[Prompt Tuning] The Power of Scale for Parameter-Efficient Prompt Tuning
parameter-efficient-finetuning
목록 보기
2/7
The Power of Scale for Parameter-Efficient Prompt Tuning
EMNLP 2021
분야 및 배경지식
- prompt
- soft prompt = continuous prompt
- 벡터 형태로 표현된 프롬프트
- hard prompt = discrete prompt
- 사람이 이해할 수 있는 자연어 형태로 이루어진 프롬프트
- soft prompt = continuous prompt
문제점
- Model tuning(=fine-tuning)의 한계
- 모델의 파라미터 전체를 업데이트함으로써 모델의 일반화 성능을 떨어뜨리고, 각 태스크마다 별도의 모델을 필요로 함으로써 학습 비용을 증대
- Prompt design의 한계
- 텍스트 프롬프트는 오류가 발생하기 쉽고 사람이 직접 만들어야 함
해결책
Prompt Tuning
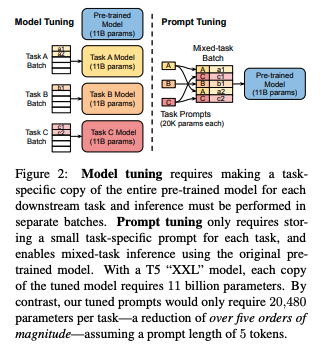
- 언어모델은 고정(freeze)
- 특정 downstream task에 대한 soft prompt를 학습
- 인풋 텍스트 앞에 몇 개의 학습 가능한 토큰을 붙여서 사용(prepend)
평가
- 모델: T5
- T5의 경우 문장 내 일부 span을 만들고 이를 예측하는 식의 학습을 진행 (span corruption)
- GPT와 같은 autoregressive한 사전학습이 진행되지 않았기 때문에 프롬프트 성능 측정을 위해 아래와 같은 세팅 실험
- 1) Span corruption
- e.g. "Thank you for inviting me to your party last week"와 같은 문장이 있다면, input을 "Thank you [X] me to your part [Y] week"로, output을 "[X] for inviting [Y] last [Z]"로 설정 후 학습
- 2) Span corruption + sentinel
- downstream target 앞에 sentinel을 붙임
- 3) LM adaptation
- 언어모델 목적함수를 활용하여 T5를 추가학습 (약 100K step)
- Span corruption은 프롬프트와 사용했을 때 좋은 성능을 내지 못함 (LM adaptation 필요)
- 1) Span corruption
- 데이터셋
- SuperGLUE
- 프롬프트 초기화(initialization)
- 1) 임의로 초기화
- 2) 모델의 단어사전의 임베딩 활용
- 3) 분류 태스크의 경우, 아웃풋 클래스의 임베딩 활용
- 3번이 가장 좋은 성능을 보이나, XXL 크기의 모델은 어떤 초기화를 사용하는지가 크게 중요치 않음
- 프롬프트 길이
- 1, 5, 20, 100, 150
- 약 20개의 토큰까지는 성능이 향상되다가 그 이후로는 미미하게 증가
- XXL 모델의 경우 토큰 하나만 사용하더라도 좋은 성능을 보임
- Baselines (일부만 정리)
- Prefix-tuning
- 모든 레이어의 activation에 prefix를 붙여서 학습
- BART, GPT-2 모델 활용
- prefix의 안정화를 위해 reparameterization을 활용함으로써 파라미터 추가
- P-tuning
- 사람이 디자인한 패턴에 기반해 embedded input에 연속적인 프롬프트가 interleave되어 학습
- SuperGLUE에서 좋은 성능을 내기 위해서는 모델 튜닝과 함께 학습되어야 함
- Prefix-tuning
의의
- 모델의 크기가 커질수록 (e.g. XXL 사이즈) 프롬프트 길이, 프롬프트 초기화 방식, 사전학습 목적함수에 크게 구애받지 않고 좋은 성능을 보임
- 모델의 원래 파라미터는 고정하고 추가적인 파라미터만 학습함으로써 효율적으로 학습 비용을 줄임과 동시에 모델의 일반화 성능을 유지
- 프롬프트 앙상블을 통해 성능을 높일 수 있음을 보임
- 비록 continuous prompt이기 때문에 해석가능성(interpretability)이 떨어질 수 있지만, top-k nearest neighbor로 분석한 결과 output class와 유사한 지점에서 프롬프트 학습이 이루어짐을 보임
- 프롬프트의 역할 중 하나가 input이 어떠한 도메인이나 문맥에 해당하는지 해석하는 게 아닌가 추측함
한계
- 모델의 크기가 커짐에 따라 프롬프트의 길이, 초기화 방식 등이 큰 영향을 미치지 않는데, 이를 통해서 볼 때 과연 좋은 성능이 prompt tuning method의 영향인지 모델 크기 때문인지 판단하기 어려움

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab