On Reinforcement Learning and Distribution Matching for Fine-Tuning Language Models with no Catastrophic Forgetting
deep-reinforcement-learning
목록 보기
11/11
On Reinforcement Learning and Distribution Matching for Fine-Tuning Language Models with no Catastrophic Forgetting
NeurIPS 2022
분야 및 배경지식
강화학습 (Reinforcement Learning)
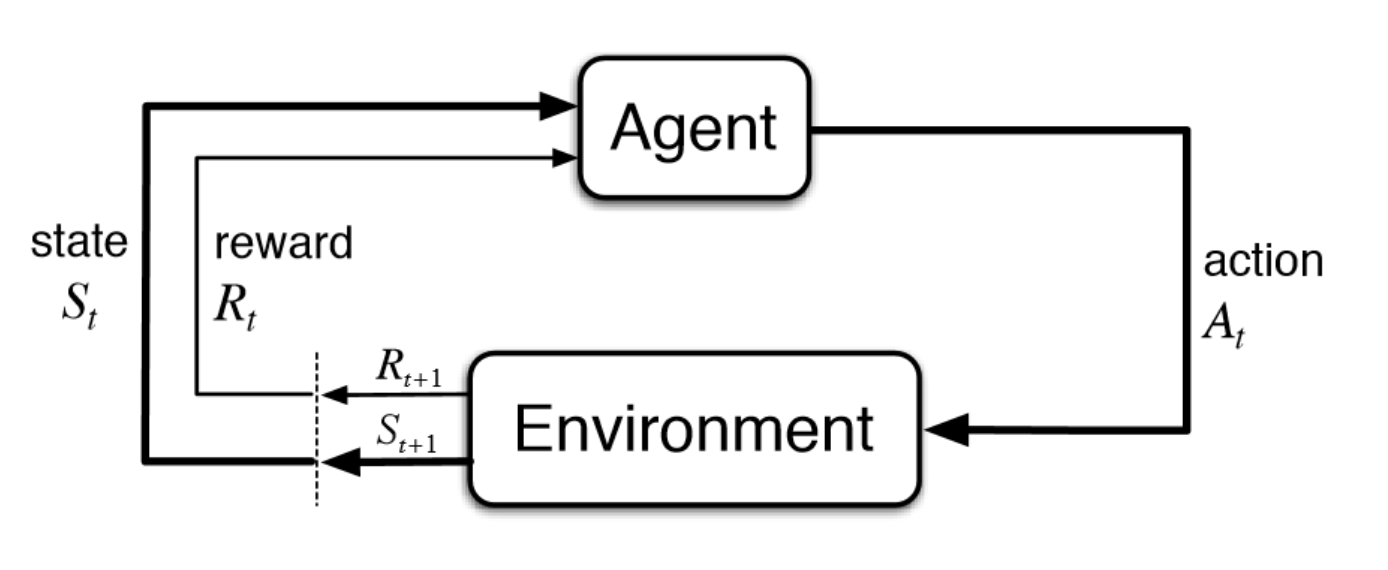
- agent로 하여금 최적의 보상을 얻을 수 있는 최적의 행동 전략을 찾도록 하는 학습 방식
- 관련 개념 및 용어 (link)
- Environment: agent가 작동하는 물리적 세상
- State: agent의 현재 상황
- Reward: 환경(environment)로부터 오는 피드백; 보상
- Policy: agent의 상태/상황(state)과 행동을 연결짓는 방법
- Value: 특정 state에서 어떤 행동을 취함으로써 agent가 받을 수 있는 미래의 보상
문제점
- 처음부터 새로운 분포를 학습(e.g. train from scratch)하는 게 아닌 사전학습된 분포(e.g. pretrained model)를 원하는 다른 분포를 갖도록 학습하는 fine-tuning 방식이 최근 주를 이룸
- 이를 위해 Reward Maximization (RM), Distribution Matching (DM)이라는 두 가지 다른 강화학습 패러다임이 등장하였으나, 이 둘 사이의 관계를 파악하는 연구는 부족
해결책 (Contribution)
- 두 가지 다른 강화학습 패러다임의 비교분석 (Reward Maximization, Distribution Matching)
Reward Maximization
- 방법: reward signal을 점진적으로 증가
- 모델이 바람직한 특징을 만족하는 output을 생성할 때 시퀀스 단위의 reward를 제공
- 하지만 단순히 보상을 최대화하는 방식으로 학습한다면 기존의 분포를 완전히 잊게 되는 catastrophic forgetting 문제가 발생할 수 있음
- 이를 해결하기 위해 Reward Maximization with KL penalty 등장
- 사전학습된 언어모델(LM)로부터 KL divergence를 최소화함과 동시에 reward를 최대화
- 최대화시켜야 할 reward 안에 distributional term을 통합
- gradient: policy gradient (PG) (참고할 링크: link1, link2)
- Standard Policy Gradient
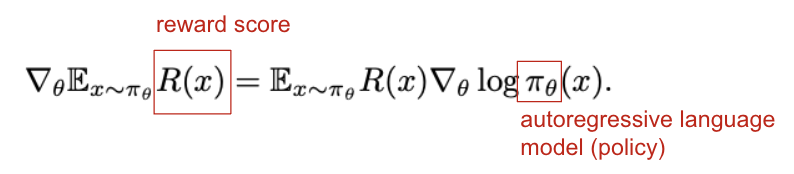
- 평균 보상을 최대화하는 policy(=model)를 찾고자 함
- policy(=model)로부터 x를 반복적으로 샘플링하고 파라미터를 업데이트하는 gradient ascent algorithm으로, 대표적으로 REINFORCE가 있음
- KL-control
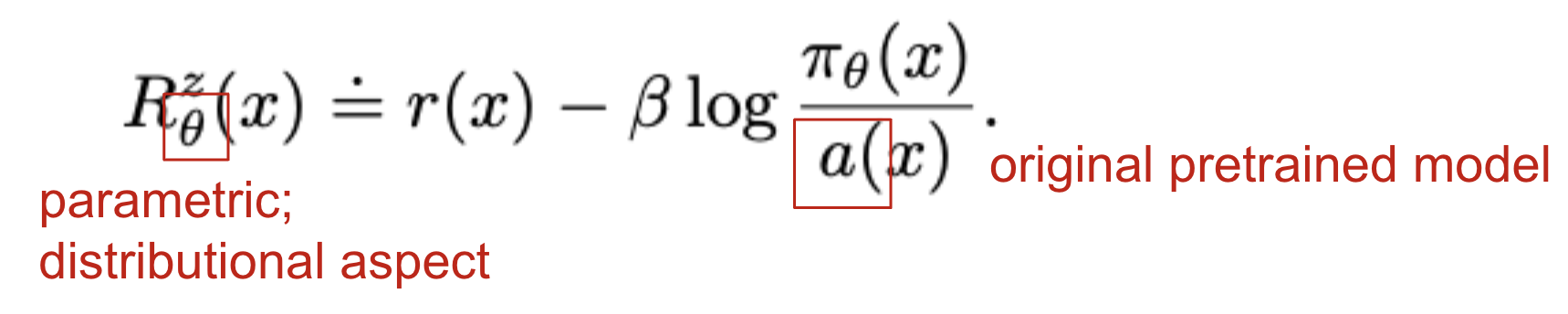
- 기존의 사전학습 언어모델(PLM)로부터 너무나 큰 변화가 일어나지 않도록 reward function에 KL penalty term을 포함
- RM에 KL penalty가 추가됨으로써 distributional aspect가 생김
- Standard Policy Gradient
- 한계: 분포적 제약(distributional constraint)을 걸 수 없음 (보상은 하나의 시퀀스에 대해서만 계산됨)
- 분포적 제약 e.g. 전체 생성 시퀀스 중 50%의 시퀀스(문장)에 여성 관련 언급을 포함해라
Distribution Matching
- 방법: 모델이 유사하게 파인튜닝할 명확한 타겟 분포를 생성
- 먼저 Energy-Based Model(EBM; 타겟 분포를 특정하기에 flexible)을 활용하여 desired preference를 포함하는 타겟 분포를 형성
- 이후 타겟 분포와 auto-regressive policy(=language model) 사이의 KL divergence를 최소화하는 방향으로 학습 진행
- gradient: distributional policy gradient (DPG)
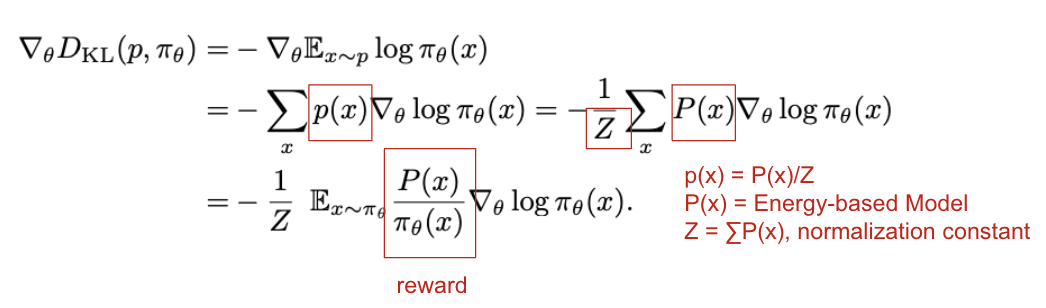
- autoregressive policy(=model; π)를 타겟 분포인 p(x)에 맞춤
- DPG는 loss function D-KL(p, π)을 최적화하여 π=p에 대해 loss가 최소화되도록 함
- 한계: RM에 비해 DM 계열의 알고리즘 연구가 부족
- 두 패러다임(RM, DM)을 연결지을 수 있는 Findings
KL-control as Distribution Matching
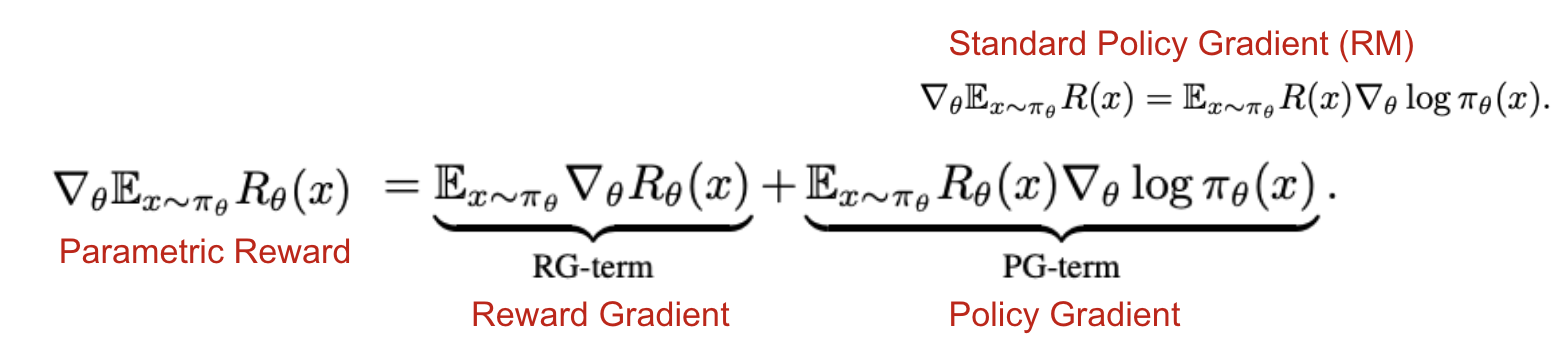
- RM에 KL-penalty term을 추가함으로써 reward가 parametric reward가 됨
- RM에서 RG-term은 사라지기 때문에, 결과적으로는 Standard Policy Gradient과 유사한 형태가 됨 (KL-control이 RM 패러다임에서 이해되는 이유)

- 하지만 이는 또한 DM으로도 이해될 수 있는데, 제한적 형태의 p(x) 분포에 대한 reverse KL divergence를 최소화하는 수식으로도 표현할 수 있기 때문
- reverse라고 명명한 이유는 본래 DM의 DPG는 D-KL(p, π) 순서이나 RM with KL penalty의 경우는 D-KL(π, p) 순서로 표현할 수 있기 때문
DM can benefit from RM variance reduction techniques
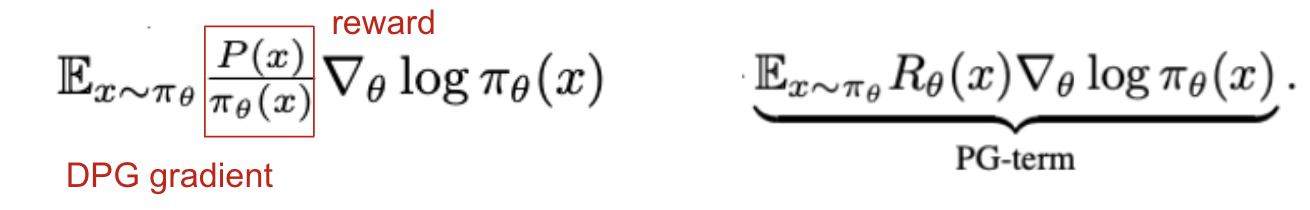
- RM with KL penalty를 DM으로 이해한 것처럼, DM을 RM으로 표현하고자 했으나 이는 어려움을 증명
- 하지만 Distributional Policy Gradient(DPG)가 RM의 Standard Policy Gradient(SPG)와 유사한 PG-term의 형태를 띈다는 것을 보였으며, SPG와 유사하게 높은 variance 문제를 겪는다는 사실을 보임
- 이와 같은 발견을 토대로 RL에서 variance를 낮추기 위해 고안되었던 기존의 방식들을 DM에 적용해보고자 함
- 강화학습의 baseline 기법을 DM에 적용
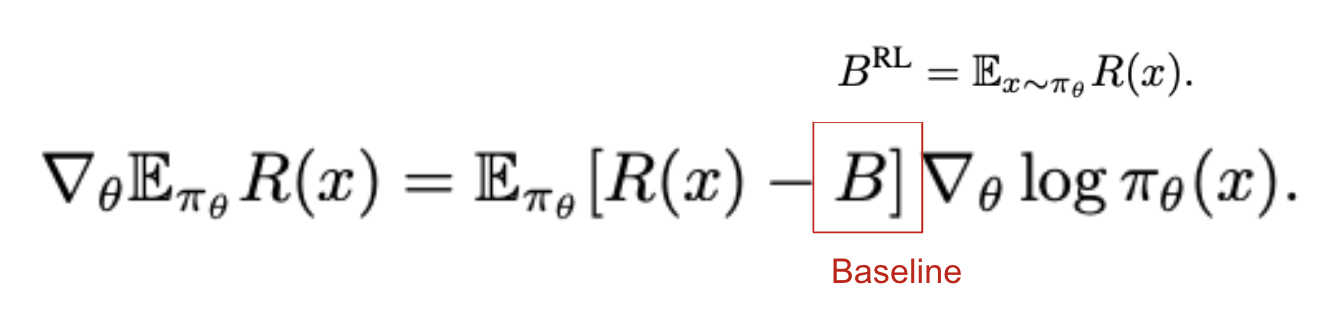
- baseline이란 policy gradient에서 variance를 줄여주는 기법 중 하나
- reward R(x)로부터 value B를 빼는 것이 bias를 더하지는 않지만 variance에 변화를 줄 수 있다는 사실이 수식적으로 증명됨 (link)
- 일반적으로 평균값이 사용되는데, 이를 DPG에 적용하면 B=Z가 되고, off-policy DPG에 적용하면 B=Z*importance weight (π(x)/q(x)) 형태가 됨
- off-policy: evaluate and improve a policy that is different from Policy that is used for action selection (target policy != behavior policy)
- on-policy: evaluate and improve the same policy which is being used to select actions (target policy == behavior policy) (link)
평가
- 비교대상 모델
- GDC; Generation with Distributional Control: 특정 제약을 만족하도록 DPG를 활용하여 사전학습된 언어모델의 특징을 컨트롤하는 모델
- 이 밖에도 REINFORCE, Ziegler 사용
- 모델 (GDC++; GDC + DPG baseline)
- 제약 (constraints)
- pointwise: 단일 생성 문장 내에 단일 단어 포함 or 단어 리스트 중 한 단어 포함 or 특정 감정 포함
- distributional: 전체 생성 문장 중 일정 비율에 대해 female figure 언급을 포함 or 단어리스트에 있는 단어를 포함
- hybrid: pointwise + distributional
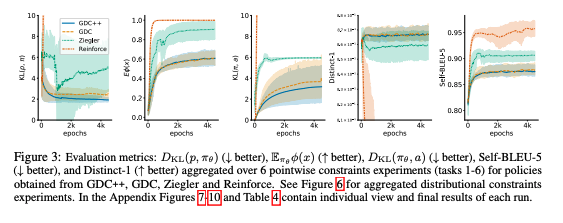
- GDC, GDC++가 다른 모델들에 비해 제약조건을 더욱 잘 만족하고, 기존 사전학습 언어모델로부터 deviation이 덜 하며, 문장 생성에 있어 중요한 조건인 diversity를 더 잘 만족
- GDC++가 GDC에 비해 제약조건을 더욱 잘 만족하고, divergence가 더 적으며, 학습 안정성이 높음. 이는 특히 batch size가 작을 때 더 뚜렷하게 보임
- 작은 배치 사이즈에서 안정적인 학습 = 샘플 효율성이 더 좋음
- GDC++가 GDC에 비해 variance가 더 적으며, 최적의 분포에 대해 더 나은 convergence를 보임
한계
- Openreview에서도 딱히 논문의 한계를 지적하기보다는 관련 내용에 대한 clarification, example 요청 등이 주를 이룸
의의
- 기존의 강화학습 패러다임 사이의 연결관계를 깊이있게 고찰하고 수식으로 이를 증명
- 강화학습의 관점에서 사전학습 언어모델의 파인튜닝을 연구하는 비교적 새로운 분야
- 논문뿐만 아니라 소스코드 또한 굉장히 깔끔하게 작성되어 있어 이해에 도움
- DPG에 variance를 줄이는 baseline을 포함한다는 주장의 타당성이 잘 드러나며 증거도 충분

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab