The Inductive Bias of In-Context Learning: Rethinking Pretraining Example Design
The Inductive Bias of In-Context Learning: Rethinking Pretraining Example Design
ICLR 2022
분야 및 배경지식
사전학습(pre-training)
- dataset: 모델이 처리할 수 있는 연속적인 텍스트 덩어리(chunk) 활용 (huge unlabeled text data)
- objectives: Language modelling (예를 들어 masked language modeling, next word prediction 등)
문제점
- 이전 연구들은 network expressivity를 판단할 때 오직 in-context representation만을 고려 (sequential representation에 대한 고려 X)
- 이전 연구들은 사전학습의 성능 향상을 고려할 때 데이터를 추가하거나 더욱 정교한 목적함수(training objectives)를 찾는 데에 주안점을 둠
해결책
in-context bias
- 같은 학습 데이터 안에 있는 정보(=in-context representation)는 다른 학습 데이터 사이의 정보(=sequential representation)보다 더 잘 표현됨(더 높은 의존성을 가짐)
- information within pretraining examples is better represented than information integrated across pretraining examples
이론적 증명: ε-separation rank
- separation rank: a measure of a multivariate function's ability to correlate two subsets of its variable set. deep convolutional, recurrent and self-attention 네트워크의 dependency를 측정하기 위해 만들어짐
- ε-separation rank: 저자들이 새로 고안해낸 effective separation rank. 같은 input에 담기지 않은 문장들은 다른 문장을 weight을 통해서만 참조하게 되는데, 작은 learning rate 때문에 정보를 통합하는 것이 어려움을 증명
- 두 문장을 다른 학습 예시가 아니라 같은 학습 예시에 사용했을 때, 네트워크의 깊이를 약 6 레이어 정도 증가하는 것과 같은 효과를 보임
실험적 증명: kNN-TAPT(Task Adaptive PreTraining), kNN-pretraining
- kNN-TAPT: 일반적인 코퍼스로 사전학습 후 SentEval 문장들(task) + 위키피디아의 연관문장(general)으로 사전학습. 문장의 유사성 평가. neighbors + in-context일 경우 성능 향상이 가장 높게 일어남
- kNN-Pretraining: 일반적인 코퍼스로 사전학습 진행 후 일반적인 사전학습 예시 절반 + kNN 예시 절반 (50:50 batch integration)으로 사전학습 추가 진행. 점수 자체는 낮으나 kNN-pretraining 이후 성능이 유의미하게 향상
- 의미적으로 연관성이 높은 이웃이 아닌 문장들(=semantically related non-neighboring sentences)을 같은 사전학습 예시에 포함하는 것이 성능 향상에 주효함 (learning rate를 키울 수는 없으니까)
평가
- Task: SentEval sentence similarity, zero-shot open domain question (closed book)
한계
- kNN-TAPT를 활용해 문장의 유사성을 판단하는 태스크의 경우 단순히 sanity check가 아닌지 의문 (similarity가 높은 위키피디아 문장을 추가했으니, 관련하여 정보량이 많아졌기 때문에 성능이 올라간 게 아닐까? downstream task로써 유의미한 결과인지?)
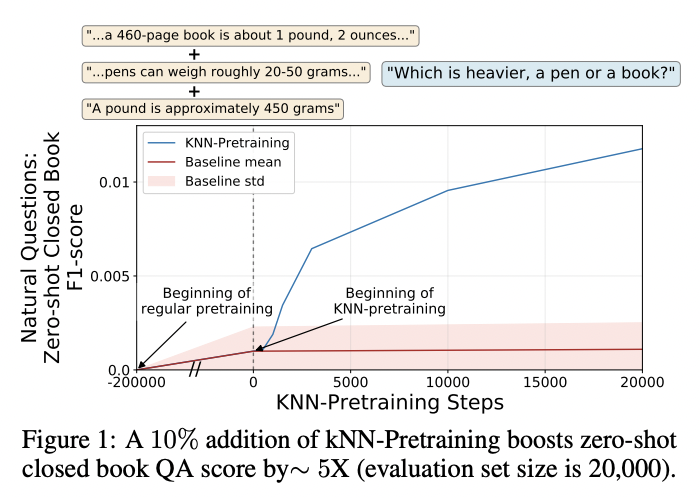
- 저자들은 kNN-pretraining 진행 시 그래프가 유의미하게 상승한다고 주장하나 기본적으로 성능이 워낙 낮기 때문에 유의미한 변화인지 의문 (zero-shot closed book task는 기본적으로 너무 어려운 태스크)
- sentence similarity, zero-shot closed book task 이외에 다른 다양한 태스크에 대한 실험결과 필요
의의
- in-context bias를 수식(이론), 실험을 통해 증명
- 학습과정동안 보여진 예시들에 대해 네트워크가 얼마나 expressive한지라는 새로운 형태의 network expressivity 질문을 제기 (same training exampels, different training examples)
- 동일한 데이터와 동일한 목적함수를 가지고, 사전학습 코퍼스를 어떻게 분배하는가에 따라 사전학습 성능이 달라진다는 새로운 관점을 제기 (학습 예시 디자인에 대한 새로운 관점)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab