RLHF (Reinforcement Learning from Human Feedback)
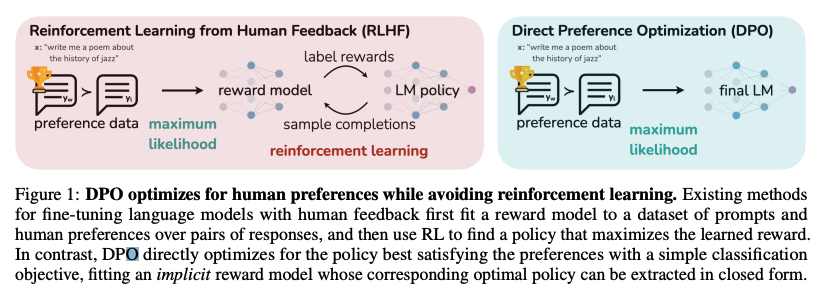
- 일반적인 RLHF 학습방법
- 지도학습 방식의 파인튜닝 (supervised fine-tuning)
- 선호하는 정답을 가진 데이터를 지정
- 선호 데이터를 기반으로 보상 모델을 학습
- 강화학습을 기반으로 한 최적화 단계
- KL-divergence 제약을 바탕으로 보상이 최대화되도록 학습
- RLHF의 단점
- 별도의 보상모델을 학습하는 과정 필요 (여러 개의 언어모델 학습)
- 학습을 위해선 언어모델(LM Policy)로부터 반복적으로 샘플링을 해야 해 연산 비용 증가
DPO (Direct Preference Optimization)
- DPO의 학습 방법
- 지도학습 방식의 파인튜닝 (supervised fine-tuning)
- 선호하는 정답을 가진 데이터를 지정
- 선호 데이터를 기반으로 직접 최적화 진행
- DPO의 장점
- 별도의 보상모델을 학습할 필요 없이 언어모델을 직접 최적화
- DPO loss로 살펴보는 직관적 해석

- r은 내재적으로 정의된 보상을 의미
- DPO loss는 선호되는 응답인 y_w의 확률을 높이고, 선호되지 않는 응답인 y_l의 확률을 낮춤
- 데이터 예시들은 내재적 보상 모델의 예측의 틀린 정도에 따라 가중치 부여
- 보상 예측이 틀린다면 더 높은 가중치를 부여
- 해당 가중치가 없을 경우 언어모델의 성능이 떨어짐 (중요한 계수)
- KL-diversity 제약의 중요성을 설명해준다고 해석할 수도 있음
- 해당 가중치는 beta의 크기에 따라 스케일링됨
HuggingFace에서 DPO 구현하기
TRL에 있는 DPOTrainer 활용
- 해당 Trainer를 사용하기 위해서는, 특정한 방식의 데이터 형식이 필요
- prompt: 텍스트 생성을 위한 추론 시 모델에게 주어지는 맥락 프롬프트
- chosen: 프롬프트에 적절한 선호되는 응답
- rejected: 프롬프트에 적절하지 않은, 선호되지 않는 응답
dpo_trainer = DPOTrainer(
model, # 파인튜닝 시 사용하는 기본 모델
model_ref, # 일반적으로 기본 모델의 복사본
beta=0.1, # DPO loss의 하이퍼파라미터
train_dataset=dataset, # DPO 데이터셋
tokenizer=tokenizer, # 토크나이저
args=training_args, # 배치사이즈, 학습률 등
)- 하이퍼파라미터 beta
- 일반적으로 0.1-0.5 사이 범위
- 참조 모델(reference model)에 얼마나 주의를 기울일 것인가
- 참조 모델이란, DPO를 진행하기 전 SFT(supervised fine-tuning) 단계를 거친 기존 모델이라고 생각할 수 있음
- beta가 작을수록 참조 모델을 더욱 무시한다고 보면 됨
HuggingFace 블로그 링크: https://huggingface.co/blog/dpo-trl
DPO 논문 링크: https://arxiv.org/pdf/2305.18290.pdf

Graduate student at Seoul National University, majoring in Artificial Intelligence (NLP). Currently AI Researcher and Engineer at LG CNS AI Lab
그렇다면 model_ref 말고 model은 SFT를 거치지 않는걸까요?