논문 소개
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection (link)
문제점
- RAG (Retrieval Augmented Generation)는 관련된 지식을 검색해 언어모델에 제공함으로써 파라미터 지식의 한계를 보완
- 하지만 관련이 없는 문서가 LLM의 인풋에 포함될 경우 생성된 응답의 품질이 떨어짐
해결책
(SELF-RAG) Self-Reflective Retrieval-Augmented Generation
- 검색(retrieval)과 자기반성(self-reflection)을 통해 언어모델 응답의 품질과 사실성을 개선하고자 하는 프레임워크
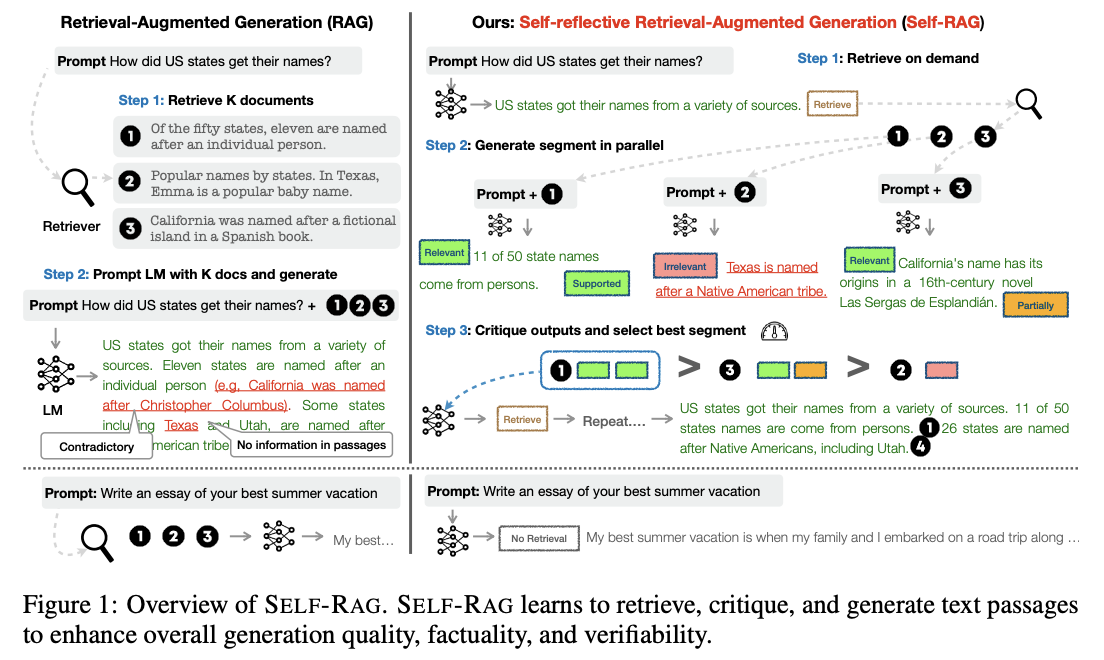
- 언어모델이 태스크에 관련한 응답과 더불어 간헐적으로 특별한 토큰(=reflection token)을 생성하도록 학습
- reflection token은 retrieval(검색)과 critique(비판) 토큰으로 분류
SELF-RAG 추론 순서
- 1단계: 언제든지(on-demand) 검색
- 인풋과 이전의 생성(=모델 응답)이 주어지면, 검색이 필요할지 여부를 결정
- retrieval 토큰이 생성된다면 검색 모델을 호출
- 2단계: 병렬 평가 및 생성
- 검색된 여러 개의 문단들에 대해 동시에 처리 진행
- 여기서의 처리란, 문단의 연관성을 평가하고 태스크 아웃풋(=응답)을 생성함을 의미
- 3단계: 아웃풋 평가 및 선택
- critique 토큰을 사용해 아웃풋을 평가하고 가장 좋은 응답을 선택


Critique 모델 및 Generator 모델 학습
- Critique 모델
- GPT-4를 활용해 reflection 토큰을 생성하게 하고, 해당 데이터셋을 학습에 활용
- Llama 2-7B 모델을 기반으로 추가 학습 진행
- maximizing likelihood (conditional language modeling objective) 활용
- Critique 모델을 활용해 위의 Retrieve, IsRel, IsSup, IsUse reflection 토큰을 생성
- Generator 모델
- reflection 토큰을 추가한 코퍼스를 활용해 학습
- 태스크 아웃풋과 동시에 reflection 토큰을 예측하도록 학습
- next token prediction objective 활용
평가
- 태스크 및 데이터셋
- PubHealth: 사실 검증
- ARC-Challenge: 다지선다 추론
- Pop-QA: 짧은 문장 생성
- TriviaQA-unfiltered: 짧은 문장 생성
- ALCE-ASQA: 긴 문장 생성
- 평가지표
- 정확성 (PubHealth, ARC-Challenge)
- 정답이 문장에 포함되어 있는지 여부 (Pop-QA, TriviaQA-unfiltered)
- FactScore, MAUVE에 기반한 correctness (str-em) / fluency, citation precision and recall (ALCE-ASQA)
Langchain 구현 코드 (일부)
- 참고 링크
논문과 구현 코드 차이점 정리
- 기존 논문에는 다시 문서 검색을 수행할 때 "기존 쿼리 + 가장 순위가 높은 이전 응답"을 활용해 검색 진행
- Langchain 예시 코드에서는 "쿼리 재작성"을 통한 새로운 쿼리를 검색에 사용
- 기존 논문에서는 각각의 문서(d)에 대해 질문-문서 관련성, 질문-답변 관련성, 질문-문서-응답 환각여부를 판단하고 가장 좋은 응답을 선택
- Langchain 예시 코드에서는 관련된 문서가 하나라도 있다면 전체 문서들에 대해 응답 생성
- 기존 논문과는 다르게 구현 코드에서는 초반에 검색 여부를 결정하는 부분이 없음
- 기존 논문은 Llama-2-7B 모델을 활용해 특정 토큰을 생성할 수 있도록 학습을 진행, 토큰에 기반한 Ranking 등의 방법을 사용
- 예시 코드는 API로 호출하는 Blackbox LLM 사용 (Structured Output)
구현 코드 설명
- 이전 응답(y<t)을 평가 혹은 생성에 포함하지 않음
- 점수 산정에 지속적으로 이전의 모델 응답을 포함할 경우, error propagation의 위험성
- 문서가 관련이 없거나 응답과 질문의 연관성이 없더라도, Top-1 응답을 선택해야 함
- 또한 context length의 한계가 존재하기 때문에 오류 발생 가능
- 점수 산정에 지속적으로 이전의 모델 응답을 포함할 경우, error propagation의 위험성
- Langgraph 미사용, Langchain 기반
- 무한루프에 빠지는 상황을 막기 위해, 특정 횟수가 지나면 Simple RAG 진행
... (import 생략) ...
... (format_docs 함수 생략) ...
def create_retrieval_grader(model):
"""retriever가 검색한 문서의 연관성을 채점"""
class GradeDocuments(BaseModel):
"""검색된 문서들이 질문과 얼마나 관련이 있는지를 나타내는 이진 점수"""
binary_score: str = Field(
description="문서들이 질문과 연관성이 있는지 '예' 또는 '아니오'로 판단"
)
structured_llm_grader = model.with_structured_output(GradeDocuments)
system = """당신은 사용자 질문에 대해 검색된 문서의 연관성을 평가하는 채점자입니다. \n
엄격하게 채점할 필요는 없습니다. 목적은 잘못된 검색 결과를 걸러내는 것입니다. \n
문서가 질문과 관련된 키워드나 유사한 의미를 포함한다면, 해당 문서를 연관성이 있다고 판단하세요. \n
문서와 질문 사이의 연관성을 나타내기 위해 '예' 또는 '아니오'라는 이진 점수를 사용하세요."""
grade_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "검색된 문서: \n\n {document} \n\n 사용자 질문: {question}"),
]
)
retrieval_grader = grade_prompt | structured_llm_grader
return retrieval_grader
def create_hallu_grader(model):
"""생성된 응답이 환각인지 여부를 측정"""
class GradeHallucinations(BaseModel):
"""생성된 응답에 환각(hallucination)이 있는지를 나타내는 이진 점수"""
binary_score: str = Field(
description="응답이 사실에 근거하는지 '예' 또는 '아니오'로 판단"
)
# LLM with function call
structured_llm_grader = model.with_structured_output(GradeHallucinations)
# Prompt
system = """당신은 언어모델이 생성한 응답이 검색된 사실들에 기반하고 있는지 여부를 평가하는 채점자입니다. \n
'예' 혹은 '아니오' 둘 중 하나로 대답하세요. '예'는 응답이 사실들에 기반하고 있지 않음을 의미합니다."""
hallucination_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "사실들: \n\n {documents} \n\n 언어모델 응답: {generation}"),
]
)
hallucination_grader = hallucination_prompt | structured_llm_grader
return hallucination_grader
def create_answer_grader(model):
class GradeAnswer(BaseModel):
"""질문에 적절한 대답인지를 평가하는 이진 점수"""
binary_score: str = Field(
description="질문에 적절한 대답인지 '예' 혹은 '아니오'로 판단"
)
# LLM with function call
structured_llm_grader = model.with_structured_output(GradeAnswer)
# Prompt
system = """당신은 응답이 질문에 적절한지 혹은 응답이 질문을 해결할 수 있는지 여부를 평가하는 채점자입니다. \n
'예' 혹은 '아니오' 둘 중 하나로 대답하세요. '예'는 응답이 질문을 해결할 수 있음을 의미합니다."""
answer_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "사용자 질문: \n\n {question} \n\n 언어모델 응답: {generation}"),
]
)
answer_grader = answer_prompt | structured_llm_grader
return answer_grader
def create_query_rewriter(model):
"""재검색을 위해 사용자 질문을 재작성"""
system = """당신은 입력된 질문을 문서 검색에 최적화된 바꿔주는 질문 재작성자입니다. \n
입력된 질문을 보고 내재된 의도나 의미를 추론해보세요."""
re_write_prompt = ChatPromptTemplate.from_messages(
[
("system", system),
(
"human",
"최초 질문은 다음과 같습니다: \n\n {question} \n 개선된 질문을 작성해주세요.",
),
]
)
question_rewriter = re_write_prompt | model | StrOutputParser()
return question_rewriter
class SelfRAG:
def __init__(self, initial_question, prompt, retriever, model):
self.initial_question = initial_question # for backup
self.question = initial_question
self.prompt = prompt
self.retriever = retriever
self.model = model
self.retrieval_grader = create_retrieval_grader(model)
self.hallucination_grader = create_hallu_grader(model)
self.answer_grader = create_answer_grader(model)
self.query_rewriter = create_query_rewriter(model)
self.state = "retrieve_documents"
self.documents = None
self.answer = None
self.rate_limit_break_sec = 15
self.patience = 10
def _countdown(self):
self.patience -= 1
def retrieve_documents(self):
logging.info('--- retrieve documents ---')
documents = self.retriever.invoke(self.question)
self.documents = documents
self.state = "grade_documents"
self._countdown()
def grade_documents(self):
logging.info('--- grade documents ---')
filtered_docs = []
for d in self.documents:
while True:
try:
score = self.retrieval_grader.invoke({'question': self.question,
'document': d.page_content})
break
except RateLimitError as e:
logging.warning(f'RateLimitReached가 발생하여 {self.rate_limit_break_sec}초간 쉽니다.')
time.sleep(self.rate_limit_break_sec)
grade = score.binary_score
if grade == '예':
filtered_docs.append(d)
elif grade == '아니오':
continue
if filtered_docs:
self.state = "generate_llm_answer"
self.documents = filtered_docs
else:
self.state = "rewrite_question"
def generate_llm_answer(self):
logging.info('--- generate llm answer ---')
rag_chain = self.prompt | self.model | StrOutputParser()
while True:
try:
answer = rag_chain.invoke({"retrieved": format_docs(self.documents),
"question": self.question})
break
except RateLimitError as e:
logging.warning(f'RateLimitReached가 발생하여 {self.rate_limit_break_sec}초간 쉽니다.')
time.sleep(self.rate_limit_break_sec)
self.answer = answer
self.state = "check_hallucination"
self._countdown()
def rewrite_question(self):
logging.info('--- rewrite question ---')
while True:
try:
new_question = self.query_rewriter.invoke({"question": self.question})
break
except RateLimitError as e:
logging.warning(f'RateLimitReached가 발생하여 {self.rate_limit_break_sec}초간 쉽니다.')
time.sleep(self.rate_limit_break_sec)
self.question = new_question
self.state = "retrieve_documents"
def check_hallucination(self):
logging.info('--- check hallucination ---')
while True:
try:
hallucination_score = self.hallucination_grader.invoke({"documents": self.documents,
"generation": self.answer})
break
except RateLimitError as e:
logging.warning(f'RateLimitReached가 발생하여 {self.rate_limit_break_sec}초간 쉽니다.')
time.sleep(self.rate_limit_break_sec)
hallucination_grade = hallucination_score.binary_score
if hallucination_grade == '예':
self.state = "generate_llm_answer"
else:
self.state = "check_answer_relevance"
def check_answer_relevance(self):
logging.info('--- check answer relevance ---')
while True:
try:
relevancy_score = self.answer_grader.invoke({"question": self.question,
"generation": self.answer})
break
except RateLimitError as e:
logging.warning(f'RateLimitReached가 발생하여 {self.rate_limit_break_sec}초간 쉽니다.')
time.sleep(self.rate_limit_break_sec)
relevancy_grade = relevancy_score.binary_score
if relevancy_grade == '예':
self.state = "finished"
else:
self.state = "rewrite_question"
def run(self):
state_methods = {
"retrieve_documents": self.retrieve_documents,
"grade_documents": self.grade_documents,
"generate_llm_answer": self.generate_llm_answer,
"rewrite_question": self.rewrite_question,
"check_hallucination": self.check_hallucination,
"check_answer_relevance": self.check_answer_relevance,
"finished": lambda: print("Process finished successfully with answer:", self.answer)
}
while self.state != "finished" and self.patience > 0:
state_methods[self.state]()
if self.state == "finished":
logging.info('=== Self RAG is properly finished ===')
return self.answer
else:
logging.info('=== Self RAG cannot generate a proper answer. Use simple RAG ===')
self.question = self.initial_question
self.retrieve_documents()
self.generate_llm_answer()
return self.answer
# Self RAG
# question, prompt, retriever, model (언어모델) 정의 부분 생략
self_rag = SelfRAG(question, prompt, retriever, model)
response = self_rag.run()

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab