ORPO: Monolithic Preference Optimization without Reference Model (arXiv, 2024.03)
배경지식
- Instruction-tuning
- 모델이 자연어로 주어진 태스크 설명을 잘 따르도록 학습
- 이전에 학습하지 않은(unseen) 태스크에 대해서도 잘 일반화할 수 있음
- 하지만 모델이 해롭거나 도덕적이지 않은 응답을 생성할 가능성 존재
- 모델이 자연어로 주어진 태스크 설명을 잘 따르도록 학습
- Preference alignment
- 모델이 사람이 가치있게 여기는 부분들을 잘 따르도록 만들기 위해 선호 데이터를 활용해 추가 학습
- e.g. RLHF(Reinforcement Learning with Human Feedback)
- e.g. DPO(Direct Preference Optimization)
- 블로그의 설명 링크
문제
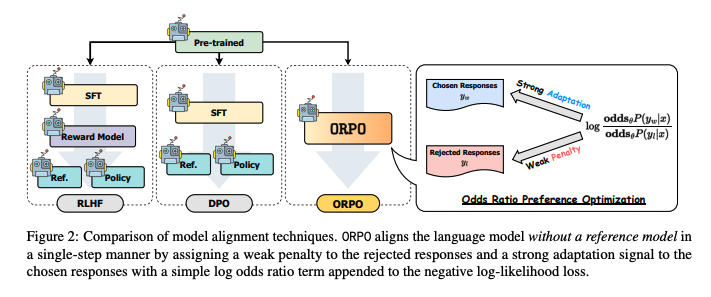
- 기존 Preference alignment 방법들의 한계
- 여러 단계의 절차를 필요로 함
- 일반적으로 별도의 참조 모델(reference model)과 SFT(Supervised fine-tuning)로 웜업하는 단계가 필요
- Supervised fine-tuning (SFT)의 한계
- preference alignment의 초기 단계로 자주 활용됨
- 사전학습 모델을 원하는 도메인에 맞추는 역할을 수행 (=domain adaptation)
- 하지만 그 과정에서 원치 않는 토큰이 생성될 가능성을 높임
- 이는 SFT에 사용되는 Cross Entropy Loss가 원치 않는 생성에 페널티를 주지 못하기 때문
해결책
ORPO (Odds Ratio Preference Optimization)
- 전통적인 NLL(negative log-likelihood)와 오즈비(odds ratio) 기반의 페널티를 통합한 새로운 loss
- 선호되는 생성 방식과 비선호되는 응답을 구별하는 역할을 수행
오즈비
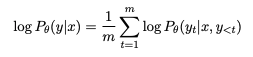
- 인풋 x가 주어질 때, 아웃풋 y를 생성하는 평균 log likelihood
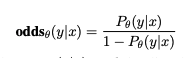
- 인풋 x가 주어질 때 아웃풋 y를 생성할 odds
- odds = k라고 한다면, 이는 모델이 y를 생성할 가능성이 y를 생성하지 않을 가능성보다 k배 높다는 뜻
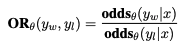
- 선택할(=선호하는) 응답 y_w, 거절할(=비선호하는) 응답 y_l이 주어질 때
- 오즈비 OR은 모델이 y_l 대비 y_w을 생성할 가능성을 나타냄
ORPO의 objective function
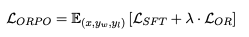
- supervised fine-tuning loss(L_sft)와 relative ratio loss(=L_or)의 결합
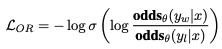
- relative ratio loss는 log odds ratio를 log sigmoid function으로 감싸준 형태
- 이러한 loss를 사용함으로써 잘못된 예측에 페널티를 줄 수 있으며, 선택할 응답과 거절할 응답을 대조시킬 수 있음
평가
모델
- OPT 모델 (125M - 1.3B)
- 보상 모델은 OPT-350M, OPT-1.3B 기반으로 학습 (RM-350M, RM-1.3B로 논문에 표기)
- Phi-2 (2.7B)
- Llama-2 (7B)
- Mistral (7B)
데이터셋 (preference alignment)
- HH-RLHF by Anthropic
- Binarized UltraFeedback
평가 리더보드
- AlpacaEval_1.0
- GPT-4를 활용해 text-davinci-003이 생성한 응답보다 학습된 모델의 응답이 선호되는지 평가
- AlpacaEval_2.0
- GPT-4-turbo를 활용해 GPT-4가 생성한 응답보다 학습된 모델의 응답이 선호되는지 평가
- MT-Bench
- GPT-4를 사용해 멀티턴 대화에서 학습된 모델이 어려운 답을 가진 설명(instruction)을 따르는지 평가
평가 결과
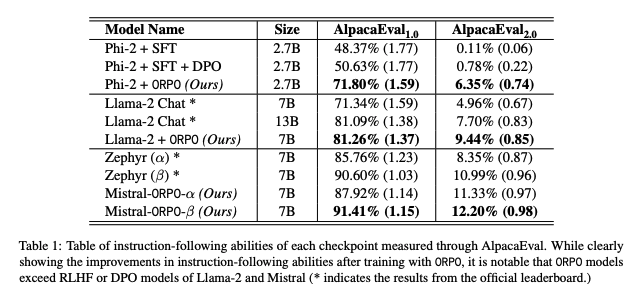
- ORPO로 학습한 경우 RLHF, DPO로 학습할 때보다 설명(instruction)을 따르는 능력이 향상
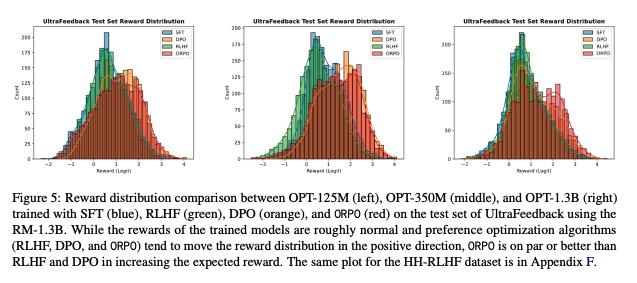
- 보상 분포(reward distribution)의 경우 RLHF, DPO, ORPO와 같은 선호 최적화 알고리즘을 통해 긍정적인 방향으로 이동
- OPRO의 경우 RLHF, DPO보다 더욱 좋은 결과

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab