RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval (ICLR 2024, link)
배경지식
- Large Language Model (거대언어모델)
- 거대한 수의 파라미터를 가지며, 파라미터에 지식을 저장하고 있는 언어 모델
- 일반적인 많은 질문들에 답변할 수 있으나, 도메인 특화 지식 혹은 시간이 지남에 따라 변화하는 지식(i.e. 모델의 학습 시점과는 달라진 지식)에 대해서는 한계를 가짐
- RAG (Retrieval Augmented Generation)
- 앞서 언급한 LLM의 한계를 극복하고자 언어모델 응답 생성 이전에 문맥(context)의 형태로 검색된 문서를 제공하는 방식
- 기본적인 RAG는 검색 문서 벡터 스토어에 저장 (Indexing) > 사용자 질문에 대한 벡터 저장소 검색 (Retrieval) > 질문과 문맥을 활용해 언어모델 응답 생성(Generation)과 같은 형태를 취함
- 하지만 언어모델의 context length 제한, 검색 성능의 한계 등 존재
문제점
- 기존의 RAG는 검색문서를 연속적으로 분할한 청크(chunk)를 기본 검색단위로 사용함으로써, 문서 전체의 이해를 요하는 질문에 제대로 답변할 수 없었음
해결책
RAPTOR RAG
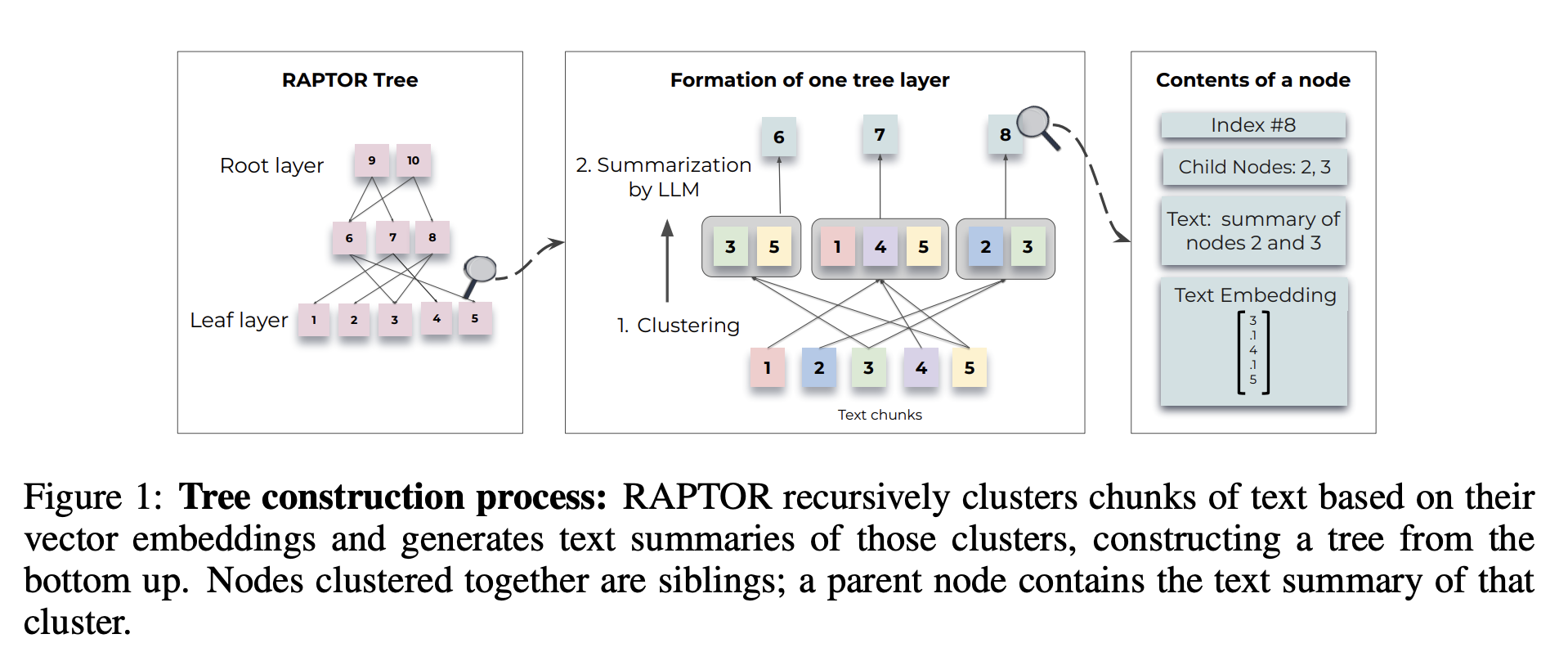
- 글의 고차원, 저차원 세부사항을 모두 담을 수 있도록 트리 구조로 인덱싱 및 검색(Retrieval) 시스템 설계
- 다양한 길이의 글을 재귀적으로(recursively) 요약함으로써 트리 구조를 생성
1. 코퍼스 분할 및 임베딩 변환
- 긴 문서를 100토큰 기준으로 쪼갬
- 이렇게 쪼개진 작은 문서를 청크(chunk)라고 칭함
- SBERT를 활용하여 텍스트를 임베딩으로 변환 (벡터화)
2. 청크 클러스터링 (군집화)
- Soft Clustering
- 청크 각각을 노드라고 했을 때, 하나의 노드가 여러 클러스터(군집)에 속할 수 있도록 함
- GMM (Gaussian Mixture Model)
- 군집화를 위해 사용한 알고리즘
- 데이터가 여러 개의 가우시안 분포(정규 분포)의 혼합으로 이루어져 있다고 가정하며, 각각의 가우시안 분포가 하나의 군집이 되고 데이터 포인트가 분포들에 속하게 됨
- Expectation-Maximization 알고리즘을 활용해 GMM 파라미터 측정 (i.e. means, covariances, mixture weights)
- UMAP (Uniform Manifold Approximation and Projection)
- 군집화의 대상인 텍스트는 고차원의 벡터 임베딩으로 구성됨
- GMM으로 임베딩의 거리를 측정해 군집화를 수행할 때, 유사성을 계산함에 있어 한계가 존재할 수 있음
- 이를 해결하기 위해 UMAP을 활용해 차원 축소를 수행
- BIC (Bayesian Information Criterion)
- 군집의 최적 개수를 결정하기 위해 활용
- 재귀적으로 군집 내 군집화를 진행하여, 트리 구조 생성
3. 군집 내 노드 요약
- gpt-3.5-turbo를 활용하여 각 군집의 노드들을 요약
- 언어모델을 활용한 요약 과정에서 약 4%의 환각 현상이 발생
- 부모 노드에 해당 오류가 전파되지 않을 뿐더러
- QA 태스크의 성능에 확연한 영향을 미치지 않았음
4. 질문(Querying) 시 검색 방식
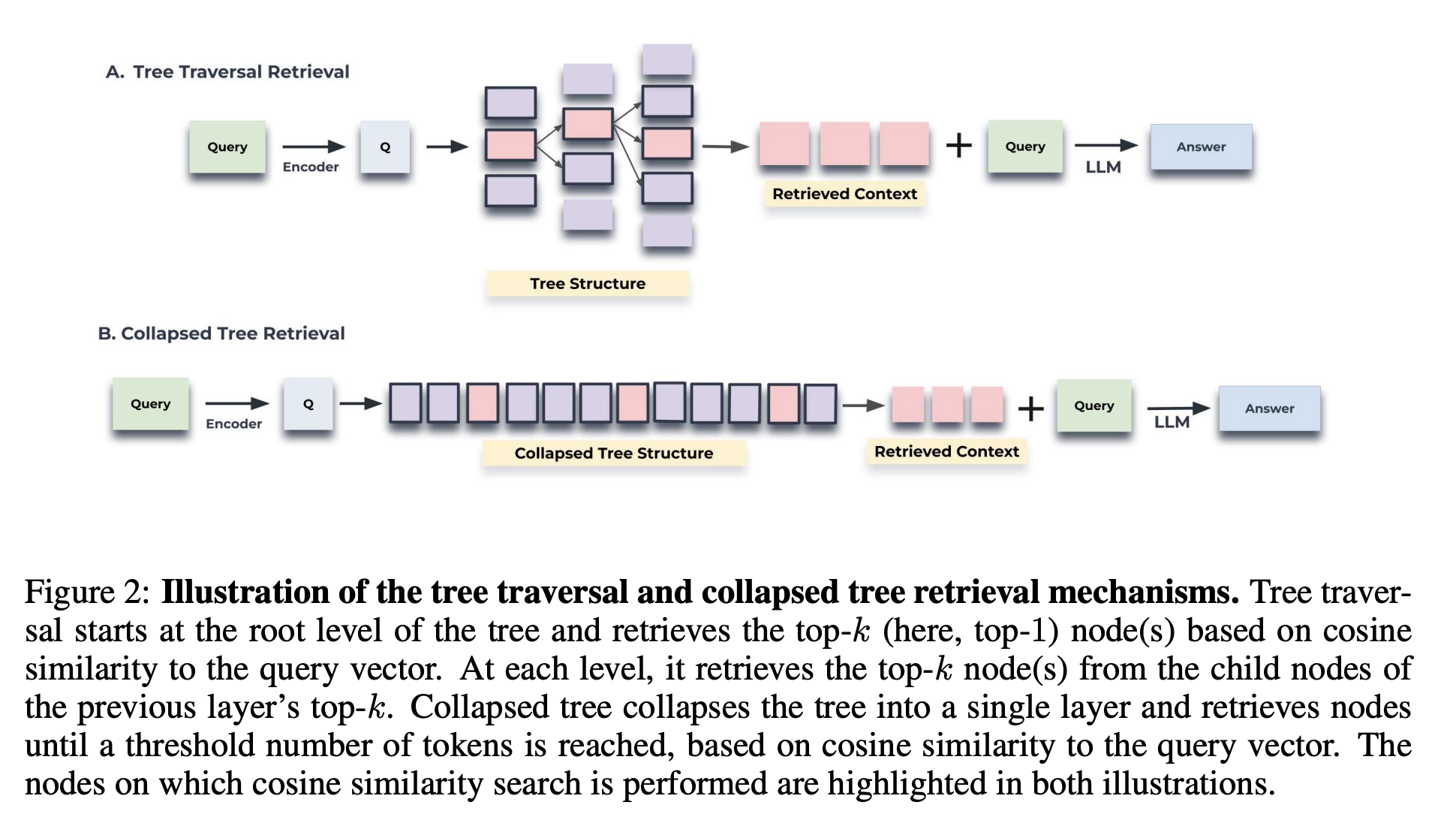
- tree traversal
- 쿼리 임베딩과의 코사인 유사도 기반으로 top-k 노드 선정
- 해당 노드 하위의 자식 노드에 대해 코사인 유사도 측정 후 top-k 선정
- collapsed tree
- 트리 구조의 모든 노드를 동시에 고려
- 전체 중 쿼리 임베딩과 코사인 유사도가 높은 노드를 선정
- 트리의 정보를 반영할 수 있도록 각 층에서 선택할 수 있는 top-k 제한
- QASPER 데이터셋 대상으로 실험 결과, 해당 방식이 더 좋은 검색 성능을 보임
평가
- 데이터셋
- NarrativeQA, QASPER, QuALITY
- 평가지표
- BLEU, ROUGE, METEOR (NarrativeQA)
- F1 (QASPER)
- Accuracy (QuALITY)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab