Parameter-Efficient Transfer Learning for NLP
ICML 2019
분야 및 배경지식
- Pretrained text representation
- 사전학습된 텍스트 representation은 자연어처리 태스크의 성능을 높이기 위해 널리 사용됨
- 거대한 코퍼스 데이터를 기반으로 representation이 학습되며, 이는 downstream task에서 feature로 사용되고 fine-tuning되기도 함
- 처음부터(from scratch) 학습하는 것보다 pretrained word embedding을 사용하는 것이 더욱 뛰어난 성능을 보임
- 사전학습된 텍스트 representation은 자연어처리 태스크의 성능을 높이기 위해 널리 사용됨
- Fine-tuning
- 사전학습된 모델을 이용, 원하는 목표 태스크에 맞게 파라미터를 다시 학습하는 방법
- 일반적으로 모델의 전체 파라미터에 대한 재조정이 일어남
문제
- 거대한 사전학습 모델을 다양한 태스크에 활용하는 방법으로 finetuning이 널리 활용되나 이는 비효율적(parameter inefficient)
해결책
Adapter-BERT
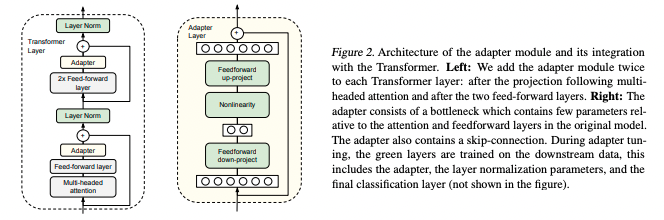
- Adapter
- 태스크마다 학습가능한 파라미터(=a few trainable parameters, adapter)를 BERT의 Transformer layer마다 추가
- 다른 태스크에 해당하는 어댑터와 사전학습된 모델의 공유되는 파라미터는 고정, 오직 추가되는 어댑터에 대해서만 학습
- 어댑터는 bottleneck architecture로 구성되어 파라미터의 개수를 제한
- 다양한 형태의 아키텍처를 실험, 단순한 Adapter 구조가 많은 데이터셋에 대해 충분히 좋은 성능을 낸다는 것을 확인
평가
- 데이터셋
- GLUE를 포함한 26개 텍스트 분류 데이터셋
- 파인튜닝 대비 1.14%에 해당하는 파라미터를 사용해 파인튜닝과 유사한 성능을 보임
의의
- 전체 파라미터에 대해 학습하는 기존 파인튜닝과 유사한 성능을 내면서도 훨씬 더 작고 확장성이 좋음
- 단일 모델로 여러 태스크 처리 가능, compact and extensible downstream model
- 실험을 통해 아래와 같은 사실을 밝힘
- 1) 각각의 어댑터가 전체 네트워크에 미치는 영향은 작으나, 함께 사용되었을 때 전체적인 효과가 큼
- 2) higher layer가 lower layer에 비해 더 중요

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab