경량화의 필요성
- 거대한 모델의 학습에는 엄청난 시간과 경제적, 환경적 비용이 발생하며 추론 비용도 만만치 않음
- 거대한 모델은 모바일폰이나 임베디드 기기에서 활용될 수 없음
- 이와 같은 이유로 모델을 경량화하는데, 경량화에는 weight pruning, quantization, knowledge distillation 방식이 사용됨
Weight Pruning
- 뉴런들 사이의 특정한 연결(=weight, 가중치)을 제거하는 방법
- 제거란, 해당 weight(비중, 가중치)를 0으로 치환하는 것을 의미
- Optimal Brain Damage
- 특정 weight을 제거했을 때 loss 파악, loss가 크게 변하지 않는 weight 제거
- 하지만 pruning 이후 retraining이 필요하기 때문에 여전히 학습 시에 큰 비용 발생
- 어떤 weight을 prune할지 선택하기 위해 perturbation-based quantity 사용
- Lottery Ticket Hypothesis
- 랜덤하게 초기화된 NN(neural network)에는 원래의 네트워크만큼의 성능을 낼 수 있는 subnetwork가 존재할 것이라 가정
- 단순한 모델 아키텍처에서는 뛰어난 성능을 보였으나 복잡한 아키텍처에선 어려움
- 어떤 weight을 prune할지 선택하기 위해 magnitude 사용
- SynFlow
- 전체 레이어의 premature pruning은 네트워크를 학습불가능하도록 만든다는 Layer collpase 개념 제안
- 학습 없이 pruning 가능
- 어떤 weight을 prune할지 선택하기 위해 synaptic saliency score 사용
- synaptic saliency score가 레이어들 사이에서 유지되는데, 반복적인 pruning 알고리즘이 이러한 레이어별 점수 유지를 가능케 한다면 layer collapse 방지 가능
- weight pruning의 경우 보편적인 SOTA 해결책이 없으며, pre-training pruning이 post-training 알고리즘만큼의 성능을 낼 수 없다는 단점 존재
Quantization
- 주로 사용되는 float32 타입이 아닌 int8을 사용하면 연산이 더욱 빨라지고 메모리를 덜 사용하게 됨
- weight의 타입을 변경하여 경량화하는 방법
- 단 int16으로 overflow되는 등 오류가 발생할 수 있기 때문에 신중해야 함
- Post-training quantization, quantization-aware training 등의 종류가 있으며, 정확도가 떨어지거나 최적이 아닌 결과를 야기하는 등의 문제 발생 가능
Knowledge Distillation
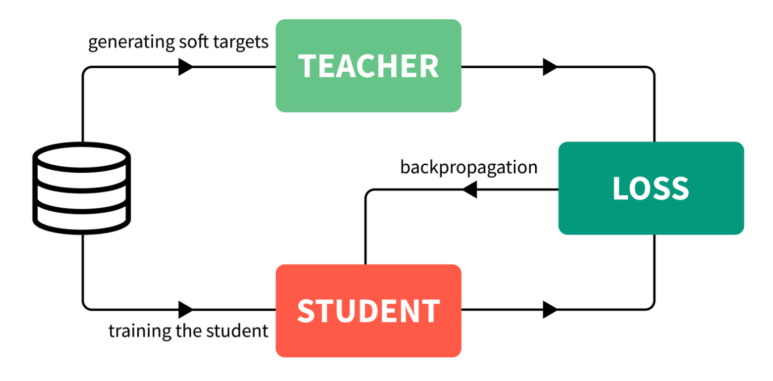
- 큰 모델(선생님; teacher)을 학습하여 최고의 성능을 달성할 수 있도록 하고 이 예측값으로 작은 모델(학생; student)을 학습해 일반화 성능 향상을 꾀하는 방법
- 거대한 앙상블 모델이 단순한 아키텍처로 경량화될 수 있음을 보이며 운영에 더욱 적합한 형태를 띔
- 경량화된 모델의 추론 시간을 개선시켜주나, 학습 시간을 개선하는 방법은 아님
- BERT에서도 knowledge distillation을 활용한 방법들이 많이 등장
- Soft label(=soft target)은 큰 네트워크의 각 레이어의 결과값을 의미하며, 작은 네트워크는 모든 단계의 결과값을 이용해 큰 네트워크의 행동을 모방하는 방식으로 큰 네트워크와 유사하게 학습
- 이는 더욱 큰 solution space에서 convergence를 진행한 큰 네트워크의 행동을 모방함으로써 본래의 teacher network의 convergence space와 겹치는 방향으로 student network가 convergence space를 가지게 되기 때문임
Knowledge Distillation 구현순서
- teacher network 학습 (높은 연산성능 필요)
- establish correspondence
- teacher network와 studnet network 사이에 intermediate output(중간 결과값)이 대응되어야 함
- teacher network의 결과값을 바로 student에 넘겨주거나 혹은 data augmentation 수행 후 결과값을 student에 넘겨줌
- forward pass through teacher network
- teacher network에 데이터를 넣어 intermediate output(중간 결과값)을 확보
- backpropagation through student network
- teacher network의 행동을 모방하는 방식으로 학습
관련 링크 (link)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab