PromDA: Prompt-based Data Augmentation for Low-Resource NLU Tasks
PromDA: Prompt-based Data Augmentation for Low-Resource NLU Tasks
ACL 2022
분야 및 배경지식
Data Augmentation, Synthetic Data Generation
- Prompt Learning
- GPT3의 등장 이후 few-shot setting(데이터가 몇 개만 주어지는 경우)에서 특정 태스크를 수행할 수 있도록 LM에 쿼리를 날릴 수 있는 prompt가 대두
- 사전학습 언어모델(pretrained language model)을 더욱 잘 활용할 수 있는 prompt에 대한 연구 활발
- 사람이 직접 작성한 discrete prompt에 대한 연구
- 실제 단어에 대응되지 않는 학습 가능한 벡터로 이루어진 soft prompt
- Generative Data Augmentation
- Language Model(LM), Pre-trained Language Model(PLM)을 활용하여 새로운 synthetic data를 생성
문제
- 적은 수의 labeled data만이 존재하는 low-resource 자연어이해(NLU) task를 위해 data augmentation 필요
- small training data로 pretrained language model을 활용해 synthetic data를 생성하는 것은 overfitting 야기
- generated synthetic data가 본래의 데이터와 유사
해결책
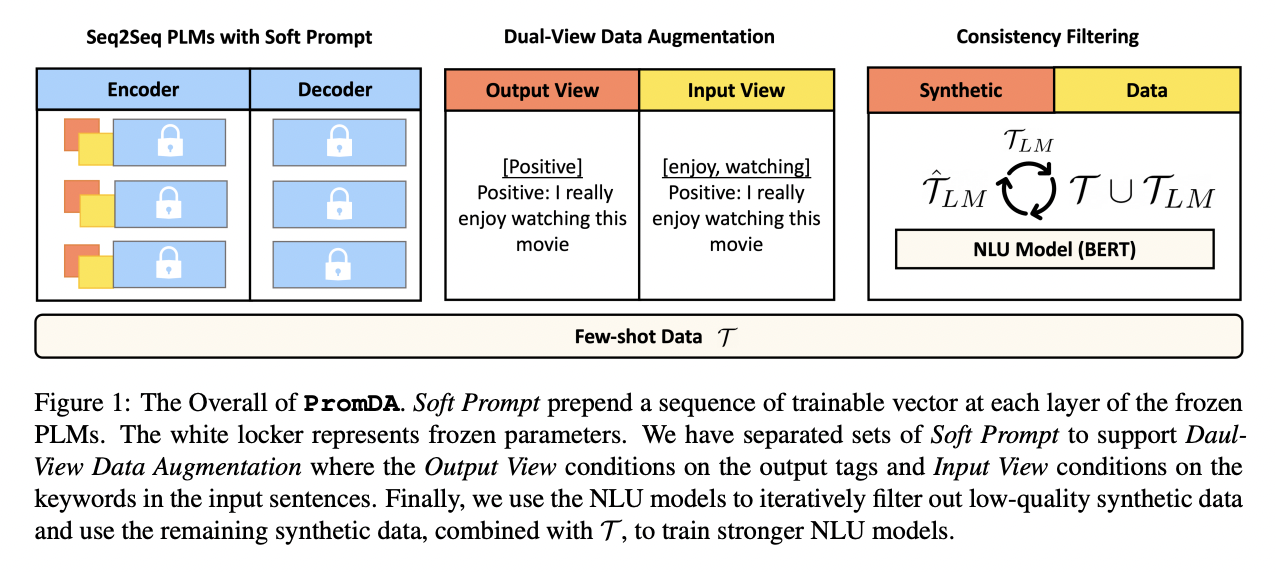
Prompt-based Data Augmentation (PromDA)
- Soft Prompt
- pretrained model 전체를 freeze, 추가적인 soft prompt에 대해서만 fine-tuning
- soft prompt란, 자연어로 이루어진 task instruction과 달리 학습 가능한 연속적인 일련의 벡터를 의미
- a sequence of continuous and trainable vectors
- Task-agnostic Synonym Keyword to Sentence
- prompt parameters를 pre-training corpora에 대해 pre-train함으로써 파라미터를 초기화
- Rake 알고리즘을 사용해 keyword 추출을 진행
- WordNet을 이용해 키워드의 일부를 유의어로 대체한 후 원래의 text chunk를 reconstruct하는 방식으로 soft prompt를 학습
- Dual-View data augmentation
- Input Veiw에서는 문장의 키워드를 중심으로 synthetic data 생성
- Output View에선 문장의 label을 중심으로 synthetic data 생성
- 생성한 data를 각각 Output View, Input View에 교차하여 사용하는 방식으로 data의 diversity 높임
- NLU Consistency Filtering
- NLU 모델을 사용해 생성된 data의 label을 예측하게 한 뒤 PromDA와 NLU 모두 동일한 output을 내는 경우에만 데이터 유지
의의
- Data Augmentation을 위해 고안된 Soft Prompt를 활용한 최초의 PLM
- PromDA로 만든 synthetic data로 정답이 없는 (unlabeled) in-domain data 보완 가능
- human effort 감소

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab