
[ 버퍼 ]
NIO에서는 데이터를 입출력하기 위해 항상 버퍼를 사용해야 한다.
- 버퍼는 읽고 쓰기가 가능한 메모리 배열이다.
- 버퍼를 이해하고 잘 사용할 수 있어야 NIO에서 제공하는 API를 올바르게 활용할 수 있다.
1. Buffer 종류
Buffer는 저장되는 데이터 타입에 따라 분류될 수 있고 어떤 메모리를 사용하느냐에 따라 다이렉트(Direct)와 넌다이렉트(NonDirect)로 분류할 수도 있다.
1) 데이터 타입에 따른 버퍼
NIO 버퍼는 저장되는 데이터 타입에 따라서 별도의 클래스로 제공된다.
- 이 버퍼 클래스들은
Buffer추상 클래스를 모두 상속하고 있다.
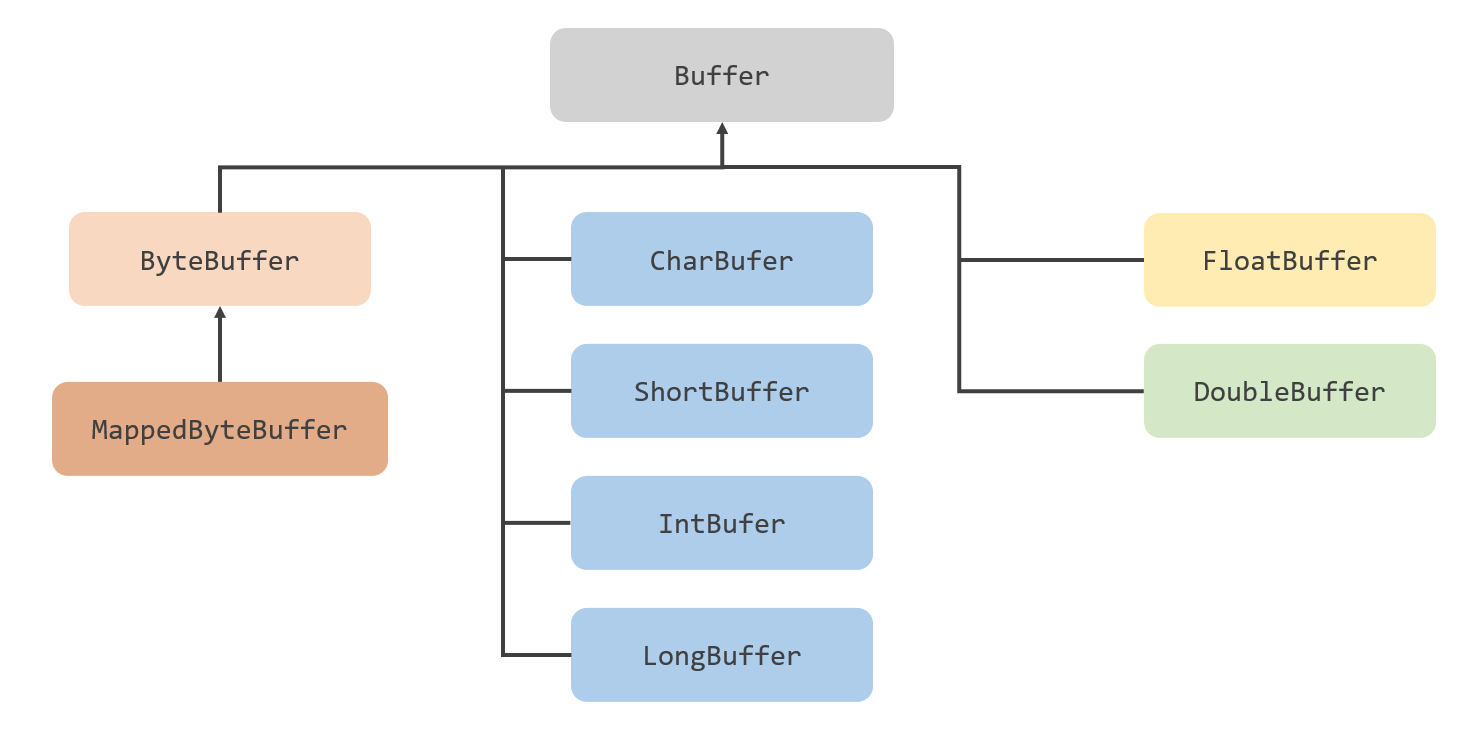
버퍼 클래스의 이름을 보면 어떤 데이터가 저장되는 버퍼인지 쉽게 알 수 있다.
ByteBuffer,CharBuffer,ShortBuffer,IntBuffer,LongBuffer,FloatBuffer,DoubleBuffer는 각각byte,char,int,long,float,double데이터가 저장되는 버퍼이다.MappedByteBuffer는ByteBuffer의 하위 클래스로 파일의 내용에 랜덤하게 접근하기 위해서 파일의 내용을 메모리와 맵핑시킨 버퍼이다.
2) 넌다이렉트와 다이렉트 버퍼
버퍼가 사용하는 메모리의 위치에 따라서
넌다이렉트(non-direct) 버퍼와다이렉트(direct) 버퍼로 분류된다.
넌다이렉트 버퍼는 JVM이 관리하는 힙 메모리 공간을 이용하는 버퍼이고,다이렉트 버퍼는 운영체제가 관리하는 메모리 공간을 이용하는 버퍼이다.
| 구분 | 넌다이렉트 버퍼 | 다이렉트 버퍼 |
|---|---|---|
| 사용하는 메모리 공간 | JVM의 힙 메모리 | 운영체제의 메모리 |
| 버퍼 생성 시간 | 버퍼 생성 빠름 | 버퍼 생성 느림 |
| 버퍼의 크기 | 작음 | 큼 (큰 데이터를 처리할 때 유리) |
| 입출력 성능 | 낮음 | 높음 (입출력이 빈번할 때 유리) |
- 넌다이렉트 버퍼는 JVM 힙 메모리를 사용하므로 버퍼 생성 시간이 빠르지만,
다이렉트 버퍼는 운영체제의 메모리를 할당받기 위해 운영체제의네이티브(native) C 함수를 호출해야 하고 여러 가지 잡다한 처리를 해야 하므로 상대적으로 버퍼 생성이 느리다.- 그렇기 때문에 다이렉트 버퍼는 자주 생성하기 보다는 한 번 생성해 놓고 재사용하는 것이 적합하다.
- 넌다이렉트 버퍼는 JVM의 제한된 힙 메모리를 사용하므로 버퍼의 크기를 크게 잡을 수가 없지만,
다이렉트 버퍼는 운영체제가 관리하는 메모리를 사용하므로 운영체제가 허용하는 범위 내에서 대용량 버퍼를 생성시킬 수 있다. - 넌다이렉트 버퍼는 입출력을 하기 위해 임시 다이렉트 버퍼를 생성하고 넌다이렉트 버퍼에 있는 내용을 임시 다이렉트 버퍼에 복사한다. 그리고 나서 임시 다이렉트 버퍼를 사용해서 운영체제의
native I/O기능을 수행한다. 그렇기 때문에 직접 다이렉트 버퍼를 사용하는 것보다는 입출력 성능이 낮다. - 다이렉트 버퍼는 채널(Channel)을 사용해서 버퍼의 데이터를 읽고 저장할 경우에만 운영체제의
native I/O를 수행한다. 만약 채널을 사용하지 않고ByteBuffer의get()/put()메소드를 사용해서 버퍼의 데이터를 읽고, 저장한다면 이 작업은 내부적으로 JNI를 호출해서native I/O를 수행하기 때문에 JNI 호출이라는 오버 헤더가 추가된다. 그렇기 때문에 오히려 넌다이렉트 버퍼의get()/put()메소드 성능이 더 좋게 나올 수도 있다.
📌
JNI(Java Native Interface)는 자바 코드에서 C함수를 호출할 수 있도록 해주는 API이다.
2. Buffer 생성
각 데이터 타입별로
- 넌다이렉트 버퍼를 생성하기 위해서는 각
Buffer클래스의allocate()와wrap()메소드를 호출하면 되고,- 다이렉트 버퍼는
ByteBuffer의allocateDirect()메소드를 호출하면 된다.
✅ allocate() 메소드
JVM 힙 메모리에 넌다이렉트 버퍼를 생성한다.
- 매개값은 해당 데이터 타입의 저장 개수를 말한다.
| 리턴 타입 | 메소드(매개 변수) | 설명 |
|---|---|---|
| ByteBuffer | ByteBuffer.allocate(int capacity) | capacity개만큼의 byte값을 저장 |
| CharBuffer | CharBuffer.allocate(int capacity) | capacity개만큼의 char값을 저장 |
| DoubleBuffer | DoubleBuffer.allocate(int capacity) | capacity개만큼의 double 값을 저장 |
| FloatBuffer | FloatBuffer.allocate(int capacity) | capacity개만큼의 float값을 저장 |
| IntBuffer | IntBuffer.allocate(int capacity) | capacity개만큼의 int값을 저장 |
| LongBuffer | LongBuffer.allocate(int capacity) | capacity개만큼의 long 값을 저장 |
| ShortBuffer | ShortBuffer.allocate(int capacity) | capacity개만큼의 short값을 저장 |
예제
- 최대 100개의 바이트를 저장하는
ByteBuffer를 생성하고, 최대 100개의 문자를 저장하는CharBuffer를 생성
ByteBuffer byteBuffer = ByteBuffer.allocate(100);
CharBuffer charBuffer = CharBuffer.allocate(100);✅ wrap() 메소드
각 타입별 Buffer 클래스는 모두 wrap() 메소드를 가지고 있는데, wrap() 메소드는 이미 생성되어 있는 자바 배열을 래핑해서 Buffer 객체를 생성한다. 자바 배열은 JVM 힙 메모리에 생성되므로 wrap()은 넌다이렉트 버퍼를 생성한다.
예제
- 길이가 100인
byte[]를 이용하여ByteBuffer를 생성하고, 길이가 100인char[]를 이용해서CharBuffer생성
byte[] byteArray = new byte[100];
ByteBuffer byteBuffer = ByteBuffer.wrap(byteArray);
char[] charArray = new char[100];
CharBuffer charBuffer = CharBuffer.wrap(charArray)l- 배열의 모든 데이터가 아니라 일부 데이터만 가지고
Buffer객체를 생성할 수도 있다. 이 경우 시작 인덱스와 길이를 추가적으로 지정하면 된다. - 다음은 0 인덱스부터 50개만 버퍼로 생성한다.
byte[] byteArray = new byte[100];
ByteBuffer byteBuffer = ByteBuffer.wrap(byteArray, 0, 50);
char[] charArray = new char[100];
CharBuffer charBuffer = CharBuffer.wrap(charArray, 0, 50);CharBuffer는 추가적으로CharSequence타입의 매개값으로 갖는wrap()메소드도 제공한다. String이CharSequence인터페이스를 구현했기 때문에 매개값으로 문자열을 제공해서 다음과 같이CharBuffer를 생성할 수도 있다.
CharBuffer charBuffer = CharBuffer.wrap("NIO 입출력은 버퍼를 이용한다.");✅ allocateDirect() 메소드
ByteBuffer의allocateDirect()메소드는 JVM 힙 메모리 바깥쪽, 즉 운영체제가 관리하는 메모리에 다이렉트 버퍼를 생성한다.
- 이 메소드는 각 타입별 Buffer 클래스에는 없고,
ByteBuffer에서만 제공된다. - 각 타입별로 다이렉트 버퍼를 생성하고 싶다면 우선
ByteBuffer의allocateDirect()메소드로 버퍼를 생성한 다음ByteBuffer의asCharBuffer(),asShortBuffer(),asIntBuffer(),asLongBuffer(),asFloatBuffer(),asDoubleBuffer()메소드를 이용해서 해당 타입별Buffer를 얻으면 된다.
예제
100개의 바이트(byte)를 저장하는 다이렉트ByteBuffer와50개의 문자(char)를 저장하는 다이렉트CharBuffer,25개의 정수(int)를 저장하는 다이렉트IntBuffer생성char는2바이트크기를 가지고,int는4바이트크기를 가지기 때문에 초기 다이렉트ByteBuffer생성 크기에 따라 저장 용량이 결정된다.
//100개의 byte값 저장
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(100);
//50개의 char값 저장
CharBuffer charBuffer = ByteBuffer.allocateDirect(100).asCharBuffer();
//25개의 int값 저장
IntBuffer intBuffer = ByteBuffer.allocateDirect(100).asIntBuffer();✅ Byte 해석 순서(ByteOrder)
데이터를 처리할 때 바이트 처리 순서는 운영체제마다 차이가 있다. 이러한 차이는 데이터를 다른 운영체제로 보내거나 받을 때 영향을 미치기 때문에 데이터를 다루는 버퍼도 이를 고려해야 한다.
- 앞쪽 바이트부터 먼저 처리하는 것을
Big Endian, - 뒤쪽 바이트부터 먼저 처리하는 것을
Little Endian이라고 한다.
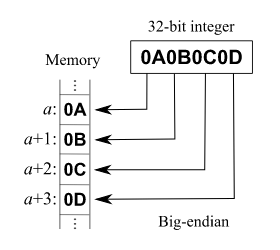
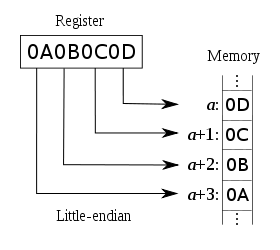
Little Endian으로 동작하는 운영체제에서 만든 데이터 파일을 Big Endian으로 동작하는 운영체제에서 읽는다면 ByteOrder 클래스로 데이터 순서를 맞춰야 한다. ByteOrder 클래스의 nativeOrder() 메소드는 현재 동작하고 있는 운영체제가 Big Endian인지 Little Endian인지 알려준다. JVM도 일종의 독립된 운영체제이기 때문에 이런 문제를 취급하는데, JRE가 설치된 어떤 환경이든 JVM은 무조건 Big Endian으로 동작하도록 되어 있다.
운영체제가 JVM의 바이트 해석 순서가 다를 경우에는 JVM이 운영체제와 데이터를 교환할 때 자동적으로 처리해주기 때문에 문제는 없다. 하지만 다이렉트 버퍼일 경우 운영체제의 native I/O를 사용하므로 운영체제의 기본 해석 순서로 JVM의 해석 순서를 맞추는 것이 성능에 도움이 된다.
다음과 같이 allocateDirect()로 버퍼를 생성한 후, order() 메소드를 호출해서 nativeOrder()의 리턴값으로 세팅해주면 된다.
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(100).order(ByteOrder.nativeOrder()));[ 참고자료 ]
이것이 자바다 책
