Fast Model Editing at Scale
ICLR 2022
분야 및 배경지식
Implicit knowledge edit (model edit)
사전학습 모델의 예측 오류, 잘못된 지식을 수정하고자 하는 연구 분야. memory-augmented 방식을 사용하는 explicit knowledge edit과 다르게 모델 자체를 수정한다는 점에서 구분될 수 있음
Modifying memories in transformer models, 2020
- method: finetuning with L-inf norm (constrained optimization)
- limit: parameter-space만 고려, 충분한 데이터 없이 single edit일 경우 model degradation
Editable neural networks, 2020
- method: meta-learning, 모델의 파라미터 자체에 수정가능성(editability)을 encode하는 방식 (intrinsic editability)
- loss = base task loss + locality loss + edit loss
- limit: high memory consumption
Editing factual knowledge in language models, 2021
- method: hyper network, 모델의 파라미터와 독립적인 별도의 학습된 파라미터를 통해 수정가능성(editiability) 제시 (extrinsic editability)
- raw edit example을 input으로, gradient에 적용할 rank-1 mask와 rank-1 offset을 output으로 하는 knowledge editor 제공
- limit: rich-information in gradient를 충분히 활용하지 못함, input-size에 관계없이 rank-1 결과를 냄
문제점
- 거대한 사전학습 모델들은 오류를 만들기도 하며, 심지어 정확했던 예측 또한 시간이 지남에 따라 틀려지곤 함
- distributed, black-box적인 특성 때문에 모델 내 특정한 타겟을 수정하는 것은 굉장히 어려움
해결책
MEND (Model Editor Networks with Gradient Decomposition)
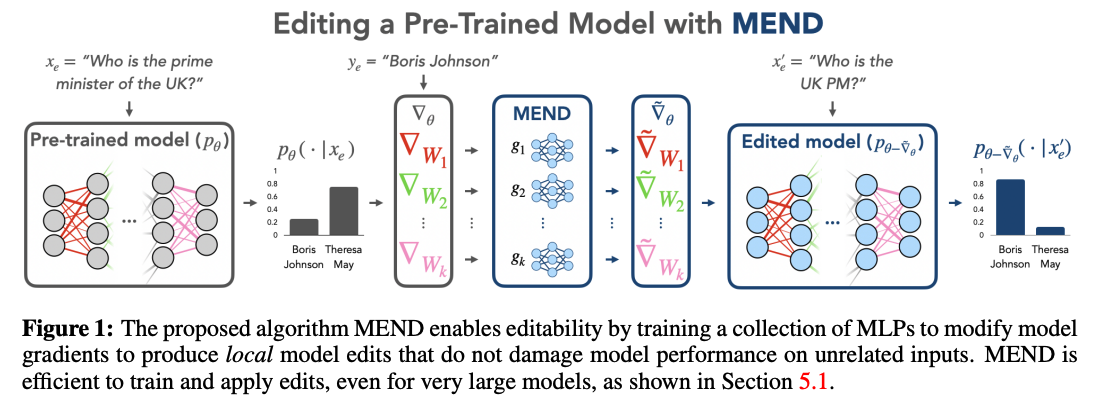
- 단일한 인풋-아웃풋 쌍으로 사전학습 모델의 행동에 변화를 줄 수 있는 작은 auxiliary editing network의 집합
- 데이터: 수정할 input x, output y, 수정할 내용과 전혀 관계없는 locality x, 유사한 의미를 갖는 input x', output y'
- 모델의 파라미터와 독립적인 별도의 학습된 파라미터를 통해 수정가능성(editiability) 제공 (extrinsic editability)
- gradient를 low-rank decomposition한 후 gradient를 변형시킴으로써 모델을 빠르고 가볍게 수정
- a method for learning to transform the raw fine-tuning gradient into a more targeted parameter update that successfully edits a model in a single step
