들어가며
- 자세한 수식보다는 Transformer에 대해 설명하고, 관련한 중요 키워드를 중심으로 초보자도 이해할 수 있도록 high-level 개념을 정리하는 데에 초점
자연어처리 (NLP)
- 자연어란 인간이 사용하는 언어를 의미
- 기계는 사람처럼 한글, 영어, 프랑스어 등의 자연어를 이해할 수 없기 때문에 인간의 언어를 컴퓨터가 이해할 수 있는 언어인 숫자로 바꾸고, 인간이 할 수 있는 다양한 작업 (예: 질의응답, 요약, 번역, 감정분류, 문장 내 빈칸에 들어갈 단어 맞추기, 다음에 올 문장 고르기, 글쓰기) 을 수행하도록 하기 위해 인공지능을 훈련
- 예전에는 RNN(Recurrent Neural Network)에 기반한 모델이 주를 이뤘으나, 요즘 성능이 좋은 대부분의 모델은 트랜스포머 기반
- RNN은 단순히 말해서 input으로 들어간 문장을 처음부터 순서대로 보면서 중요한 정보를 추출하고, 이를 output에 반영하는 모델
- RNN의 고질적인 문제는 문장이 길어질수록 앞에서 본 단어의 정보를 잊는다는 것
- 이를 해결하기 위해 RNN에 Attention이라는 메커니즘을 도입
- Attention은 단어(혹은 토큰)의 정보를 처리할 때 어떤 단어가 가장 중요한 정보를 가지고 있는가에 "주목"
- 단순한 예로 "I am a student"라는 문장을 "나는 학생입니다"라는 문장으로 번역하는 자연어처리 모델을 만든다고 할 때, Attention Mechanism은 output으로 "학생"이라는 단어를 만들기 위해 input으로 들어온 "student"에 주목
- Attention만 사용하는 Transformer의 등장 이후에는 BERT나 GPT처럼 Transformer의 아키텍처를 활용하여 엄청나게 많은 데이터를 사전학습(pre-train)하고, 그러한 모델을 fine-tuning하거나 few-shot learning하는 등 각 task의 용도에 맞게 살짝 재학습하여 사용하는 방식이 각광을 받았음
Transformer
Attention is all you need (link)
- RNN과 Attention을 결합하는 것이 아니라, Attention 자체로만 이루어진 모델
- 품질 우수/병렬화 가능/훈련시간 단축이라는 성과를 달성
Encoder-Decoder 구조
- 인코더는 input으로 들어온 자연어 시퀀스(예를 들어 문장)를 숫자형 표현(numerical representation)으로 바꿔줌
- 디코더는 인코더로부터 받은 표현(representations)을 우리가 이해할 수 있는 자연어의 형태로 변환
- 논문에서는 이를 "the encoder maps an input sequence of symbol representations to a sequence of continuous representations z. Given z, the decoder then generates an output sequence of symbols one element at a time."이라고 설명
- 직관적으로 이해하자면 input으로 들어온 문장이 가진 주요한 정보들을 추출하여 숫자형태로 만들어주고, 해당 정보를 기반으로 output text를 한번에 하나씩 생성
- 예를 들어 번역 task라면, "I am a student"라는 output을 한 번에 생성하는 것이 아니라 "I", "am", ... 이렇게 한 번에 하나의 단어를 생성
- 단 output을 생성할 때는 기존의 input 정보에 더하여 이전 단계에 생성된 단어(symbol)들도 추가적인 input으로 사용하는데, 이를 "auto-regressive"라고 칭함
아키텍처
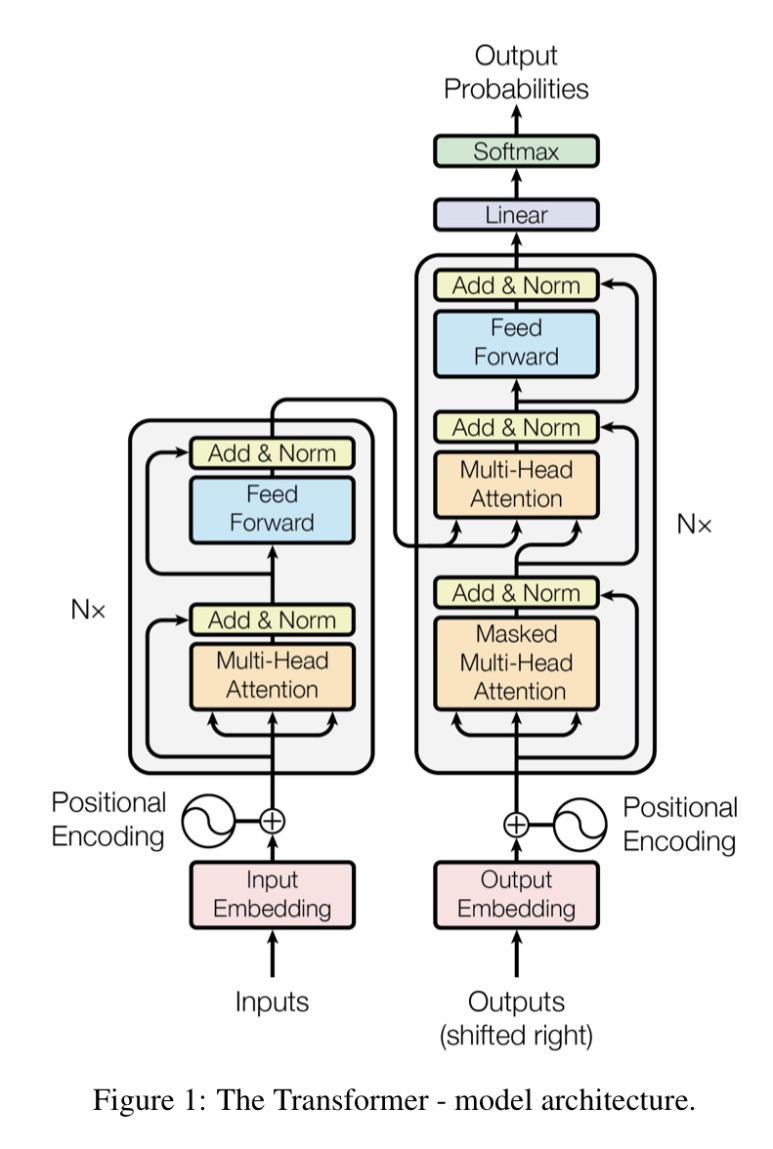
- Encoder
- 총 6개의 동일한 layer
- 각 layer는 안에 multi-head self-attention mechanism으로 만든 layer와 단순한 position-wise fully connected feed-forward layer, 총 2개의 sub-layer를 가짐
- 각 sub-layer에는 residual connection과 layer normalization을 사용했는데, 두 개의 기법은 딥러닝 모델의 성능을 향상하기 위해 자주 사용되는 방법
- Decoder
- 총 6개의 동일한 layer
- 각 layer 안에는 2개의 multi-head attention layer와 1개의 feed-forward layer, 총 3개의 sub-layer가 존재
- 인코더와 유사하게 residual connection과 layer normalization 또한 사용
- multi-head attention layer 중 하나는 인코더 스택의 결과에 대해 multi-head attention을 수행하는 부분(논문에서는 encoder-decoder attention layer라고도 칭함)이고, self-attention을 수행하는 sub-layer의 경우 masking을 사용해 해당 위치보다 뒤에 있는 정보들은 참고하지 않음
- 예를 들어 "I am a student"라는 문장을 output으로 만들려고 하고, 현재 모델이 생성할 단어의 위치가 "am"이라면, masked multi-head attention에서는 "I"라는 정보는 참고할 수 있지만 "am" 뒤에 나오는 "a"와 "student"라는 정보는 참고할 수 없음
- Attention
- Attention은 query와 key-value 쌍을 output에 매핑하는 것
- query와 key를 이용해 value의 가중합을 구함
- 이러한 가중합이 어떤 정보가 중요한지를 알려주는 지표
- Transformer에서는 다양한 어텐션 메커니즘 중에서 Scaled Dot-Product Attention을 사용
- 벡터의 내적을 사용한 dot-product attention을 통해 속도와 효율성을 추구
- 여기에 특정 값을 분모에 곱해 값이 너무 커짐으로써 발생할 수 있는 문제(예: extremely small gradient; gradient가 극단적으로 작아지면 모델이 중요한 정보를 놓칠 수 있음)를 방지
- Self-Attention (intra-attention)
- 하나의 "단일한" 시퀀스(예: 문장)에서 각기 다른 위치에 대해 어텐션 메커니즘을 적용
- 즉 자기 자신에 대해 어텐션을 수행
- attention mechanism relating different positions of a single sequence in order to compute a representation of the sequence
- Transformer 모델에서는 encoder-decoder attention layer와는 별개로 인코더와 디코더에 각각 self-attention layer를 포함
- total computational complexity per layer, amount of computation that can be parallelized, path length between long-range dependencies in the network를 고려하여 self-attention mechanism을 선택
- Multi-Head Attention
- 어텐션을 병렬로 여러 번 수행
- 모델의 전체 차원 크기만큼 어텐션을 한 번 적용하는 것보다는 더 작은 차원에서 병렬로 여러 번의 어텐션을 실행하고, 결과값들을 concatenate하고 project하는 것이 더욱 유리
- 유리하다는 것은 모델의 성능에 더 도움이 된다는 뜻
- 각기 다른 representation subspaces로부터 다양한 정보를 가져와 결합할 수 있기 때문
- Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions
- 이 논문에서는 8개의 병렬 어텐션 layer (=head)를 사용했으며, 각 head당 64차원의 연산을 수행했다. (즉, 전체 모델의 차원은 64*8차원)
- 이밖에도 Transformer는 시퀀스(예: 문장) 내 토큰(예: 단어)의 위치를 알려주는 positional encoding과 자연어의 의미와 문법을 함축하여 효율적인 수치(벡터) 형태로 표현한 embedding을 사용
Encoder (Autoencoding models)
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (link)
인코더 모델의 특징
- Self Attention
- 트랜스포머의 인코더처럼 self-attention mechanism을 이용
- Bi-directional (양방향성)
- context from the left and the right
- 다시 말해, 양쪽 문맥의 정보를 모두 사용
- 예를 들어 “I (빈칸) a student”라는 문장이 있을 때, (빈칸)은 왼쪽에 있는 “I”와 오른쪽에 있는 “a student”라는 정보를 모두 참고
- NLU(Natural Language Understanding)
- 단어 사이의 관계나 상호의존성을 이해하는 데에 특화
- Masked Language Modeling
- 문장 속에서 특정 부분을 빈칸으로 만들고 정답을 추측하는 문제
- 예: “I (빈칸) a student”
- target(목표한 결과값)은 원래의 문장, 즉 “I am a student”가 주어지고 input은 “I (빈칸) a student”처럼 corrupted version 사용
- 보통은 사전학습(pretraining) 동안 랜덤하게 마스킹
- 많은 인코더 모델들이 MLM 방식으로 학습
- 대표적인 활용사례
- sequence classification
- question answering
- masked language modeling
BERT 개요
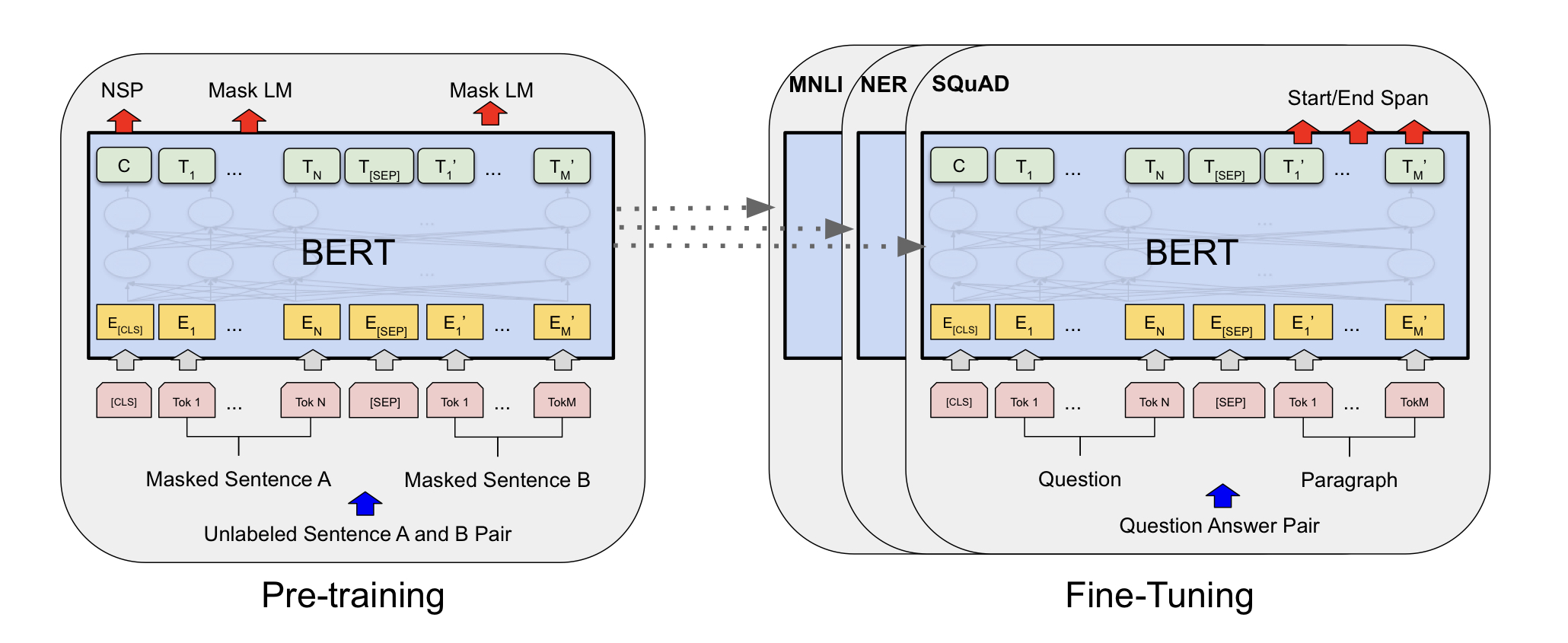
- unlabeled text에서 컨텍스트를 양방향으로 고려한 representation을 사전학습
- 사전학습한 모델을 fine-tune하여 다양한 자연어 태스크를 수행할 수 있도록 만든 모델
- 사전학습을 통해 언어의 representation, 즉 언어의 정보를 풍성하게 이해하고 있는 거대한 모델은 약간의 학습과 일부 데이터만 있다면 다양한 downstream task를 잘 수행
- 사람으로 치자면 어렸을 적부터 책을 많이 읽은 아이가 조금만 공부하고 노력하면 국어 시험도 잘 보고, 논술도 잘 하고, 토론도 잘하고, 면접도 잘 보는 등 언어에 관련한 다양한 태스크들을 다 잘 수행하는 것과 유사
- BERT는 파인튜닝을 거쳐 다른 task를 수행하려고 할 때에도 별도의 변경 없이 하나의 통일된 아키텍처를 사용한다는 장점을 가짐
BERT 학습방법
- MLM (Masked Language Model)
- input의 토큰(예: 단어) 일부를 랜덤하게 가리고 해당 위치에 들어갈 토큰 찾기
- NSP (Next Sentence Prediction)
- 특정 문장 다음에 이어질 문장을 예측
Decoder (Autoregressive model)
Improving Language Understanding by Generative Pre-Training (link)
디코더 모델의 특징
- Masked Self Attention
- 트랜스포머의 디코더처럼 masked self-attention mechanism 사용
- Unidirectional (단방향성)
- context only from the left
- 다시 말해, 왼쪽 방향의 문맥만 참고
- 예를 들어 “I am a student”라는 문장을 output으로 만들고 싶다고 할 때, “am”이라는 단어의 위치에서는 “I”의 정보만을 활용 (“a student”는 접근 불가)
- NLG(Natural Language Generation)
- 언어를 생성해내는 태스크에 특화
- Causal Language Modeling
- 위에서 설명한 auto-regressive, masked self-attention, unidirectional과 모두 맞닿아있는 개념
- 순서대로 텍스트를 읽고 다음에 나올 단어를 예측하는 사전학습 태스크에서, 미래에 등장할 토큰(예: 단어)은 가려놓음
- 디코더 모델을 학습할 때 자주 사용
- 대표적인 활용사례
- text generation
GPT 개요
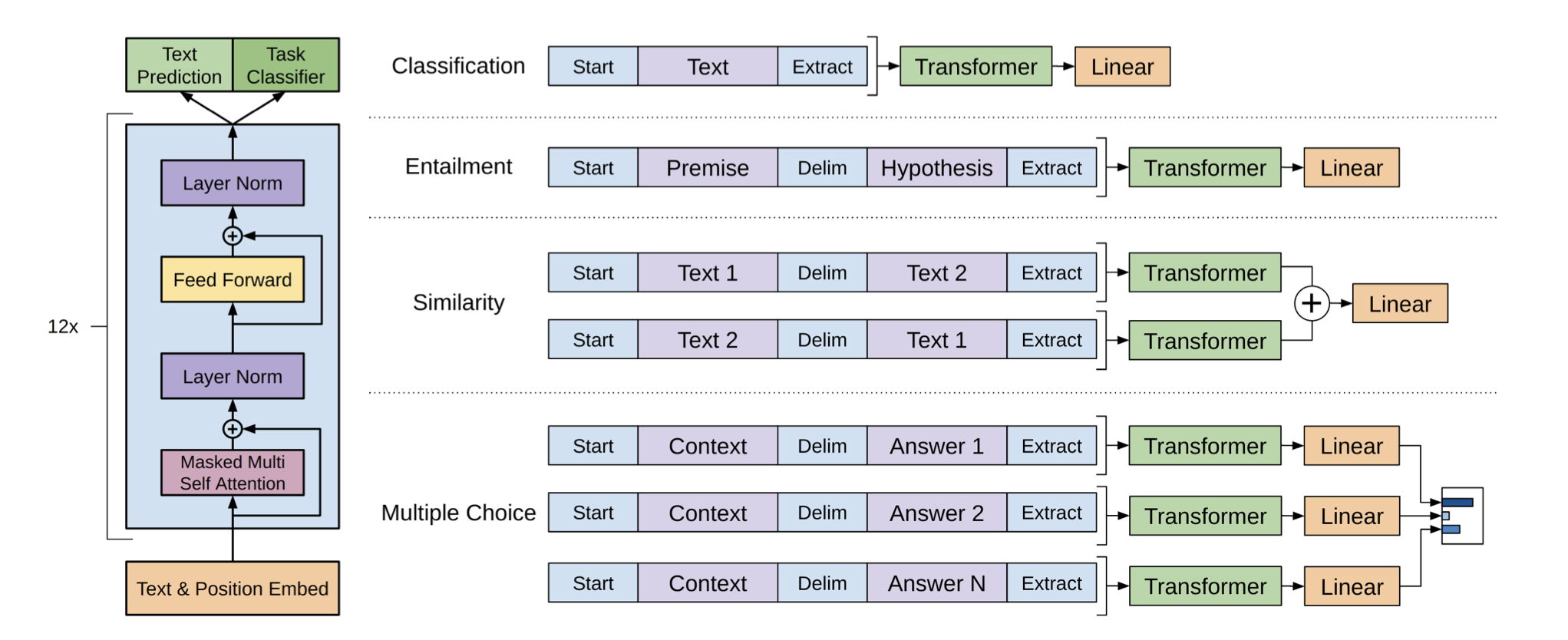
- 디코더 구조를 활용한 대표적인 모델
- GPT는 다양한 unlabeled text에 대해 generative pre-training을 수행 (unsupervised pre-training)
- BERT와 마찬가지로 각각의 특정 태스크에 대해 fine-tuning을 통해 원하는 성능을 달성 (supervised fine-tuning)
- fine-tuning 시에 auxiliary objective(additional training objective or task that is learnt along with primary learning objective to improve the performance of models by making them more generic)로 language modeling(주어진 단어로부터 아직 모르는 단어를 예측)을 포함
- 이를 통해 일반화 성능을 개선하고 수렴을 가속화
- 수렴을 가속화했다는 건, 오류를 더욱 빨리 줄이고 최적의 답을 더욱 빨리 찾아냈다는 의미
- fine-tuning 시에 auxiliary objective(additional training objective or task that is learnt along with primary learning objective to improve the performance of models by making them more generic)로 language modeling(주어진 단어로부터 아직 모르는 단어를 예측)을 포함
- 초창기의 GPT는 특정 태스크를 수행하기 위해 약간의 수정을 필요로 함
- 이를 위해 traversal-style approach를 사용
- 사전학습된 모델이 처리할 수 있는 ordered sequence로 structured input을 변환하는 방식
- 이러한 input transformation을 통해 태스크마다 아키텍처가 크게 달라지는 것을 피할 수 있었음
- 이를 위해 traversal-style approach를 사용
Encoder-Decoder (Sequence-to-Sequence model)
- numerical representation을 만드는 인코더와 representation과 prompt를 활용해 text를 생성하는디코더를 함께 사용하는 모델
- 디코더의 경우 뒤로 갈수록 디코더에서 생성한 정보들도 input으로 사용
- sequence to sequence(many to many) task에 주로 활용
- 번역이나 요약 태스크에 강점
인코더-디코더 모델의 특징
- 인코더와 디코더 사이에 weight가 반드시 공유될 필요는 없음
- 현실을 잘 모사할 수 있는 weight를 학습해야 딥러닝 모델의 성능이 우수
- input distribution과 output distribution이 다를 수 있으며, input length와 output length는 서로 독립적
- translation language modeling, transduction model과 깊이 연관
- 대표적인 모델
- BART, T5
관련 링크 1: HuggingFace Transformers (link1, link2)
관련 링크 2: 딥러닝을 이용한 자연어처리 입문 (link)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab