특정 레이어에 대한 수정은 다음 레이어에 영향을 미치기 때문에 delta를 레이어 순서대로 계산
- key는 각 layer의 W_out의 input, memory는 현재 값과 남아있는 residual 일부의 합으로 계산

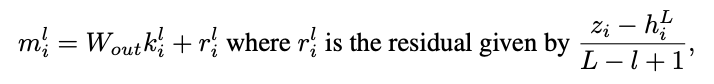
전체 알고리즘

평가
metrics
- specificity: 업데이트하지 않은 지식에 대해 모델이 학습 이전과 동일한 결과를 보이는지 (학습하지 않은 지식에 대해서는 성능 유지; Retain)
- neighborhood success (NS): 구별되지만 의미적으로 연관이 있는 주어에 대해 테스트
- efficacy: 학습에 사용한 프롬프트를 잘 학습하였는지
- efficacy success (ES): E[P[new object] > P[real world object]]
- generalization: 특정한 프롬프트 이외에 유사한 다른 프롬프트에 대해서도 동일한 지식을 보이는지 (특정 프롬프트에 과적합되지 않고 지식 자체를 잘 학습하였는지; Update)
- paraphrase success (PS)
- fluency: 언어모델 자체의 성능(유창성)을 해치지는 않는지
- reference score (RS): 의미적 유사성 평가. TF-IDF similarity
- generation entropy (GE): 유창성 평가. bigram, trigram, n-gram 분포의 엔트로피의 가중평균
datasets
- zsRE (10K 데이터 수정)
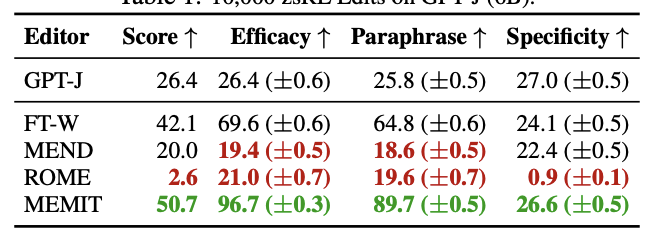
- MEMIT이 전반적으로 좋은 성능을 보임
- 단순한 fine-tuning이 MEND나 ROME과 같은 model editing baseline보다 대량의 지식 업데이트에 대해 좋은 성능을 보임
- CounterFact (10K 데이터 수정)

한계
- 특정 관계에 대해서는 edit이 힘들다는 결과를 실험적으로 보였으나 그 원인에 대한 탐구가 없음
- 관계적 지식(relation)에 국한된 연구
- 공간, 시간, 수학, 언어, 절차 등 다양한 분야의 지식에 대해서도 적용 가능한지 알 수 없음
의의
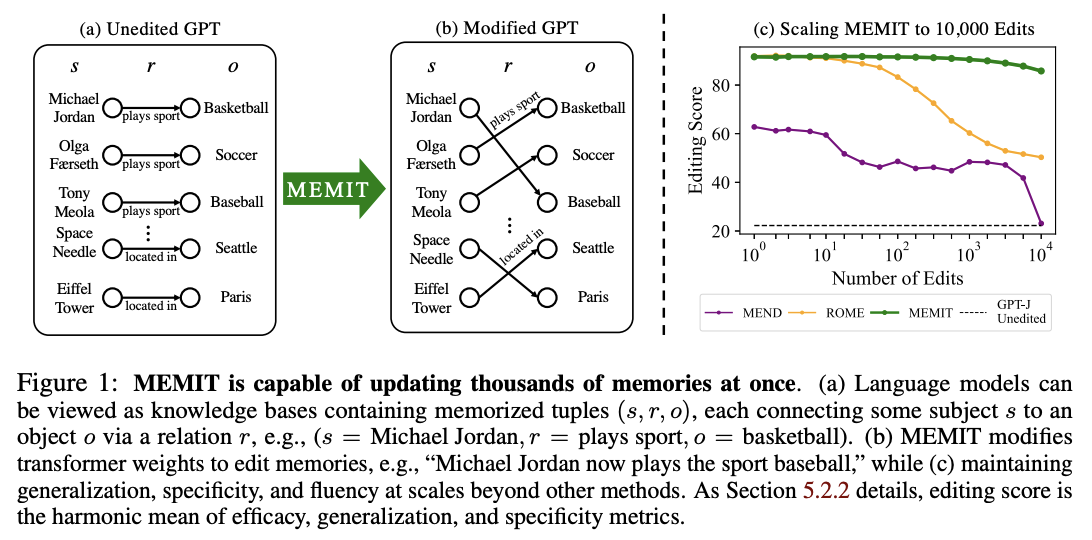
- 이전 연구와 다르게 수천 개의 지식을 한꺼번에 업데이트할 수 있음
- specificity와 genearlization에서 모두 좋은 성능을 보임
- 업데이트하려는 메모리(지식)의 유사성, 다양성과는 상관없이 효과적으로 model edit 가능
- 언어모델의 내부적인 연산에 대한 명시적인 분석을 통해 블랙박스인 언어모델을 이해하는 데에 기여

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab