
이 글은 책 「가상 면접 사례로 배우는 대규모 시스템 설계 기초」를 공부하고 정리한 글입니다.

1장 「사용자 수에 따른 규모 확장성」에서는 규모 확장성과 관계된 설계 문제를 푸는 데 쓰일 유용한 지식들을 다룬다.
[ 단일 서버 ]
복잡한 시스템을 만들 때, 모든 컴포넌트가 단 한 대의 서버에서 실행되는 간단한 시스템부터 설계를 하는 것이 좋다.
다음 그림은 이 구성의 실제 사례로, 웹 앱, 데이터베이스, 캐시 등이 전부 서버 한 대에서 실행된다.
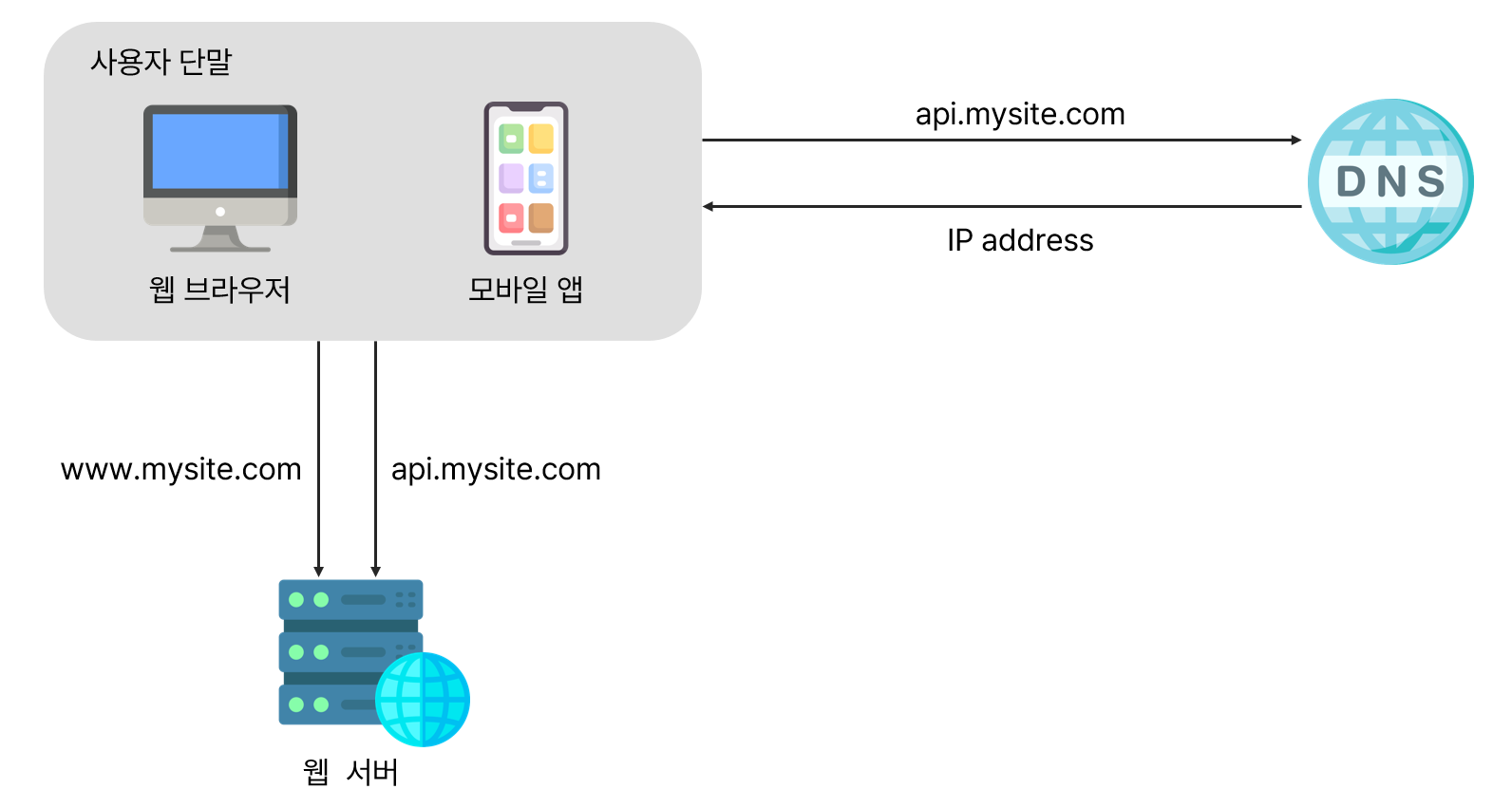
사용자 요청이 처리되는 과정과 요청을 만드는 단말에 대해서 이해가 필요하다.
사용자 요청 처리 흐름
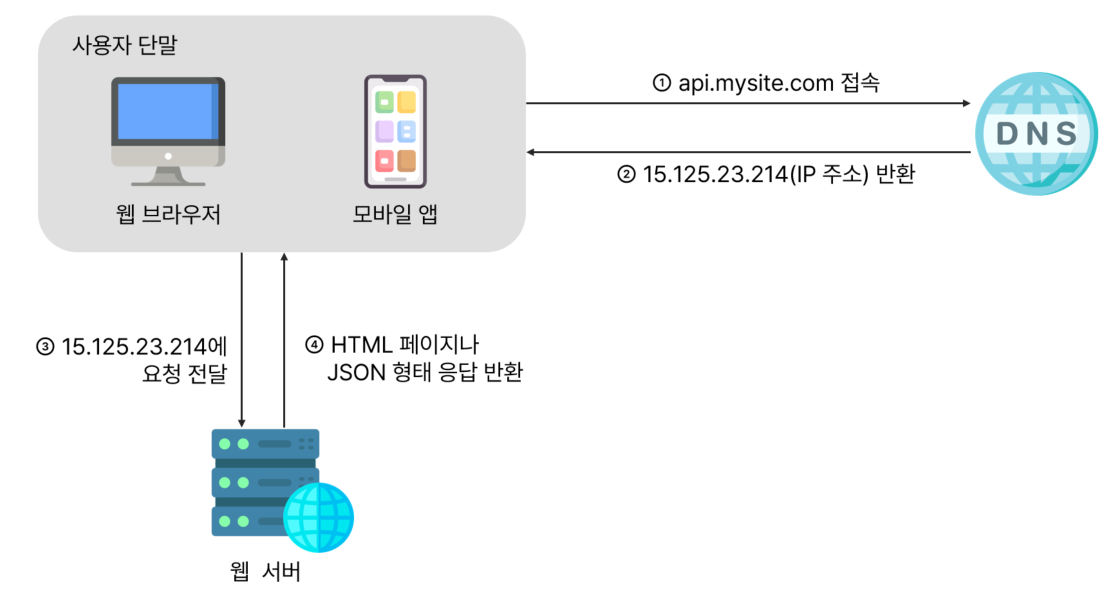
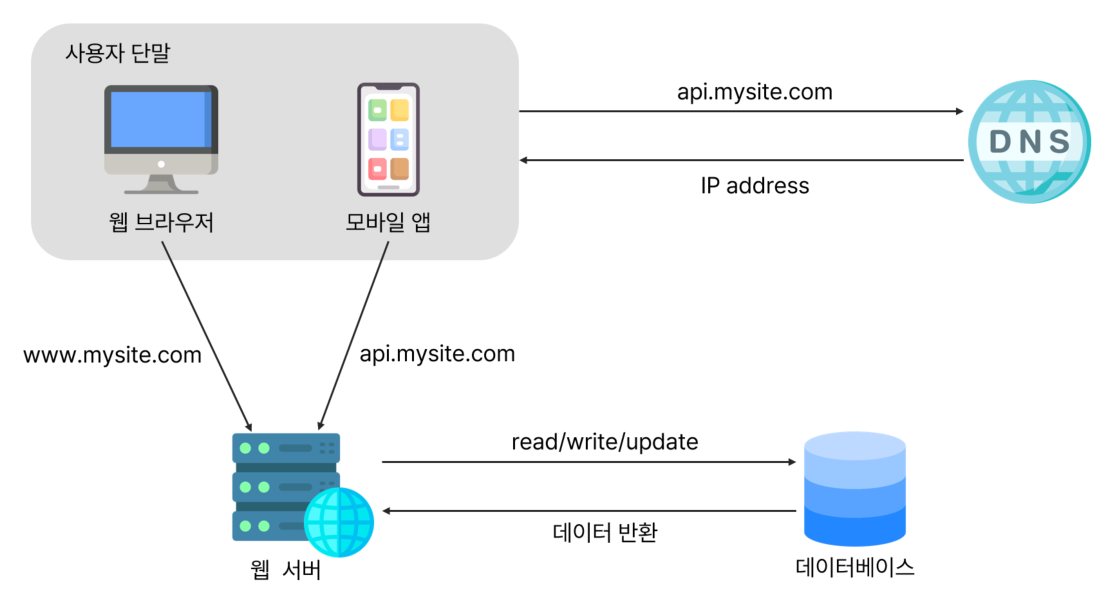
1. 사용자는 도메인 이름(api.mysite.com)을 이용하여 웹사이트에 접속한다.
- 접속을 위해서는 도메인 이름을 도메인 이름 서비스(DNS)에 질의하여 IP주소로 변환하는 과정이 필요하다.
- DNS는 보통
제3 사업자(third party)가 제공하는 유료 서비스를 이용하게 되므로, 우리 시스템의 일부는 아니다.
2. DNS 조회 결과로 IP 주소가 반환된다.
- 웹 서버의 주소인
15.125.23.214가 반환된다.
3. 해당 IP 주소로 HTTP 요청이 전달된다.
4. 요청을 받은 웹 서버는 HTML 페이지나 JSON 형태의 응답을 반환한다.
- 이 요청들은 다음 두 가지 종류의 단말로부터 온다.
- 웹 애플리케이션: 비즈니스 로직, 데이터 저장 등을 처리하기 위해서는 서버 구현용 언어(자바, 파이썬)를 사용하고, 프레젠테이션용으로는 클라이언트 구현용 언어(HTML, 자바스크립트 등)를 사용한다.
- 모바일 앱: 모바일 앱과 웹 서버 간 통신을 위해서는 HTTP 프로토콜을 이용한다. HTTP 프로토콜을 통해서 반환될 응답 데이터의 포맷으로는 보통 JSON이 그 간결함 덕에 널리 쓰인다.
[ 데이터베이스 ]
사용자가 늘면 서버 하나로는 부족하므로 서버를 늘려야 한다. 웹/모바일 트래픽 처리 용도와 데이터베이스용이다. 웹/모바일 트래픽 처리 서버(웹 계층)와 데이터베이스 서버(데이터 계층)을 분리하면 그 각각을 독립적으로 확장해 나갈 수 있다.
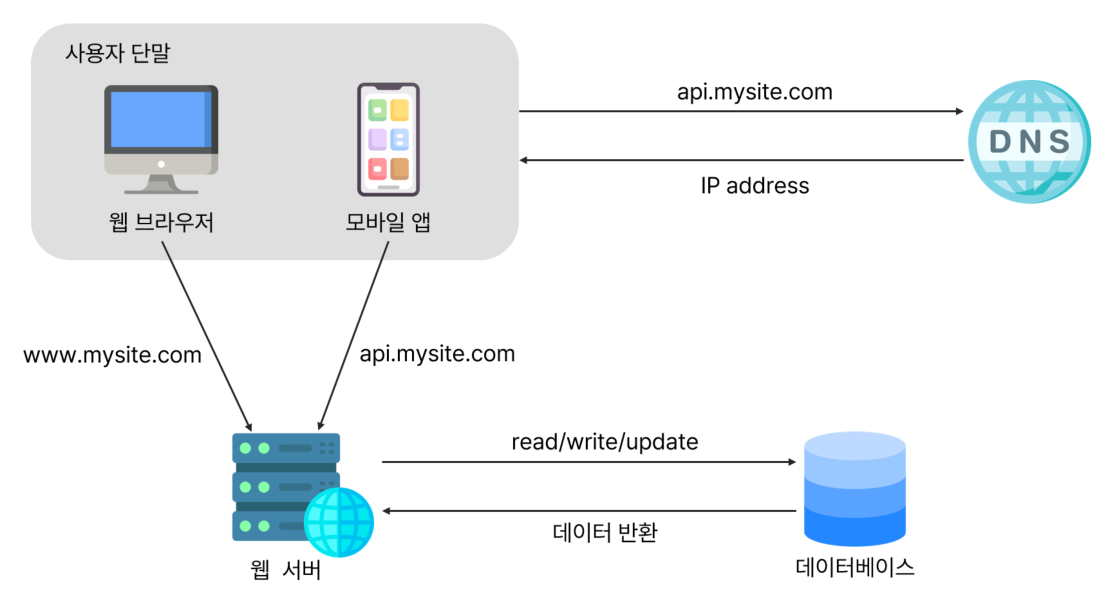
어떤 데이터베이스를 선택해야 할까?
데이터베이스는 크게 관계형 데이터베이스(relational database)와 비-관계형 데이터베이스 사이로 나눌 수 있다.
✅ 관계형 데이터베이스 (SQL)
- 관계형 데이터베이스는
관계형 데이터베이스 관리 시스템(RDBMS)이라고도 부른다. - MySQL, Oracle, PostgreSQL 등이 있다.
- 자료를 테이블과 열, 칼럼으로 표현한다.
- SQL을 사용하면 여러 테이블에 있는 데이터를 그 관계에 따라
조인(join)할 수 있다.
✅ 비 관계형 데이터베이스 (NoSQL)
- CouchDB, Neo4j, MongoDB, Amazon DyamoDB 등이 있다.
- 다음 네 부류로 나뉜다.
- 키-값 저장소(key-value store)
- 그래프 저장소(graph store)
- 칼럼 저장소(column store)
- 문서 저장소(document store)
- 비 관계형 데이터베이스는 일반적으로 조인 연산을 지원하지 않는다.
✅ 관계형 데이터베이스를 사용하기 좋은 상황은?
- 대부분의 상황의 경우 관계형 데이터베이스가 최선!
- 관계를 맺고 있는 데이터나 자주 변경이 발생하는 애플리케이션을 만들 때
- 구조가 변경될 여지가 없고, 명확하고 정확한 데이터가 보장되어야 하는 경우
- Ex) 상품 주문 및 내역 관리 시스템
✅ 비 관계형 데이터베이스를 사용하기 좋은 상황은?
- 아주 낮은 응답 지연시간(latency)이 요구될 때
- 다루는 데이터가 비정형(unstructured)이라 관계형 데이터가 아닐 때
- 데이터(JSON, YAML, XML 등)를 직렬화하거나 역직렬화 할 수 있기만 하면 될 때
- 아주 많은 양의 데이터를 저장해야 할 때
- Ex) SNS 친구 관계 및 피드 데이터
[ 수직적 규모 확장 vs 수평적 규모 확장 ]
더 많은 서버 용량과 성능이 필요할 때, 수직적 규모 확장/수평적 규모 확장 두 가지 방법으로 시스템을 확장시킬 수 있다.
수직적 규모 확장 vs 수평적 규모 확장
1. 수직적 규모 확장 (Vertical Scaling)
스케일 업(scale up)이라고도 한다.- 서버에 고사양 자원(더 좋은 CPU, 더 많은 RAM 등)을 추가하는 행위를 말한다.
- 예를 들어,
1의 처리 능력을 가진 서버 한 대를5의 처리 능력을 가진 서버로 업그레이드시키는 것을 말한다. - 서버 한 대에 모든 부하가 집중되므로 장애 시 영향을 크게 받을 수 있는 위험성이 있다.
- 한 대의 서버에서 모든 데이터를 처리하므로 데이터 갱신이 빈번하게 일어나는
데이터베이스 서버에 적합한 방식이다.
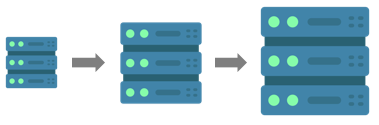
2. 수평적 규모 확장 (Horizontal Scaling)

스케일 아웃(scale out)이라고도 한다.- 더 많은 서버를 추가하여 성능을 개선하는 행위를 말한다.
- 예를 들어
1의 처리 능력을 가진 서버 한 대에 동일한 서버 4개를 추가하여 총5의 처리 능력을 만드는 것이다. - 서버가 여러 대가 되기 때문에 각 서버에 걸리는 부하를 균등하게 해주는
로드밸런싱이 필수적으로 동반되어야 한다. - 서버 한 대가 장애로 다운되더라도 다른 서버로 서비스 제공이 가능하다는 장점이 있다.
- 모든 서버가 동일한 데이터를 가지고 있어야 하므로, 데이터 변화가 적은
웹 서버에 적합한 방식이다.
3. 어떤 것을 선택해야 할까?
수직적 규모 확장(scale up)은
- 수평적 규모 확장보다 관리 비용이나 운영 이슈가 적고, 사양만 올리면 된다. → 단순하다.
- 서버로 유입되는 트래픽의 양이 적을 때 적합하다.
- 한 대의 서버에 CPU나 메모리를 무한대로 증설할 방법이 없으므로, 한계가 있다.
- 수직적 규모 확장법은 장애에 대한
자동복구(failover)방안이나다중화(redundancy)방안을 제시하지 않는다. 서버에 장애가 발생하면 웹사이트/앱은 완전히 중단된다.
수평적 규모 확장(scale out)은
- 하드웨어 관점에서 확장이 쉽다.
- 대규모 애플리케이션을 지원할 때 적합하다.
- 유지 관리 및 운영의 복잡성이 증가한다.
- 여러 대의 서버는 단일 서버보다 유지 관리가 더 어려우며,
로드 밸런싱을 추가해야 한다.
- 여러 대의 서버는 단일 서버보다 유지 관리가 더 어려우며,
📌 서버로 유입되는 트래픽의 양이 적을 때는
수직적 규모 확장(scale up),
대규모 애플리케이션을 지원할 때는수평적 규모 확장(scale out)이 적합하다.
로드밸런서 (Load Balancer)
✅ 앞선 설계의 문제점
앞선 설계는 사용자가 웹 서버에 바로 연결되는데, 이런 설계는 다음과 같은 문제가 발생할 수 있다.
- 웹 서버가 다운되면 사용자는 웹 사이트에 접속할 수 없다.
- 너무 많은 사용자가 접속하여 웹 서버가 한계 상황에 도달하게 되면 응답 속도가 느려지거나 서버 접속이 불가능해질 수도 있다.
이런 문제를 해결하기 위해서는 로드밸런서(load balancer)를 도입하는 것이 최선이다.
✅ 로드밸런서 도입
부하 분산 집합(load balancing set)에 속한 웹 서버들에게 트래픽 부하를 고르게 분산하는 역할을 한다.
로드밸런서의 동작은 다음과 같다.
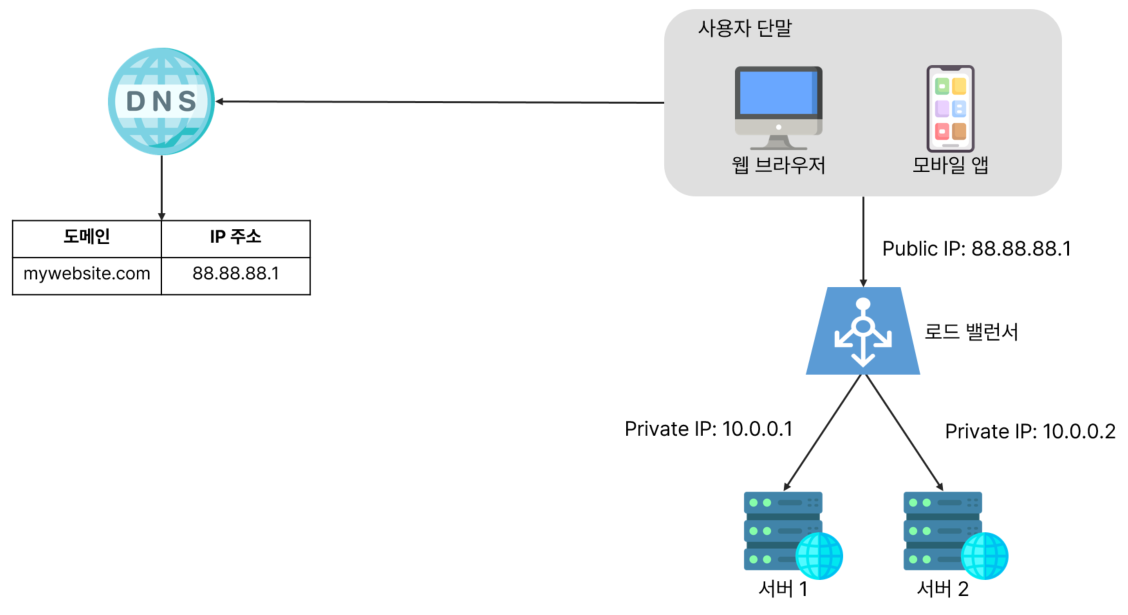
사용자는 로드밸런서의
공개 IP 주소(public IP address)로 접속하며,
이제 웹 서버는 클라이언트의 접속을 직접 처리하지 않는다.
- 더 나은 보안을 위해, 서버 간 통신에는
사설 IP 주소(private IP address)가 이용되며, 로드밸런서는 웹 서버와 통신하기 위해 바로 이 사설 주소를 이용한다. - 사설 IP 주소는 같은 네트워크에 속한 서버 사이의 통신에만 쓰일 수 있는 IP 주소로, 인터넷을 통해서는 접속할 수 없다.
부하 분산 집합에 또 하나의 웹 서버를 추가하고 나면
장애를 자동복구하지 못하는 문제(no failover)는 해소되며, 웹 계층의가용성(availability)은 향상된다.
장애 극복 기능 (failover): 컴퓨터 서버, 시스템, 네트워크 등에서 이상이 생겼을 때 예비 시스템으로 자동 전환되는 기능가용성(availability): 서버와 네트워크, 프로그램 등의 정보 시스템이 정상적으로 사용 가능한 정도
- 서버 1이 다운되면(offline) 모든 트래픽은 서버 2로 전송되므로 웹 사이트 전체가 다운되는 일이 방지된다. 부하를 나누기 위해 새로운 서버를 추가할 수도 있다.
- 웹사이트로 유입되는 트래픽이 가파르게 증가하면 두 대의 서버로 트래픽을 감당할 수 없는 시점이 오는데, 로드밸런서가 있으므로 걱정하지 않아도 된다. 웹 서버 계층에 더 많은 서버를 추가하기만 하면 로드밸런스가 자동적으로 트래픽을 분산하기 시작할 것이다.
데이터베이스 다중화
이제 웹 계층은 괜찮아 보이지만, 현재 설계안에는 하나의 데이터베이스 서버뿐이고, 역시 장애의 자동복구나 다중화를 지원하는 구성이 아니다. 데이터베이스 다중화는 이런 문제를 해결하는 보편적인 기술이다.
"많은 데이터베이스 관리 시스템이 다중화를 지원한다. 보통은 서버 사이에 주(master)-부(slave) 관계를 설정하고 데이터 원본은 주 서버에, 사본은 부 서버에 저장하는 방식이다." - 위키피디아
- 쓰기 연산(write operation)은 마스터(주 데이터베이스)에서만 지원한다.
- 부 데이터베이스는 주 데이터베이스로부터 그 사본을 전달받으며, 읽기 연산(read operation)만을 지원한다.
- 데이터베이스를 변경하는 명령어들(
insert,delete,update등)은 주 데이터베이스로만 전달되어야 한다.
대부분의 애플리케이션은 읽기 연산의 비중이 쓰기 연산보다 훨씬 높기 때문에 통상 부 데이터베이스의 수가 주 데이터베이스의 수보다 많다.
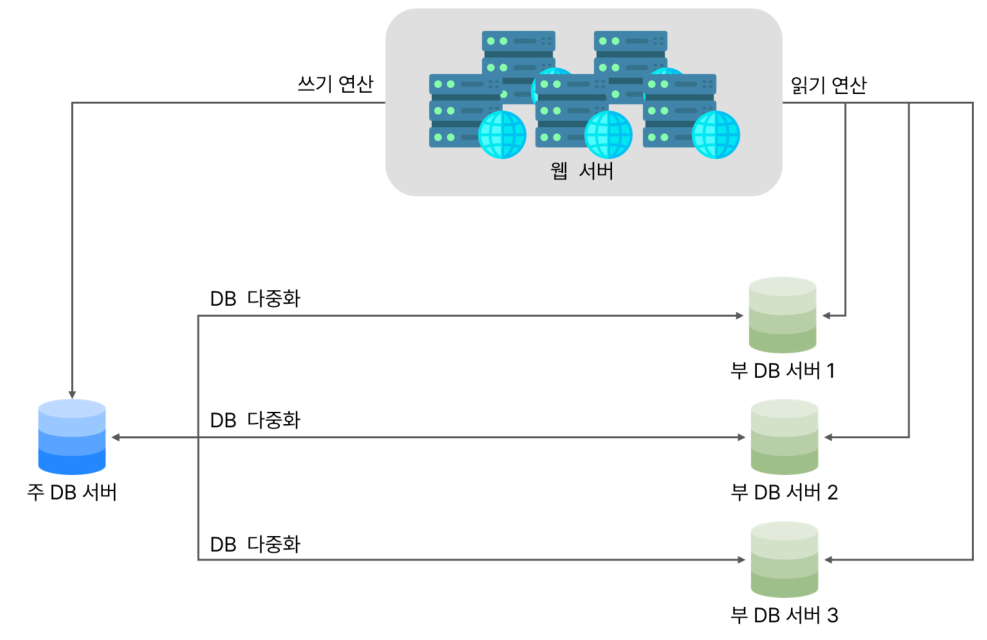
✅ 데이터베이스를 다중화하면 다음과 같은 이득이 있다.
- 더 나은 성능: 주-부 다중화 모델에서 모든 데이터 변경 연산은 주 데이터베이스 서버로만 전달되는 반면 읽기 연산은 부 데이터베이스 서버들로 분산된다. 병렬로 처리될 수 있는 질의(query) 수가 늘어나므로, 성능이 좋아진다.
- 안정성(reliability): 데이터를 지역적으로 떨어진 여러 장소에 다중화시켜 놓을 수 있기 때문에, 자연 재해 등의 이유로 데이터베이스 서버 가운데 일부가 파괴되어도 데이터는 보존될 것이다.
- 가용성(availability): 데이터를 여러 지역에 복제해 둠으로써, 하나의 데이터베이스 서버에 장애가 발생하더라도 다른 서버에 있는 데이터를 가져와 계속 서비스할 수 있게 된다.
✅ 만약 데이터베이스 서버 가운데 하나가 다운된다면?
부 서버가 한 대 뿐인데 다운된 경우?
- 읽기 연산은 한시적으로 모두 주 데이터베이스로 전달될 것이다.
- 또한 즉시 새로운 부 데이터베이스 서버가 장애 서버를 대체할 것이다.
부 서버가 여러 대일 때, 부 서버 한 대가 다운된 경우?
- 읽기 연산은 나머지 부 데이터베이스 서버들로 분산될 것이며,
- 새로운 부 데이터베이스 서버가 장애 서버를 대체할 것이다.
주 데이터베이스 서버가 다운되면?
- 한 대의 부 데이터베이스만 있는 경우
- 해당 부 데이터베이스 서버가 새로운 주 서버가 될 것이다.
- 모든 데이터베이스 연산은 일시적으로 새로운 주 서버상에서 수행되며 새로운 부 서버가 추가될 것이다.
프로덕션(production) 환경에서 벌어지는 일은 이것보다는 사실 더 복잡한데, 부 서버에 보관된 데이터가 최신 상태가 아닐 수 있기 때문이다. 없는 데이터는복구 스크립트(recovery script)를 돌려서 추가해야 한다.
✅ 로드밸런서와 데이터베이스 다중화를 고려한 설계안
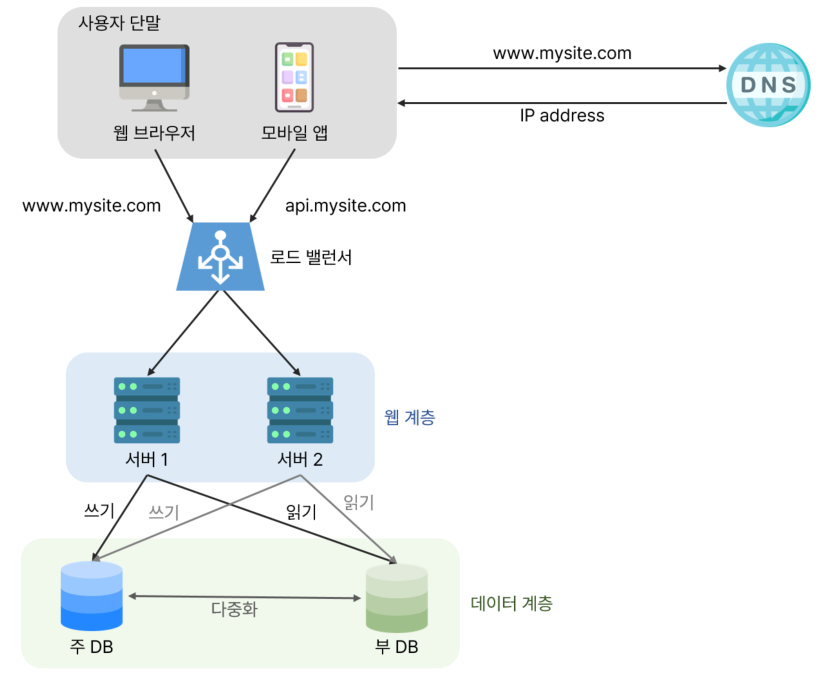
이 설계안은 다음과 같이 동작한다.
- 사용자는 DNS로부터 로드밸런서의 공개 IP 주소를 받는다.
- 사용자는 해당 IP 주소를 사용하여 로드밸런서에 접속한다.
- HTTP 요청은
서버 1이나서버 2로 전달된다. - 웹 서버는 사용자의 데이터를
부 데이터베이스 서버에서 읽는다. - 웹 서버는 데이터 변경 연산(데이터 추가, 삭제, 갱신 연산 등)은
주 데이터베이스로 전달한다.
[ 참고자료 ]
https://nathanh.tistory.com/135
https://library.gabia.com/contents/infrahosting/1222/
https://tecoble.techcourse.co.kr/post/2021-10-12-scale-up-scale-out/
