Memory-Based Model Editing at Scale
ICML 2022
분야 및 배경지식
Model Editors (model edit)
- 사전학습 모델에 국지적인 수정(local update)을 취하는 방법
- aims to enable fast, data-efficient updates to a pre-trained base model’s behavior for only a small region of the domain, without damaging model performance on other inputs of interest
- 업데이트된 지식을 주입하거나 바람직하지 않은 예측을 수정
- 불충분한 표현성(expressiveness)의 한계
- 수정하고자 하는 범위를 정확하게 모델링하기 어려움, 수정하고자 하는 지식과 느슨하게 관련된 예시들에 대해 부정확한 예측 (fail to discrimiate between entailed and non-entailed facts)
- 수정을 많이 진행할 경우 실패 (cannot handle large numbers of edits)
- 종합적으로, 기존의 연구들은 수정 성능, 연산 효율성, 궁극적인 실현가능성(practicality)의 한계를 보임 (implicit knowledge edit의 경우 gradient-based, 저자들은 이 방식이 한계가 있음을 주장. Gradients may therefore not provide sufficiently ‘global’ information to enable reliable edit scoping, particularly for distant but related example)
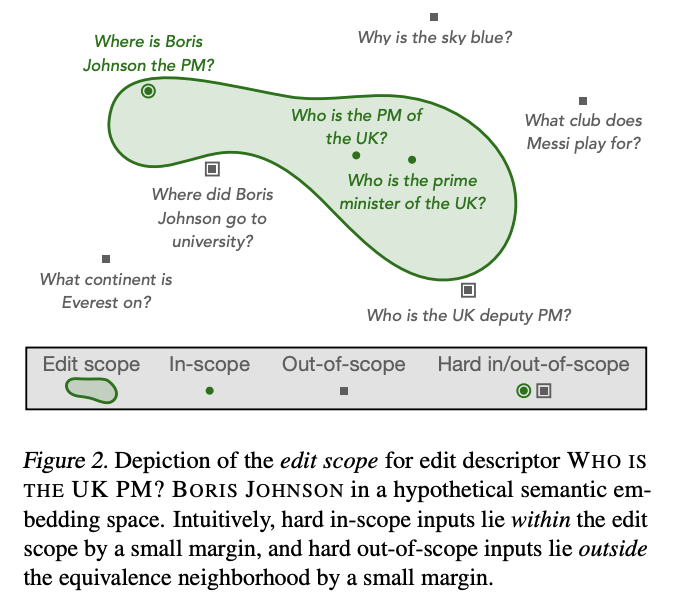
- in-scope example: back-translation, hand-annotated correspondence 활용
- out-of-scope example: nearest neighbors in a semantic sentence embedding space, hand-annotated corresponsdence 활용
문제점
- 모델이 배포된 이후 모델의 일부 행동을 빠르게 수정하는 능력이 필요
- 거대한 크기의 인공신경망 또한 오류를 만들 수 있음
- 시간이 지나고 세상이 변함에 따라 한때 정확했던 예측이 유효하지 않을 수 있음
해결책
SERAC (Semi-Parametric Editing with a Regtrieval-Augmented Counterfactual Model)
- 기존의 연구들과는 다르게, parameter space에서 모델 수정을 가하는 것이 아니라, 기존 모델은 수정하지 않은 채 캐시 내 저장한 수정 예시들을 활용하는 방식 (gradient-free memory-based)
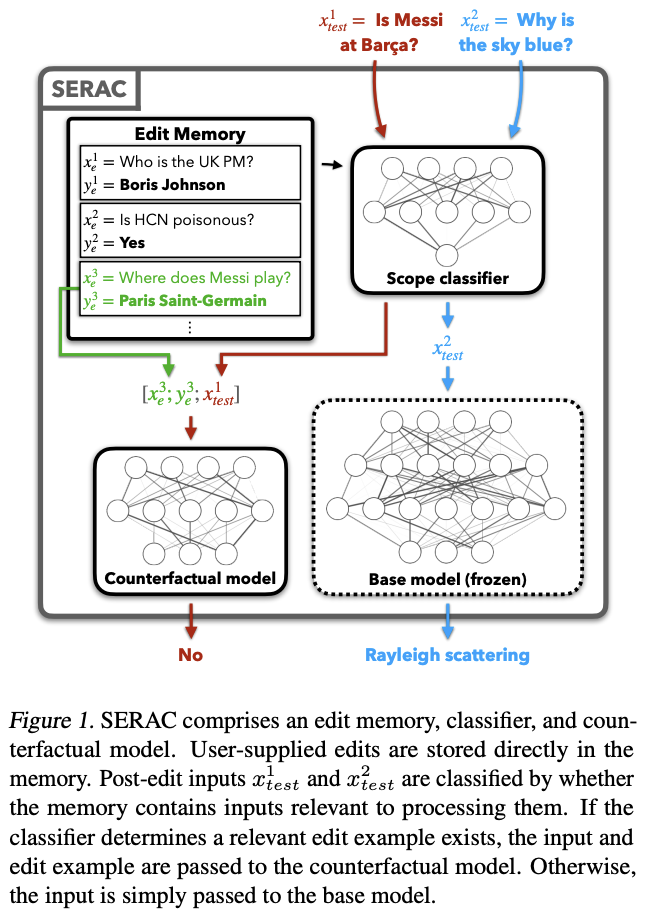
edit memory
- 사용자가 제공한 edit descriptor를 저장한 캐시 메모리
scope classifier
- 모델의 예측이 "언제" 수정되어야 하는지를 판단 (주어진 input이 edit scope에 있는지 여부를 판단)
- 가장 높은 확률이 in-scope로 판단된다면 새로운 input과 edit memory로부터 주어진 수정 정보를 활용해 counterfactual model이 예측 진행, out-of-scope로 판단된다면 기존의 base model의 예측 활용
- 수정되는 정보들 사이의 간섭(interference)을 줄임
- cross-attention, embedding-based 두 방식에 대해 실험 진행, cross-attention이 더욱 좋은 성능
counterfactual model
- 모델의 예측이 "어떻게" 수정되어야 하는지를 판단
- 기존 모델(base model)과 동일한 output-space를 갖는 sequence model
평가
-
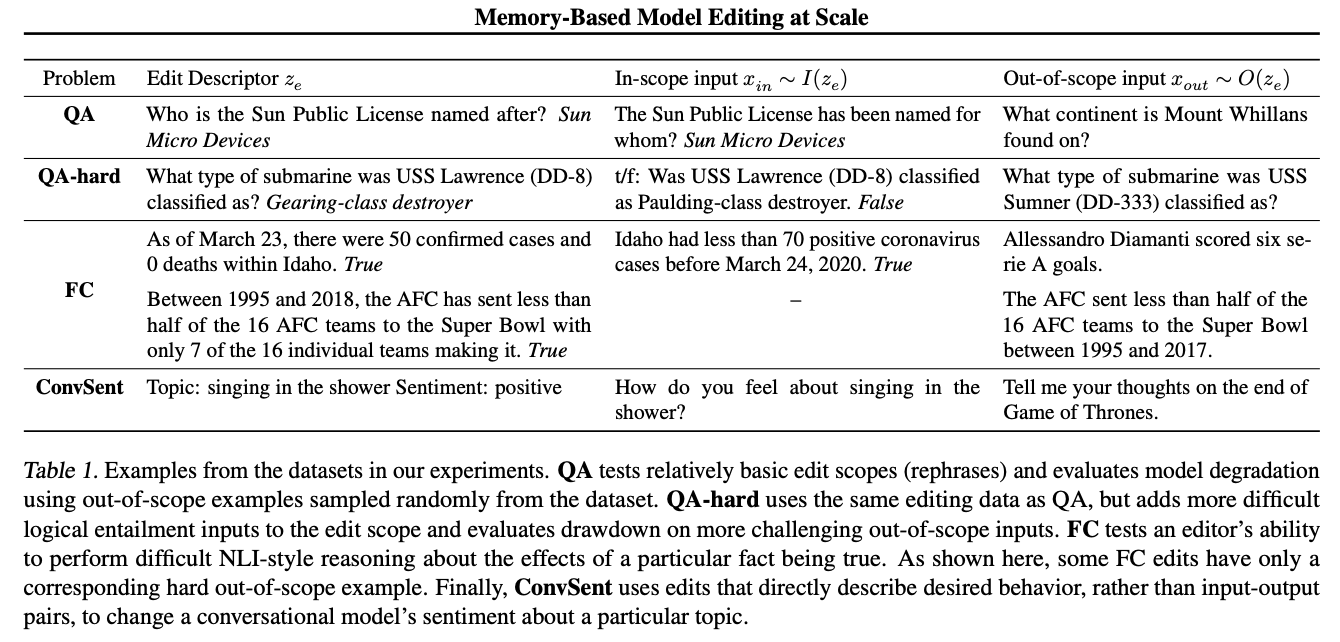
Evaluation Dataset and Tasks
- QA & QA-hard
- zsRE question-answering problem, T5
- QA-hard의 경우 더욱 어려운 in-scope/out-of-scope 예시들을 포함 (in-scope의 경우 기존 논문에서 제시된 테크닉 활용, out-of-scope의 경우 높은 cosine silimarity를 가진(=high semantic similarity) 예시 활용)
- fact-checking
- VitaminC fact verification dataset, BERT
- entailment dataset을 in-scope, out-of-scope로 전환
- dialogue generation
- ConvSent; 다른 주제들에 대한 생성(generation)에 영향을 미치지 않고 특정 주제에 대한 dialog agent의 감정을 수정할 수 있는지 여부를 판단 가능한 새로운 데이터셋, RoBERTa
- QA & QA-hard
-
Metrics
- edit success: in-scope inputs에 대해 얼마나 잘 예측을 진행하는지 (similarity between edited / desired behavior)
- qa, fc에 대해서는 average exact-match 활용
- generation: z-sent(감정의 정확성 측정), z-topic(토픽 일관성 측정)
- drawdown: out-of-scope inputs에 대해 수정 전후 얼마나 차이가 발생하는지 (disagreement)
- qa, fc에 대해서는 average !exact-match 활용
- generation: KL-divergence 활용
- edit success: in-scope inputs에 대해 얼마나 잘 예측을 진행하는지 (similarity between edited / desired behavior)
의의
- 기존 연구들보다 더욱 좋은 성능(in-scope, out-of-scope에 대해서도), 높은 연산 효율성 (동시에 여러 개 수정 또한 가능)
- 기존 연구들(implicit knowledge edit, gradient based)에 대한 꼼꼼한 분석과 한계 지적이 논문의 설득력을 높임
- scope classifier와 counterfactual model을 분리함으로써 각각의 목적에 특화되도록 아키텍처 구현
- edit scope에 대한 고려, automated technique for generating in-scope examples (parapharses) 등 다양한 기존 연구 활용
한계
- 추가적인 연산 시간 필요: 저자들은 그럼에도 불구, 개선 성능이 뛰어나며 base model보다 작은 모델들을 활용한다는 점을 어필함
- 추가적인 메모리 사용: 저자들은 메모리 사용의 대부분은 고정비용이며, 수정을 많이 한다고 해서 늘어나진 않음을 강조. 하지만 edit memory의 경우 계속해서 커질 수 있음을 인정
- edit memory의 edit descriptors의 경우 사용자가 제공해야 함 (not fully automated, somewhat manual)
- model edit의 경우 사용자에 의해 나쁜 의도로 사용될 수 있음을 언제나 염두에 두어야 (모델의 수정은 잘못된 지식을 바로잡을 수도 있지만, 특정한 시각을 강화하는 방향으로 악용될 수도 있음)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab
감사합니다. knowledge edit 파트 공부중에, 덕분에 도움받고갑니다