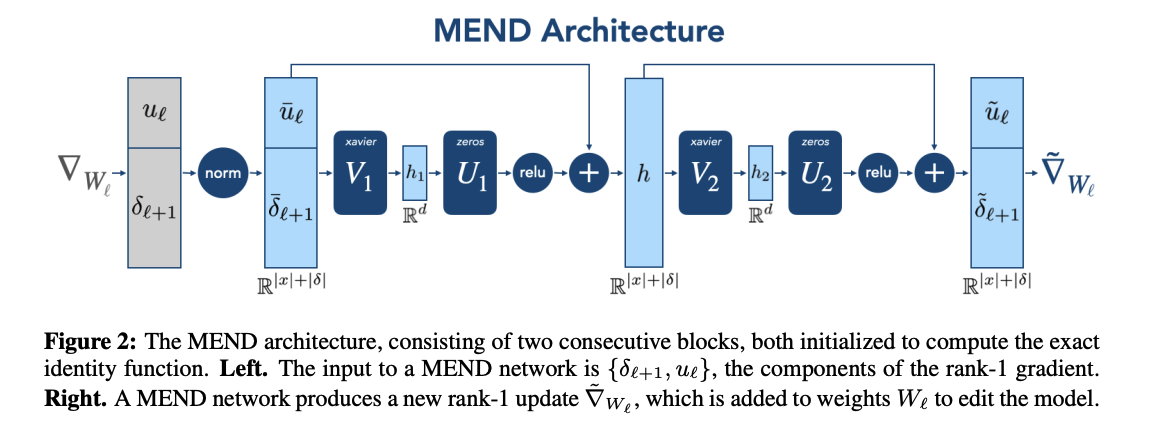
평가
- 평가기준
- reliability: 모델의 아웃풋을 성공적으로 수정/업데이트
- locality: 관련되지 않은 모델의 아웃풋에는 최소한의 영향만을 미침
- generality: 수정하고자 하는 인풋과 관련된 다른 인풋들에 대해서도 옳은 결과를 생성 (e.g. paraphrase, equivalent)
- 평가 데이터셋
- zsRE question-answering: equivalence neighborhood data는 backtranslation으로, 대체할 수정 레이블은 파인튜닝한 BART 모델의 상위 예측값 이용. locality x는 독립적인 질문들을 샘플링
- FEVER fact-checking: equivalence neighborhood data는 fact rephrasing으로, 대체할 수정 레이블은 p=0.5의 베르누이 분포에서 랜덤 샘플링. locality x는 랜덤하게 추출
- Wikitext generation: GPT-style 모델을 평가하기 위해 직접 생성. 수정할 x는 Wikitext-103에서, 수정할 레이블은 사전학습된 distilGPT-2 모델로부터 10개 토큰 샘플링. locality x는 Wikitext로 사전학습된 모델의 경우 Wikitext-103에서, GPT-Neo/J는 OpenWebText에서 샘플링
- 평가결과
- 매우 큰 모델의 경우 MEND가 모든 태스크에 걸쳐 가장 좋은 성능 (GPT, T5 계열)
- 작은 규모의 경우 ENN이 MEND와 유사하게 좋은 성능을 보이나, ENN은 사전학습 모델을 수정가능하도록 변경하기 위해 fine-tuning 필요하다는 단점 (BERT, BART, distilGPT)
- batched editing(한 번의 모델 업데이트에 여러 개의 수정을 가할 시)의 경우 25개에 대해 96%의 성공과 1%의 정확도 저하가 발생 (ENN의 경우 35% 성공)
의의
- 모델의 에러를 수정한다는 중요한 문제를 다룸
- 이전의 유사한 연구들 대비 뛰어나며(superior) novelty가 있다는 평가 (from openreview)
- single input-output에 대해서도 model edit을 훌륭히 수행
- information-rich gradient를 rank-1 gradient로 사용해 모델 수정의 복잡성을 감소시킴 (자원효율적)
- GPT-style, T5와 같은 큰 모델에서도 사용 가능 (practical, competitive, lightweight) - 이전 연관 연구들은 이를 달성하지 못함
한계
- 적절한 eval 기준을 제시하였으나 이를 만족하는 eval metric이 다소 취약
- locality example(모델 수정 이후에도 결과가 동일하게 유지되어야 할 예시들)이 너무 단순, 더욱 어려운 hard negatives를 사용하여 평가 필요
- 유사한 데이터(equivalence neighborgood)들의 수집에 대해 더 다양한 방법 고민 필요(예: counterfactual data augmentation)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab