T-RAG: Lessons from the LLM Trenches (link)
배경지식
- LLM (Large Language Model)
- OpenAI의 GPT처럼 거대한 크기를 가진 언어모델
- 하나의 모델로 여러 개의 태스크를 동시에 수행할 수 있음
- 학습 코퍼스에 포함되지 않은 도메인 특화 질문에 취약
- Finetuning
- 레이블된 데이터셋을 학습함으로써 언어모델의 파라미터를 업데이트하는 방법
- 이를 통해 도메인 특화 지식 등 새로운 지식을 학습할 수 있음
- RAG (Retrieval-Augmented Generation)
- 언어모델을 파인튜닝하는 등 학습하지 않고도 언어모델의 응답에 새로운 지식을 포함하는 방법
- 외부의 데이터를 검색해 언어모델에게 문맥 정보로 제공
- 3장 연관 용어에서 프롬프트, 시스템 프롬프트, 문맥, 인컨텍스트 학습 등 기본 개념들이 잘 정리되어 있음 (기본 개념을 모른다면 참고할만 함)
문제점
- 기업 특화된 RAG를 구현할 때, 일반적인 RAG는 기업 내 조직에 대한 정보를 포함할 수 없어 응답이 제한적
해결책
Tree-RAG (T-RAG)
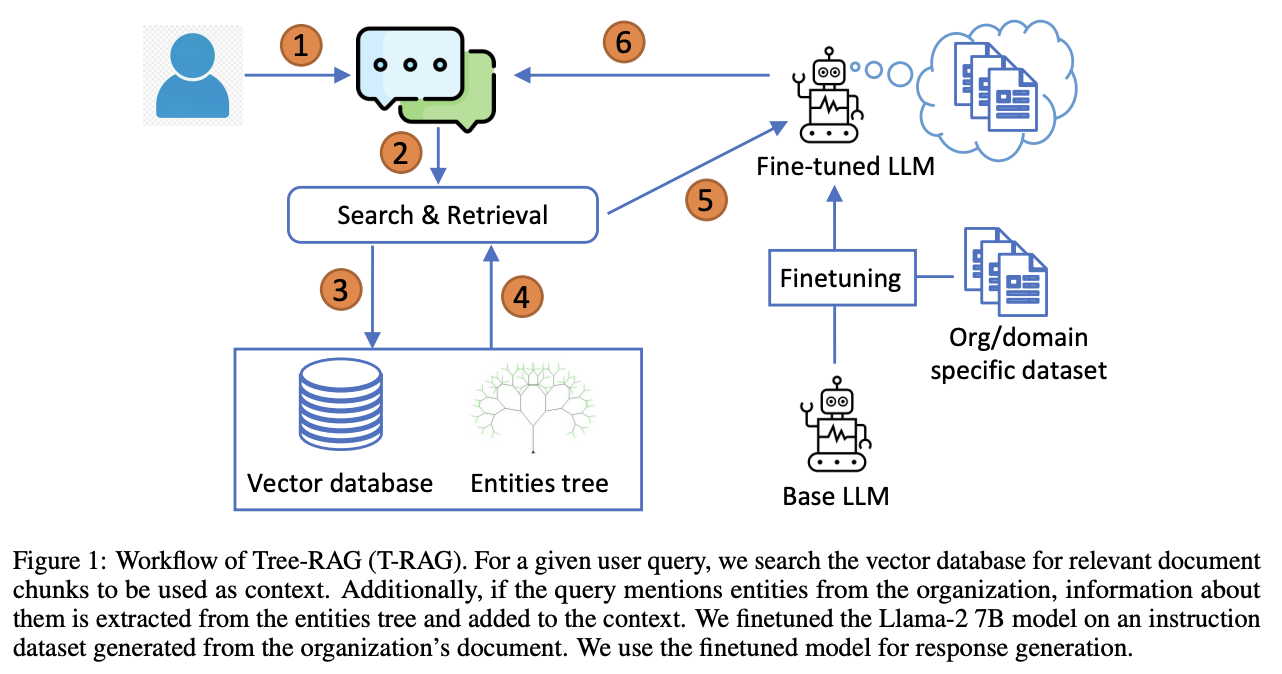
일반적인 RAG와 T-RAG는 아래와 같은 점들이 다름
- 파인튜닝된 언어모델을 활용 (Llama-2 7B chat 모델)
- 기업의 문서들을 바탕으로 도메인 특화 데이터셋을 생성
- 구체적으로는, 문서의 청크들을 바탕으로 다양한 프롬프팅을 통해 질문, 답변 쌍을 생성
- 파라미터 효율적 파인튜닝 방법 중 하나인 QLoRA를 활용해 학습
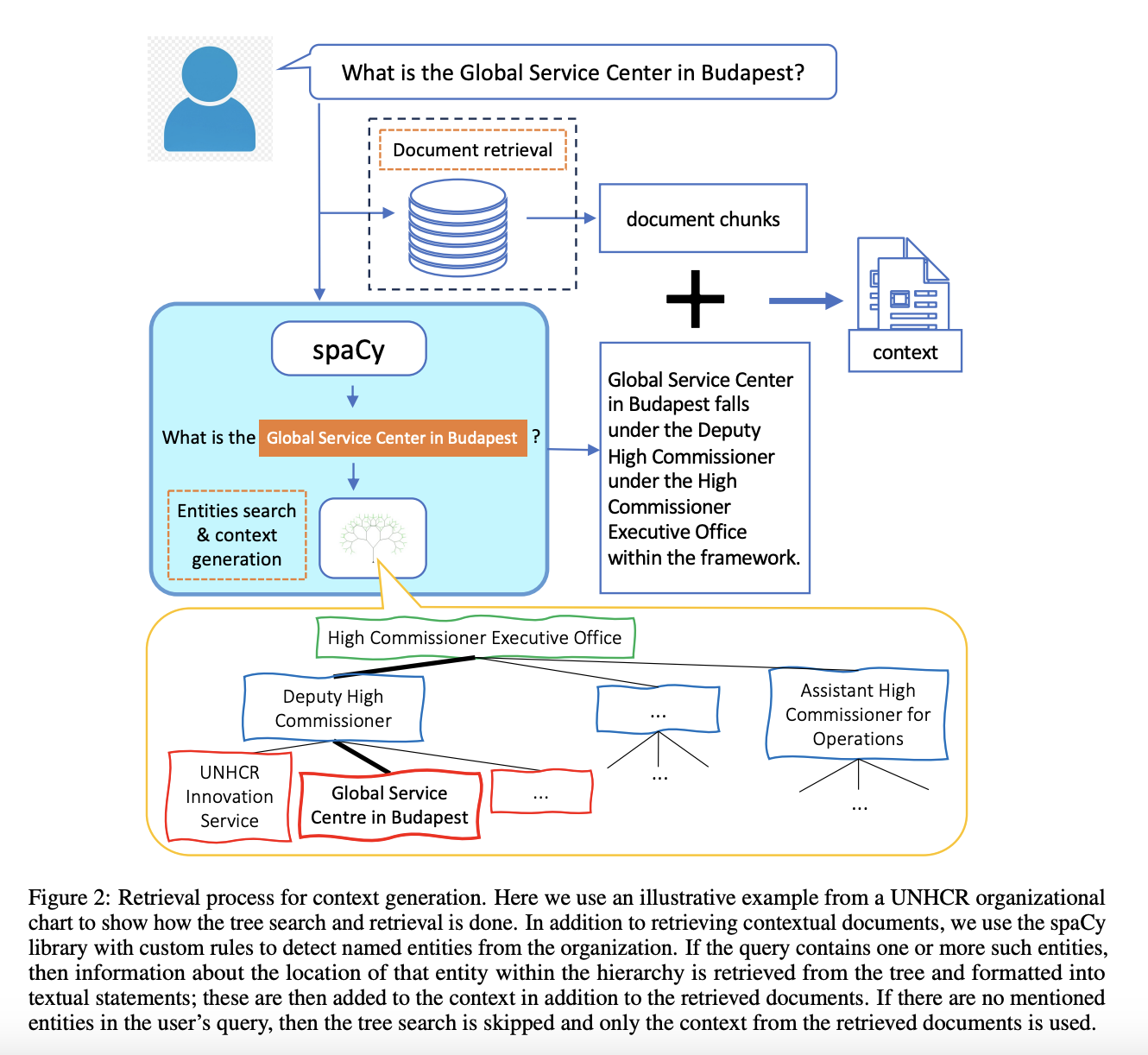
- 엔티티(개체) 나무를 포함해 문맥 정보를 풍부하게 함
- spaCy를 활용해 사용자 질문에서 개체를 파악
- 개체가 있다면, 검색한 문서에 추가적으로 조직의 개체 정보를 포함하여 언어모델에게 문맥으로 제공
평가
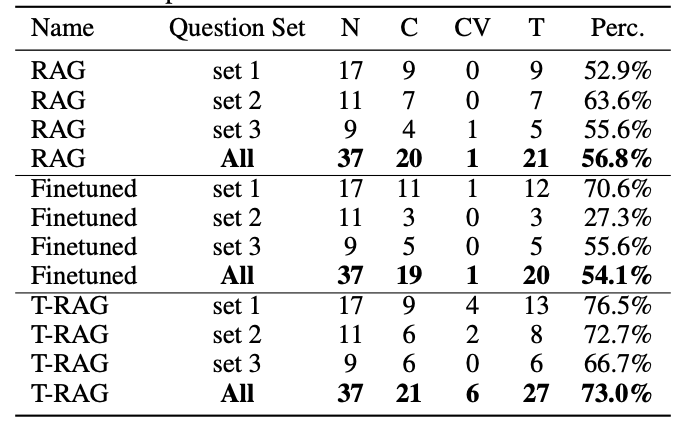
사람이 직접 평가
- 평가지표
- Correct
- 질문에 대한 응답이 사실인지 여부
- Correct-Verbose
- 질문에 대한 응답이 사실일 뿐만 아니라 질문에 연관된 정보만을 포함했는지 여부
- Correct
한계
- 일반적으로 RAG의 장점은 모델의 추가적인 학습 없이 빠르게 적용할 수 있다는 점인데, 파인튜닝과 RAG를 동시에 사용함으로써 그 장점이 상쇄됨
- 성능 측면에서는 더 좋을 수 있으나, 엔티티 트리만을 적용했을 때 성능이 나오지 않아 파인튜닝된 언어모델을 사용했을 가능성이 존재
- 파인튜닝 모델의 오버피팅 가능성
- 논문에서는 MMLU 벤치마크에서 기본 45.3% 성능이 파인튜닝한 이후 43%로 떨어졌고, 차이가 근소하기 때문에 오버피팅이 일어나지 않았다고 언급
- 성능이 어찌됐든 떨어졌다는 점에서 catastrophic forgetting이 일어났을 수 있기 때문에 정성적 평가 필요하며 중요한 부분이나, 논문에서 너무 짧게 다뤄진 느낌

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab