긴 프롬프트의 한계
- RAG, Chain-of-Thought, In-Context Learning 등은 프롬프트의 길이를 늘리는 경향에 일조
- 프롬프트가 길 경우
- API 응답의 latency가 증가하며
- 모델이 인풋으로 받아들일 수 있는 context length를 초과할 수 있고
- 컨텍스트 중간의 정보를 무시하는 lost in the middle 현상이 발생할 수 있음
01. LLMLingua
- Microsoft의 프롬프트 압축 연구 (깃헙 링크, 사이트 링크)
- GPT2-small, LLaMA-7B 등의 작은 모델을 활용해 불필요한 토큰을 제거하고 프롬프트를 압축하고자 하는 연구
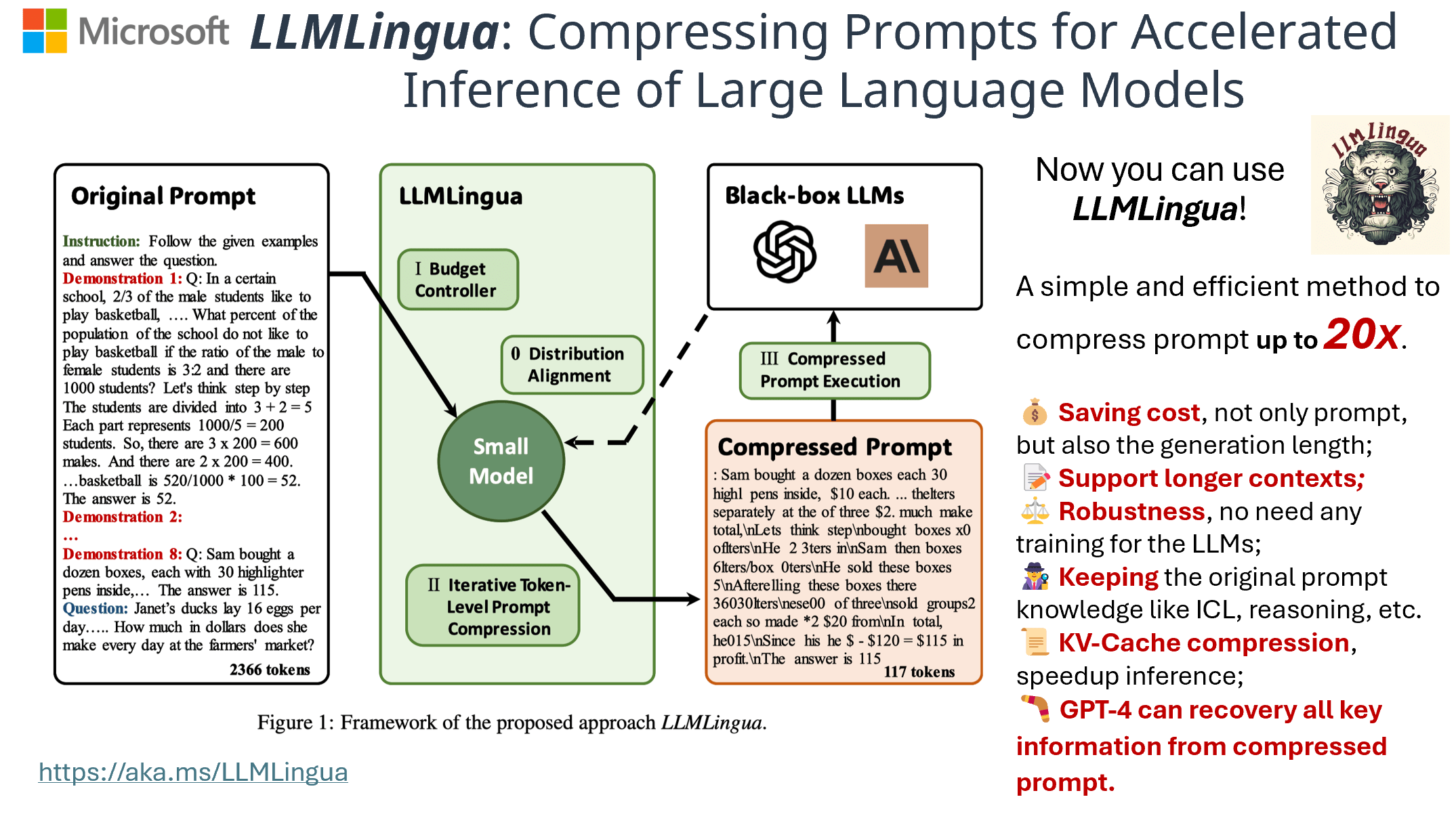
- LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models (paper link, EMNLP 2023)
- 성능 하락을 최소화하면서 약 20배의 프롬프트 압축률을 달성
- 프롬프트의 각기 다른 부분(e.g. instruction, question, ...)에 각기 다른 압축률을 적용 (coarse) + 토큰 단위로 순회하며 정밀하게 압축 (fine)
- 프롬프트 압축 시 Alpaca-7B 혹은 GPT2-Alpaca 모델 사용
02. LongLLMLingua
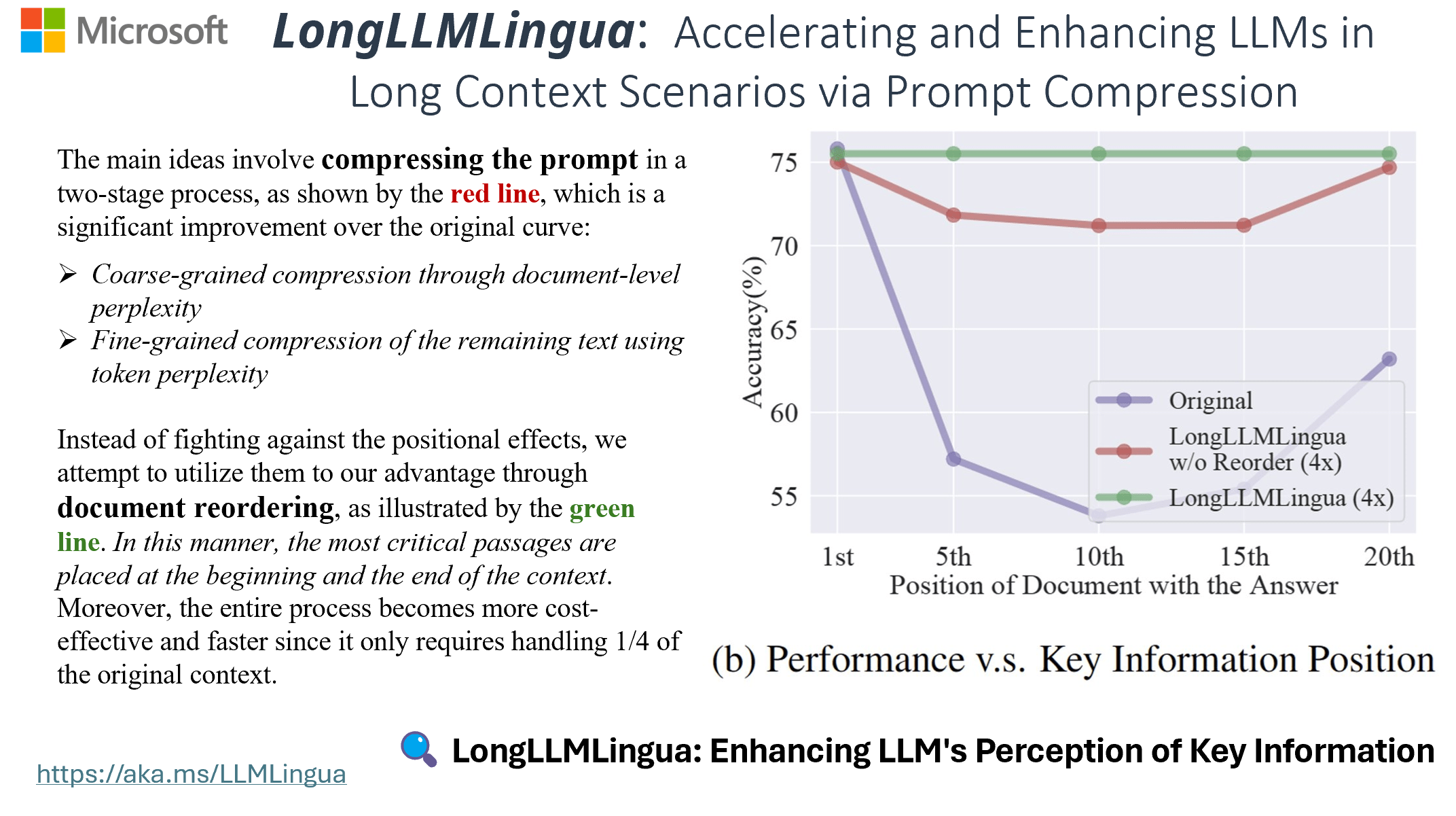
- LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression (paper link, ACL 2024)
- 약 4배 더 적은 토큰으로 17% 이상의 성능 향상
- 프롬프트 (질문) 내의 핵심 정보를 더욱 잘 인식하여 성능을 개선 + 문서 순서 재배치 + 압축 후 핵심 정보의 정합성을 보장하기 위한 복구 전략 등 제안
- 프롬프트 압축 시 LLaMA-2-7B-Chat 사용
- Langchain 코드 (링크)
from langchain.retrievers import ContextualCompressionRetriever
from langchain_community.document_compressors import LLMLinguaCompressor
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)
compressor = LLMLinguaCompressor(model_name="openai-community/gpt2", device_map="cpu")
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)- 만약 논문에서 소개한대로 Llama-2-7b-chat 모델을 사용하고 싶다면, model_name='NousResearch/Llama-2-7b-chat-hf'처럼 사용 가능
- 관련해 설정할 수 있는 파라미터는 해당 링크 참고
한국어에서의 성능
- 프롬프트 압축을 위해 작은 모델인 Llama-2-7b 등을 사용했다고 하는데, 영어에 특화된 모델이기 때문에 한국어 프롬프트 압축에는 한계 존재
- 핵심적인 중요한 정보를 삭제하거나
- 말이 되지 않는 방식으로 압축
- Llama-3 70B도 사실상 한국어 성능이 굉장히 떨어지는 만큼, 예견된 결과
- tokenizer가 달라서인지, 한국어를 추가적으로 파인튜닝한 Llama-2-7b 모델들 지원 불가

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab