HuggingFace Deep RL Course - 8. Proximal Policy Optimization (PPO)
deep-reinforcement-learning
목록 보기
10/11
강의 링크: https://huggingface.co/learn/deep-rl-course/unit8/introduction
PPO (Proximal Policy Optimization)
- 너무 큰 policy update를 방지함으로써 에이전트의 학습 안정성을 개선
- 경험적으로 비추어볼 때 policy를 조금씩 업데이트하는 것이 최적의 결과로 수렴할 가능성이 높음
- 너무 큰 policy update로 인해 잘못된 policy로 업데이트 된다면 복구가 오래 걸리거나 불가능할 수 있음
- 현재 policy와 이전 policy 사이의 차이 비율을 [1−ϵ,1+ϵ]로 제한
Clipped Surrogate Objective Function
Policy Objective Function

- Reinforce를 최적화할 때 사용했던 Policy Objective Function
- gradient ascent를 이용해 해로운 행동(action)을 피하고 더 높은 보상(reward)을 야기하는 행동을 취하게 함
- 하지만, step size의 문제가 있을 수 있음
- step size가 너무 작으면 학습이 너무 느림
- step size가 너무 크면 학습에서의 변동성이 너무 큼
Clipped Surrogate Objective Function

- 가중치 업데이트가 너무 크지 않은 방향으로 진행되도록 clip을 활용해 policy 변화를 제한
- ratio function * advantage로 log probability를 대체 (r_t(theta)Ahat_t)
- 하지만 제약 없이는 과도한 policy update로 이어질 수 있음
- ratio를 1에서 너무 멀어지지 않도록 제약이 필요 (clip)
- 이를 통해 policy가 너무 과하게 업데이트되지 않도록 제한할 수 있음
- TRPO(Trust Region Policy Optimization)을 이용해 KL divergence를 활용할 수도 있으나, 이는 실행이 복잡하고 더 많은 연산 시간을 소모
- 최종적으로 clipped objective와 unclipped objective 사이의 최소값을 활용
- unclipped objective의 lower bound (=pessimistic bound)

- 현재 policy에서 상태 s_t에서 행동 a_t를 선택할 확률을 이전 policy에 대한 확률로 나눈 값
- 다시 말해, 현재 policy와 이전 policy 사이의 비율을 나타냄
- ratio가 1보다 크면 상태 s_t에서 행동 a_t의 확률이 이전 policy보다 현재 policy에서 더 높음
- ratio가 0과 1 사이면 위와 반대 상황
Clipped Surrogate Objective Function 시각화
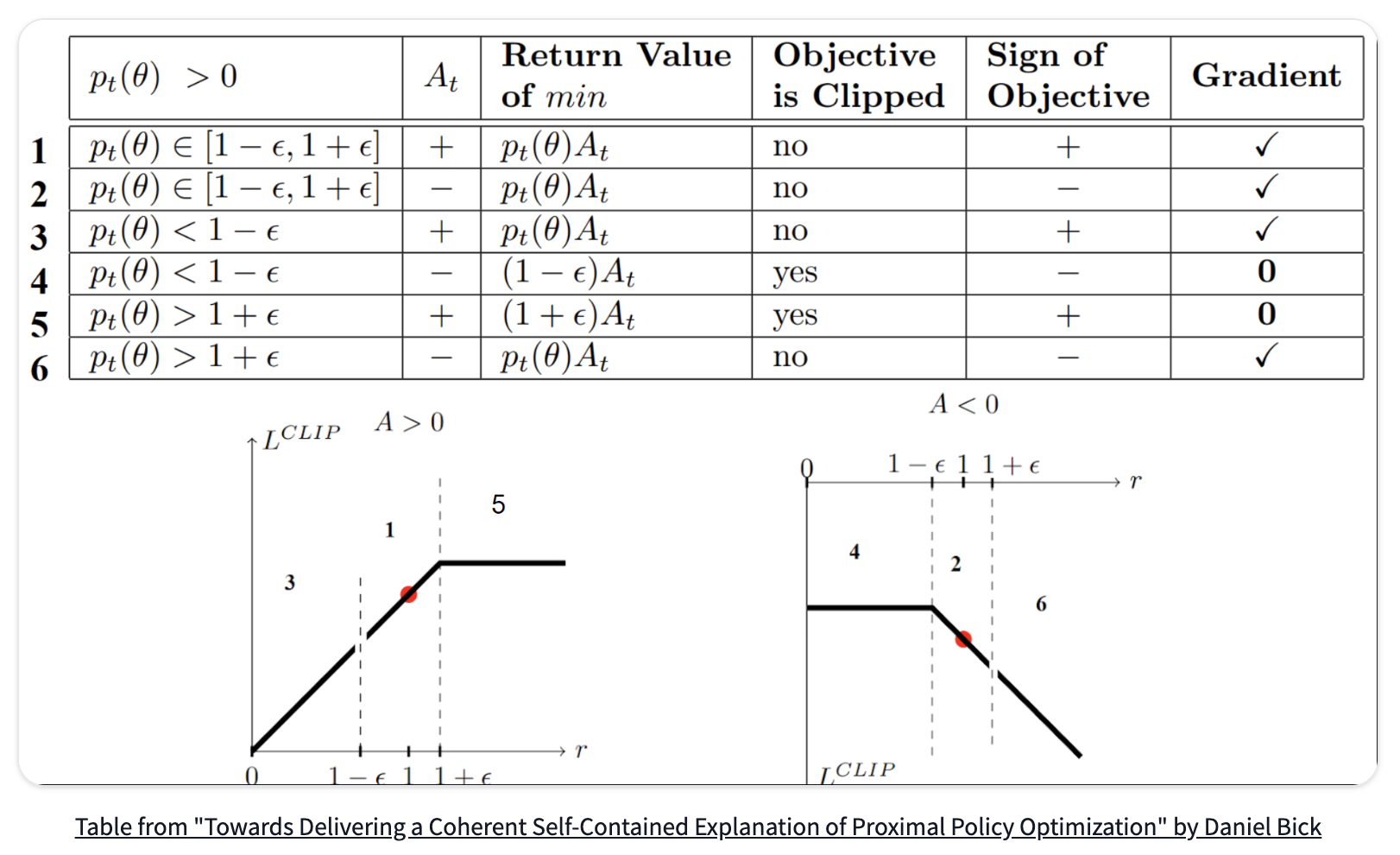
- case 1
- clip 범위 안에 위치하기 때문에 clipping 없음
- advatange가 양이라는 건, 해당 상태에서의 모든 action의 평균보다 해당 action이 더 낫다는 것
- state에서 해당 action을 선택할 policy의 확률을 증가시켜야 함
- case 2
- clip 범위 안에 위치하기 때문에 clipping 없음
- advantage가 음이라는 건, 해당 상태에서 모든 action의 평균보다 해당 action이 좋지 않다는 것
- state에서 해당 action을 선택할 policy의 확률을 감소시켜야 함
- case 3
- 확률 비율이 [1−ϵ]보다 작다는 건 이전 policy에서보다 해당 행동을 선택할 확률이 낮다는 것
- advantage가 양이기 때문에 해당 행동을 취할 확률을 증가시켜야 함
- case 4
- 확률 비율이 [1−ϵ]보다 작다는 건 이전 policy에서보다 해당 행동을 선택할 확률이 낮다는 것
- advantange가 음이기 때문에 더 감소할 필요 없이 gradient = 0을 취함 (clip)
- case 5
- 확률 비율이 [1+ϵ]보다 크다는 건 이전 policy에서보다 해당 행동을 선택할 확률이 높다는 것
- advantage가 양이긴 하지만 너무 Greedy한 것은 원하지 않기 때문에 gradient = 0 취함 (clip)
- case 6
- 확률 비율이 [1+ϵ]보다 크다는 건 이전 policy에서보다 해당 행동을 선택할 확률이 높다는 것
- advantage가 음이기 때문에 해댱 행동을 취할 확률을 감소시켜야 함
PPO's Actor Critic


Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab