언어모델이란
- 언어모델이란 단어와 문장들에 확률을 할당하는 통계모델
- 예를 들어 이전까지의 단어들을 바탕으로 다음 단어를 예측하는 경우가 있음 (예: 저녁으로 나는 피자를 ____ )
- Unigram model은 개별 단어 수준으로 작동
- N-gram model은 이전의 n-1개의 단어를 바탕으로 다음 단어를 예측

언어모델의 평가
- 언어모델을 비교하고 평가하는 데에는 두 가지 방법이 존재
- Extrinsic evaluation (외적 평가)
- 모델을 실제 태스크(예: 번역)에 사용하고 loss/accuarcy(손실, 정확도)를 측정함으로써 모델을 평가
- 명확하게 얼마나 모델이 다른지를 비교할 수 있으나 연산에 있어 비용이 발생하며 전체 시스템을 학습해야 하므로 시간이 소요
- Intrinsic evaluation (내적 평가)
- 특정 태스크와 무관하게 언어모델 자체를 평가할 수 있는 방식
- 외적 평가보다 뛰어나진 않지만 모델을 빠르게 비교할 수 있음
- Perplexity가 내적평가 방법
Perplexity: normalized inverse probability of test set
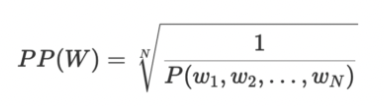
- 좋은 언어모델이란, 실제 혹은 의미적으로 옳은 문장에 더 높은 확률을 부여하고, 거짓 혹은 부정확한 문장에 낮은 확률을 부여하는 모델
- 즉, 가장 좋은 모델은 테스트 셋에 가장 높은 확률을 부여하는 모델
- Intuitively, if a model assigns a high probability to the test set, it means that it is not surprised to see it (it’s not perplexed by it), which means that it has a good understanding of how the language works.
- 문장들의 숫자와 무관하게 성능을 측정하기 위해 테스트셋의 확률을 전체 단어의 개수로 정규화(normalizing)
- 즉 단어별 측정을 가능하도록 함
- inverse probability를 취하기 때문에, 더 낮은 perplexity를 가질수록 더욱 좋은 모델
Perplexity: exponential of cross-entropy
- entropy란 변수에 정보를 저장하기 위해 필요한 bits의 평균 숫자로 해석할 수 있음
- 이를 계산할 때 실제 확률이 아니라 학습 데이터셋에 대한 추정 분포(estimated distribution)를 활용할 수 있음
- cross entropy(H(W))는 각 단어를 인코딩(즉, 벡터와 같은 수치데이터로 변경)하기 위해 필요한 bits의 평균 숫자로 이해할 수 있음
- 2^(H(W))로 표현 가능한 perplexity는 따라서 H(W) bits를 이용해 인코딩될 수 있는 단어들의 평균 숫자로 파악 가능
- perplexity as weighted branching factor
- branching factor는 다음 단어를 예측하는 언어모델의 각 지점에서 가능한 단어의 수(=단어사전의 크기)
- 예를 들어, cross-entropy 값이 2일 때 perplexity는 4인데, 이는 모델이 다음 단어를 예측할 때 4개의 다른 단어들 사이에 무엇을 고를지 고민(confused, perplexed)한다는 것을 의미
관련 링크 (link)

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab