TempLM: Distilling Language Models into Template-Based Generators
TempLM: Distilling Language Models into Template-Based Generators
arXiv 2022
분야 및 배경지식
- 사전학습 모델의 맹점
- 신뢰성이 낮은 결과나 부적절한 응답을 생성하는 경우 존재
- e.g. hallucination; 그럴듯한 거짓말
문제점
- 사전학습 언어모델(PLM)은 유창하지만 신뢰성이 떨어지거나 부적절한 내용을 생성하기도 함
- 특히 학습 때 보지 않은 OOD(out-of-domain) 인풋에 대해서 오류의 경향성이 커짐
- 고전적인 템플릿 기반의 시스템은 유창성은 떨어지지만 신뢰도가 높은 내용을 생성하곤 함
해결책
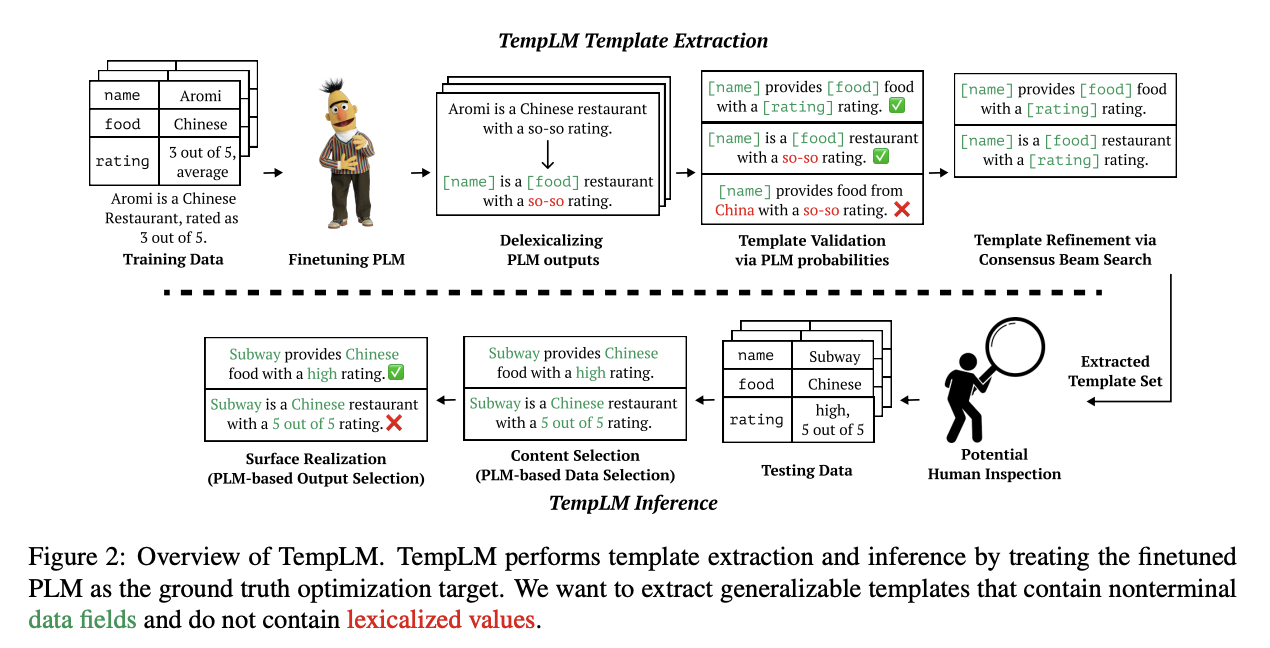
TempLM: Template-Based Generators
- 사전학습 모델을 data-to-text 태스크를 위한 템플릿 기반의 시스템으로 distill
문제 정의
- 인풋 데이터는 field와 value로 구성
- e.g. input = {name: [Aromi, aromi], article: [a, an]}
- name, article이 field, Aromi, aromi, a, an이 value
- 한 field에 여러 개의 value 가능
- 템플릿은 일련의 terminal token과 nonterminal field로 구성
- e.g. The restaurant name is [name]
- 일반화 가능한 템플릿 (generalizable template) 탐색
- 2단계의 최대화(maximization) 문제로 나누어 해결
- template extraction (템플릿 추출)
- 주어진 예산 내에서 최고의 템플릿 셋을 식별
- template inference (템플릿 추론)
- 템플릿 셋 내에서 최고의 템플릿 식별
템플릿 추출 (template extraction)
- 군집화 (clustering)
- 주어진 인풋(d)에 대한 최적의 템플릿 인덱스(i)를 제공하는 군집화 함수를 가정 (C(d)=i)
- 최적의 군집화 함수를 찾는 것은 불가능하기 때문에 근사한 군집(cluster)를 디자인
- 주어진 인풋(d)에 대한 최적의 템플릿 인덱스(i)를 제공하는 군집화 함수를 가정 (C(d)=i)
- 사전학습 언어모델의 결과를 delexicalize
- 사전학습 언어모델이 생성한 문장에 있는 value를 field를 사용해 추상화
- e.g. Aromi is a Chinese restaurant with a so-so rating -> [name] is a [food] restaurant with a so-so rating
- 사전학습 언어모델 확률을 통해 템플릿 확인 (validation)
- 앞선 과정은 좋은 템플릿의 시작점을 만드는 과정
- 해당 과정은 그 중 일반화 가능성이 높은 템플릿들을 평가
- 사전학습 언어모델의 확률을 사용해 군집(cluster) 내 top-K 템플릿 선별
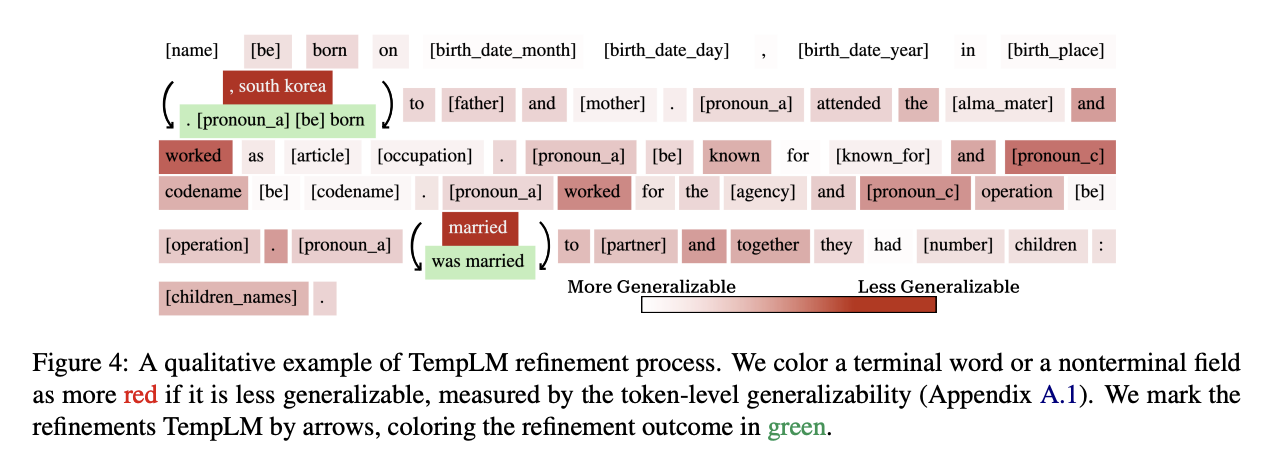
- consensus beam search를 통한 템플릿 정제 (refinement)
- 템플릿이 몇 개의 lexicalized value를 가질 시 일반화가 어려운 부분을 대체
- 일반화가 어려운 부분(span)을 채우는 것은 infilling model을 이용
- infilling model은 nonterminal data field를 생성하도록 학습
- 여러 인풋의 log probability score를 합침으로써 공통의 아웃풋을 탐색
템플릿 추론 (template inference)
- 템플릿 추출을 통해 얻은 템플릿 셋 중, 새로운 인풋에 대한 최적의 템플릿을 유추
- content selection
- nonterminal field를 여러 개의 value 중 가장 적절한 value로 대체
- surface realization
- 템플릿이 채워진 후 가장 적절한 아웃풋을 선택
평가

- 데이터셋 (data-to-text task)
- E2E
- SynthBio
- 모델
- BART-base
- 평가기준
- 유창성: BLEU, NIST, ROUGE-L, CIDEr, METEOR, BERTScore
- 신뢰성: E_precision
의의
- 사전학습 언어모델의 유창성과 기존의 템플릿 기반 시스템의 신뢰성을 결합
- OOD 데이터에 대해서 unfaithful output rate을 83% 에서 0%로 줄임
한계
- 낯선 용어나 표현이 많으나 이에 대한 충분한 설명이 부족
- Figure 없이 글 내용만으로 TempLM을 이해하기 어려움
- data-to-text 태스크에 한정된 방식으로, 다른 태스크로의 확장이 어려움

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab