Imputing Out-of-Vocabulary Embeddings with LOVE Makes Language Models Robust with Little Cost
ACL 2022
분야 및 배경지식
word embeddings, out-of-vocabulary, contrastive learning
- 단어 임베딩: 단어를 벡터로 표현(represent)하는 방법. 학습 시 사용된 단어들의 빈도 등을 활용해 고정된 크기의 단어사전을 만드는데, 실제 세상에서 사용되는 언어 코퍼스는 단어사전에 있는 단어들보다 훨씬 노이즈가 많고 단어사전에 없는(Out-Of-Vocabuluary) 단어들을 포함
- OOV: 학습 시 형성되는 단어사전에 포함되지 않은 단어들. 예를 들어 빈도가 적은 단어, 도메인 특화 단어, 속어, 오타 포함 단어 등
- FastText: OOV를 해결하기 위한 방법 중 하나로, skip-gram model에 글자(character) n-gram을 결합. OOV를 n-gram 벡터를 더함으로써 표현. 하지만 처음부터 사전학습 필요하여 많은 메모리 및 비용 소모
- MIMICK, BoS, KVQ-FH 등 (MIMICK-like): OOV 해결 방법 중 하나. 사전학습된 임베딩으로부터 학습함으로써 단어의 surface form만을 활용해 OOV 벡터 생성. 하지만 많은 양의 데이터를 활용해 adapted transformer를 사전학습해야 함
- Word corrector: downstream model 이전에 단어 교정기(word corrector)를 위치시키는 방법. 하지만 단어 교정기에서 발생한 오류가 downstream task로 전파될 가능성 존재
- Contrastive learning: 양의 상관관계를 갖는(positive) 쌍은 서로 가까이 위치시키고 상관관계가 없는(negative) 쌍은 멀리 떨어뜨리는 방식으로 label이 없는 데이터로부터 representation을 학습하는 방법. 주로 positive pair는 동일 샘플의 증가(augmentation)을 통해 만들며 negative pair는 미니배치 안 다른 샘플들을 활용해 만듦
문제점
- 자연어처리 시스템은 input을 단어의 임베딩으로 표현하는데, 단어사전 밖에 있는 단어들(out-of-vocabulary; OOV)에 대해서는 제대로 처리하지 못함
- Mimick-like model: 단어의 surface form, 즉 알려진 임베딩의 행동을 모방함으로써 OOV 단어의 임베딩을 만드는 방식. 단어사전에 포함된 단어 벡터와 포함되지 않은 단어 벡터 사이의 거리를 최소화하는 방식으로 학습 (거리는 유클리드 거리 혹은 코사인 유사도를 활용해 측정)
해결책
LOVE (Learning Out-of-Vocabulary Embeddings)
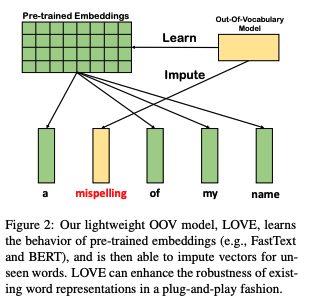
- Contrastive Learning Framework
- 목표(target)와 생성된 벡터 사이의 유사도를 최대화하고, negative pair는 멀리 떨어뜨려놓는 방식 활용
- positive pairs: positive pair 중 하나(target vector)는 사전학습된 임베딩으로부터 얻어지며, data augmentation을 이용해 해당 target vector의 변형(corruption) vector 생성
- 가벼운 Positional Attention Module과 5개의 새로운 단어수준(word-level) 증강기법(augmentation) 적용
- 어려운 negative(상관관계 없는 샘플)를 학습에 이용하는 것이 더 좋은 representation을 만들 수 있음
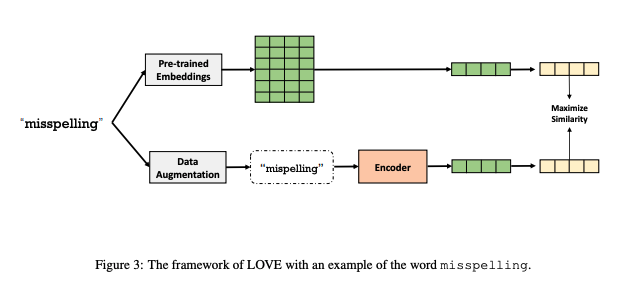
- Framework details
- input: BERT와 같이 WordPiece 사용, subword와 character sequence 모두 이용. 모든 단어를 stem(어근 제거)해 단어의 기본형만을 유지
- encoder: local feature와 global feature를 모두 인코딩해야. local feature는 character n-gram을 활용해 작은 변화(예: 글자 순서 변경 혹은 생략)에도 강건하도록 도와주며, global feature는 거리에 상관없이 local feature를 결합
- Positional Attention Module 고안: positional attention(for local) 적용 후 conventional self-attention(for global) 활용. positional attention에는 absolute sinusoidal embedding
- loss: contrastive loss 활용. alignment(positive pair 사이의 거리(유사도)), uniformity(초구(hypersphere; 3차원보다 큰 차원으로 확장한 것)에 학습된 representation이 균등하게 분포되었는지)라는 두 개의 중요 특성을 최적화
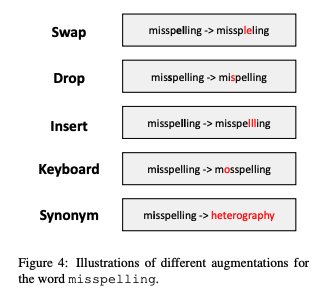
- data augmentation and hard negatives
- data augmentation(데이터 증강): 학습 샘플의 다양성을 증가시키기 위해, 1) 인접한 두 글자 교환(swap) 2) 글자 삭제 3) 새로운 글자 삽입 4) 키보드 거리 기준으로 글자 교체 5) 동의어로 교체. 5번의 경우 의미적으로 유사한 단어들이 임베딩 공간에 가까이 위치할 수 있도록
- hard negatives: negative pairs는 미니 배치로부터 랜덤하게 선택되나, 비슷한 surface form을 가지나 다른 의미를 가진 단어들과 같이 어려운 예시들을 활용(예: misspelling and dispelling)
- mimick dynamical embeddings: mimicking distilled embeddings가 근소한 차이로 더 나은 성능
- mimicking input embeddings: multi-layer attention 이전에 BERT의 input embedding(static representation)으로부터 학습
- mimicking distilled embeddings: 여러 문장들에 있는 단어의 contextual embedding을 pooling(average or max)함으로써 학습
- plug and play: 연결 즉시 사용할 수 있다는 의미
- static word embedding을 사용하는 모델(예: FastText): 바로 사용 가능
- dynamic word embedding을 사용하는 모델(예: BERT): 단일 단어가 여러 개의 부분으로 토크나이즈되면 OOV 단어로 가정, attention layer 이전에 LOVE로 생성한 단일 embedding을 사용
평가
- Intrinsic: 단어들 사이의 구문적(syntactic), 의미론적(semantic) 관계를 직접적으로 평가
- 단어 유사도(similarity): RareWord, SimLex, MTurk, MEN, WordSim, Simverb
- 단어 군집(cluster): AP, BLESS
- 평가기준: Spearman's p and purity
- Extrinsic: downstream task에서 input feature로 활용되었을 때 단어 임베딩의 성능 평가
- 단어 분류: SST2, MR
- 개체명 인식: CoNLL-03, BC2GM(domain-specific)
- 평가기준: 정확도, F1
- Robustness: simulated post-OCR typos를 더하면서 모델의 강건성 평가
- downstream tasks: SST2, CoNLL-03
한계
- BERT의 경우 임베딩을 교체할 때 단일 단어가 여러 개의 서브워드로 토크나이즈되면 OOV로 생각해 LOVE가 만든 단일 임베딩으로 교환한다고 하는데, 이러한 전략이 과연 합리적인지? 서브워드 각각의 의미 또한 BERT가 학습했을텐데 단순히 OOV로 여기고 치환해버리는 것은 사전학습 모델을 온전히 사용하지 못하는 게 아닐까?
- Extrinsic Evaluation에서 각 태스크마다 다른 모델 형태를 사용해서 (예: text classification - CNN, NER - BiLSTM) 임베딩 학습, downstream task마다 임베딩 학습이 필요하다면 과연 얼마나 universal하게 사용 가능할지?
의의
- 파라미터 효율성: 기존의 사전학습 모델의 단어 representation을 확장하여 적은 수의 파라미터로 OOV에 대해 강건한 성능을 냄
- 성능 향상: OOV 서브워드의 임베딩을 LOVE의 임베딩으로 교환하는 것은 강건성을 증가시키며, 성능을 향상시킴

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab