검색한 문서의 순위를 바꾸는 Reranker (Cohere, RankGPT, Cross Encoder Reranker)
retrieval-augmented-generation
목록 보기
9/17
RAG (Retrieved Augmented Generation)에서 발생하는 문제 (참고)
- 벡터 검색을 통해 쿼리와 관련된 문서를 반환할 때, 관련된 정보의 검색이 어려울 수 있음
- 반환되는 문서의 개수를 늘리면 관련된 문서를 찾아올 확률이 높아지나, 이는 비용 효율적이지 않음
- 또한 관련 정보가 검색된 문서의 포함된 여부가 아닌, 관련 정보가 컨텍스트 내 상위에 위치하고 있을 때 더욱 좋은 답변을 얻을 수 있음
- Lost in Middle: 질문에 관한 문서가 컨텍스트 중간에 위치할 경우, LLM 응답 정확도가 낮아짐
Reranker
- 질문과 문서 사이의 유사도를 더욱 정교하게 측정할 수 있음
- 다만 검색 시간이 오래 걸리기 때문에, 1. 기본 검색 실행 2. 검색된 문서 대상으로 관련성 재측정 (by Reranker)의 두 단계가 바람직
01. Cohere Reranker
- 쿼리와 문서들이 주어지면 의미론적 유사성을 바탕으로 문서를 재정렬
- rerank-english-v3.0, rerank-multilingual-v3.0, rerank-english-v2.0, rerank-multilingual-v2.0 모델 존재 (링크)
- v3의 경우, 아래와 같은 특징을 가짐 (링크)
- 4k context length
- 다양한 구조의 데이터 지원 (이메일, 송장, JSON 문서, 코드, 테이블)
- 100개 이상의 다국어 지원
- v3의 경우, 아래와 같은 특징을 가짐 (링크)
- Langchain 구현 코드 (링크)
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_cohere import CohereRerank
from langchain_community.llms import Cohere
llm = Cohere(temperature=0)
compressor = CohereRerank(model="rerank-english-v3.0")
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke(
"What did the president say about Ketanji Jackson Brown"
)
pretty_print_docs(compressed_docs)02. RankGPT
- Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents (paper link, github link, EMNLP 2023)
- LLM의 관련도 랭킹 성능을 탐구한 논문
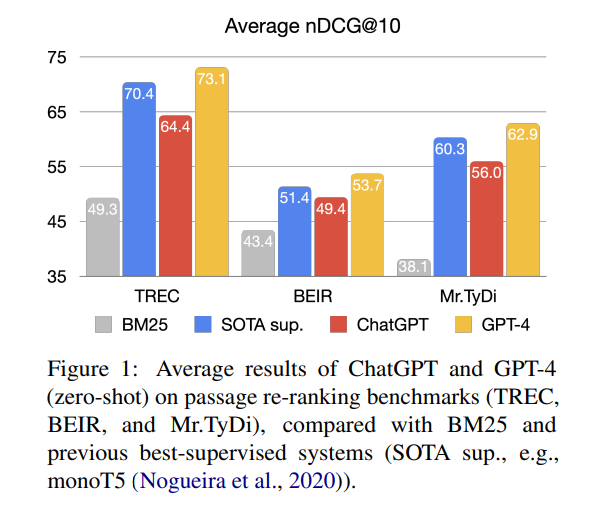
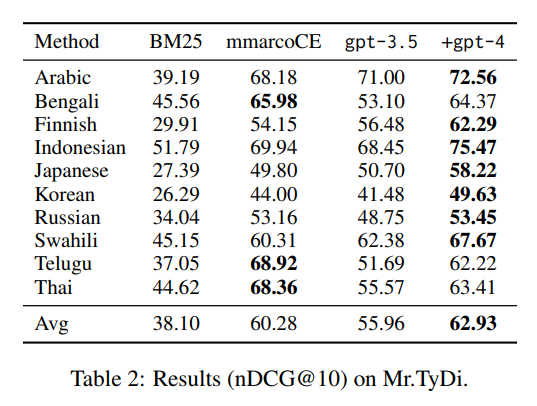
- GPT-4가 평가 데이터셋 전반에 걸쳐 가장 좋은 성능
- Langchain 구현 코드 (링크)
from langchain.retrievers.contextual_compression import ContextualCompressionRetriever
from langchain_community.document_compressors.rankllm_rerank import RankLLMRerank
compressor = RankLLMRerank(top_n=3, model="gpt", gpt_model="gpt-3.5-turbo")
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)- 만약 Azure OpenAI를 사용하고 싶다면
- gpt_model에 배포(deployment)명 작성
- 환경변수 OPENAI_API_TYPE="azure"
- 환경변수 OPENAI_API_KEY="azure openai key"
03. HuggingFace cross encoder models as Reranker
- HuggingFace를 통해 사용할 수 있는 오픈소스 cross encoder 사용 가능
- Langchain 구현 코드 (링크)
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CrossEncoderReranker
from langchain_community.cross_encoders import HuggingFaceCrossEncoder
model = HuggingFaceCrossEncoder(model_name="BAAI/bge-reranker-base")
compressor = CrossEncoderReranker(model=model, top_n=3)
compression_retriever = ContextualCompressionRetriever(
base_compressor=compressor, base_retriever=retriever
)
compressed_docs = compression_retriever.invoke("What is the plan for the economy?")
pretty_print_docs(compressed_docs)한국어 데이터에 대한 성능 테스트 시 느낀 점
- Reranker가 문서 검색 성능을 높여줄 것이라는 기대와 달리, 성능이 향상되는 경우와 저하되는 경우가 공존
- 검색 문서의 수를 늘리고, Reranker가 순위를 다시 매기고 일부 문서만 선택하는 과정에서 오히려 잘 검색된 문서를 제외시키는 경우도 존재
- Cross Encoder 기반 방식의 본질적인 한계인지, multilingual reranker의 한계인지 확인 필요
- 한국어로 파인튜닝된 리랭커 활용 시 성능이 올라가는 현상 확인
- 더 많은 데이터셋/태스크에 대해서 일반화 가능한 결론인지 확인 필요

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab