논문 소개
Corrective Retrieval Augmented Generation (link)
배경지식
- RAG (Retrieval Augmented Generation)
- 질문과 연관있는 문서의 청크를 검색 (Retrieval)
- 해당 문서를 언어모델의 인풋에 질문과 함께 넣어주면 해당 문서에 근거한 답변을 생성 (Generation)
문제점
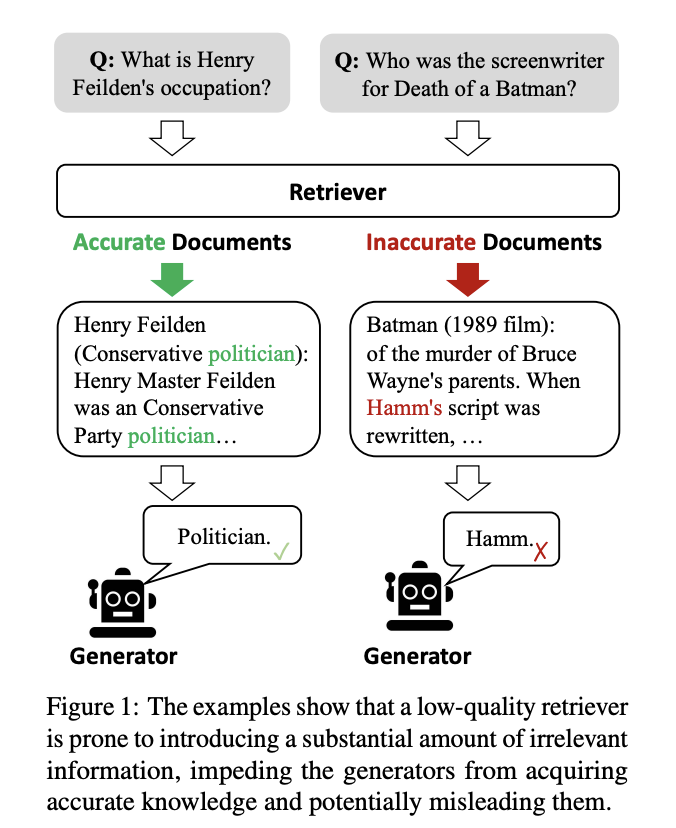
- LLM에 저장된 파라미터 지식에는 한계가 존재하기 때문에 환각 현상 발생
- 환각(hallucination)이란, 언어모델이 그럴듯한 거짓말을 하는 현상
- RAG를 활용해 환각을 완화할 수 있으나, 검색이 제대로 수행되지 않을 경우 성능 저하
해결책
- 검색 결과를 스스로 수정, 문서의 활용을 개선
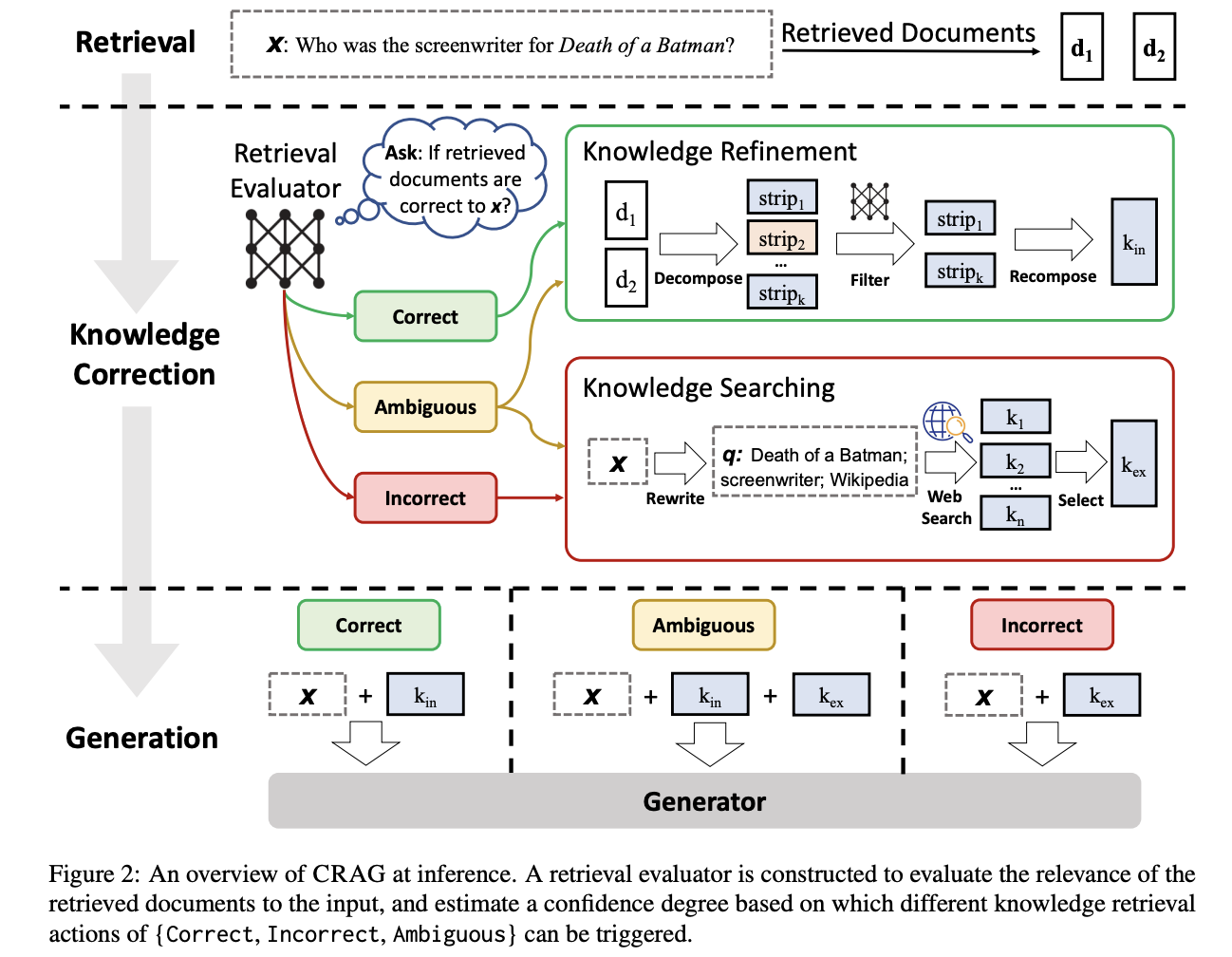
- 가벼운 검색 평가 (lightweight retrieval evaluator)
- 쿼리에 대해 검색된 문서의 품질을 평가
- {정답, 틀림, 애매함} 세 가지 기준으로 분류
- 논문에서는 T5-large 모델을 파인튜닝해 평가자로 활용
- 논문에 따르면, ChatGPT를 평가자로 활용한 경우 성능이 하락했다고 함
- 검색 확장 (웹 검색)
- {틀림, 애매함}으로 평가된 경우 웹서치 진행
- 고정되고 제한적인 문서 내에서는 최적의 문서 검색을 수행할 수 없기 때문
- 분해-결합 (decompose-then-recompose) 알고리즘
- 검색된 문서 중에서 중요한 정보는 선택, 불필요한 정보는 제외
- 지식을 정제함으로써 문서에 기반한 응답 생성 최적화
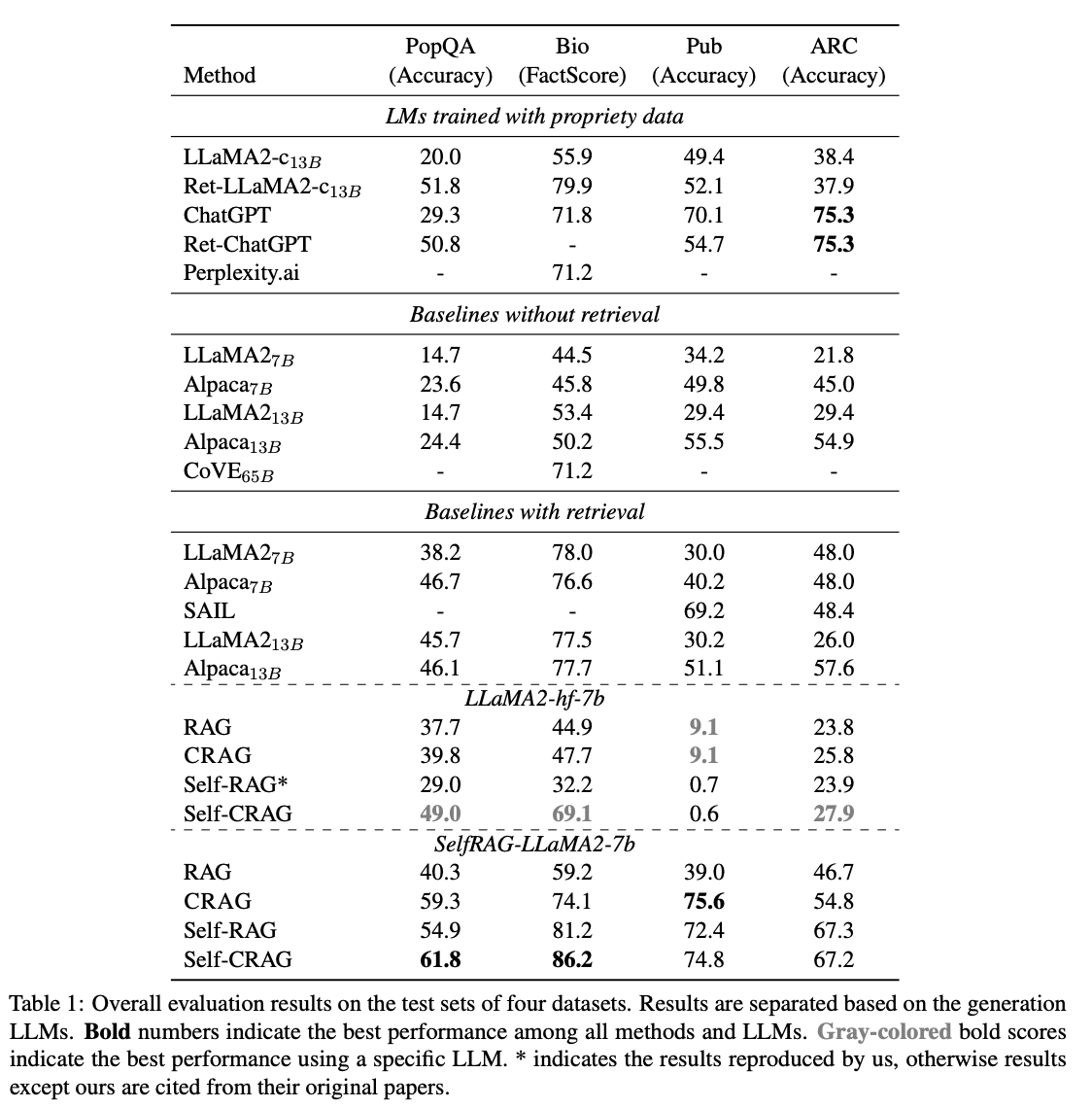
평가
- 데이터셋
- PopQA: 짧은 형태의 생성 태스크
- Biography: 긴 형태의 생성 태스크
- PubHealth: 참-거짓 질의응답 태스크
- Arc-Challenge: 다지선다 태스크
- 평가지표
- 정확도 (PopQA, PubHealth, Arc-Challenge)
- FactScore (Biography)
Langchain 구현 예시코드 (일부)
- langgraph로 CRAG를 구현한 코드 참고
- 참고 링크 (link)
- 참고 링크 코드 설명
- 검색 평가 시 논문과 다르게 파인튜닝된 T5-large가 아닌 LLM을 사용
- 분해-결합 알고리즘 제외
- 문서 관련성 평가 시 {정답, 틀림, 애매함}의 3개 점수가 아닌 {정답, 틀림}의 이진 점수로 구분
- 문서가 관련성이 없다고 판단할 경우 (평가결과=틀림) 재작성한 쿼리를 사용해 LLM 응답 생성
- 논문에서는 기존의 질문을 LLM 응답 생성에 사용
- 웹 검색 시 Tavily API 사용
- 검색된 내용의 길이가 생각보다 짧고, 품질이 평이해보임
- 구현 코드 설명
- langgraph가 아닌 langchain 버전 코드
- 참고 링크 코드와 거의 유사
os.environ['TAVILY_API_KEY'] = 'your-tavily-api-key'
def create_doc_grader(model):
"""retriever가 검색한 문서의 연관성을 채점"""
class GradeDocuments(BaseModel):
"""검색된 문서들이 질문과 얼마나 관련이 있는지를 나타내는 이진 점수"""
binary_score: str = Field(
description="문서들이 질문과 연관성이 있는지 '예' 또는 '아니오'로 판단"
)
structured_llm_grader = model.with_structured_output(GradeDocuments)
system = """당신은 사용자 질문에 대해 검색된 문서의 연관성을 평가하는 채점자입니다. \n
문서가 질문과 관련된 키워드나 유사한 의미를 포함한다면, 해당 문서를 연관성이 있다고 판단하세요. \n
문서와 질문 사이의 연관성을 나타내기 위해 '예' 또는 '아니오'라는 이진 점수를 사용하세요."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "검색된 문서: \n\n {document} \n\n 사용자 질문: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
return retrieval_grader
def create_query_rewriter(model):
"""웹 검색을 위해 사용자 질문을 재작성"""
system = """당신은 입력된 질문을 웹 검색에 최적화된 형태로 바꿔주는 질문 재작성자입니다. \n
입력된 질문을 보고 내재된 의도나 의미를 추론해보세요."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"최초 질문은 다음과 같습니다: \n\n {question} \n 개선된 질문을 작성해주세요.",
),
]
)
question_rewriter = re_write_prompt | model | StrOutputParser()
return question_rewriter
# 언어모델, 임베딩모델, 벡터저장소 정의 부분 생략
# 질문이 담긴 데이터셋 호출 부분 생략
# 질문을 활용해 벡터저장소에서 관련된 문서 청크 (docs) 검색하는 부분 생략
##### Corrective RAG #####
retrieval_grader = create_doc_grader(model)
docs = retriever.invoke(question)
# Grade document relevancy
filtered_docs = []
need_web_search = 'No'
for d in docs:
score = retrieval_grader.invoke({'question': question, 'document': d.page_content})
grade = score.binary_score
if grade == '예':
filtered_docs.append(d)
elif grade == '아니오':
need_web_search = 'Yes'
continue
# Decide to generate
if need_web_search == 'Yes':
web_search_num = 검색문서수 - len(filtered_docs)
question_rewriter = create_query_rewriter(model)
better_question = question_rewriter.invoke({"question": question})
# Web search
web_search_tool = TavilySearchResults(max_results=web_search_num)
web_docs = web_search_tool.invoke({"query": better_question})
web_results = [Document(page_content=d["content"] for d in web_docs]
filtered_docs.extend(web_results)
... (중략) ...

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab