I. Computer란?
CPU와 메모리, 최소한의 I/O device가 들어간 하드위에 위에서 소프트웨어(OS – 프로세스 관리,
CPU Scheduling, 메모리 관리, 파일 시스템 관리, I/O device 관리 수행)가 돌아가는 장치를 말한다.
II. Computer의 종류
A. 다수의 요청을 받아 처리하는 Server Computer
B. 특정 목적에 맞게 최적화 된 Embedded Computer
C. Personal Computer (Desktop, Laptop)
III. Computer의 구성
CPU, Memory, I/O device(+ I/O device controller)가 버스 구조(한 번에 한 쌍만 상호작용 가능한 토폴로지)
로 구성되어 있다. CPU는 I/O device가 아닌 I/O device의 controller에게 명령을 내리게 된다.
IV. Modern PC Architecture
CPU와 주고받는 데이터가 많은 곳(memory controller hub)의 버스가 I/O controller hub 쪽의 버스보다
대역폭이 크다.
V. OS의 역할
OS 하드웨어 자원을 편리하고 효율성 있게 사용할 수 있게 관리해주는 resource manager이다.
(개발자가 하드웨어 자원을 직접 관리하지 않고 운영체제가 대신 해준다.)
A. Abstraction
1. 운영체제는 하드웨어의 자원을 추상화 하여 사용자가 구체적인 작동 내용을 몰라도 된다.
B. Sharing
1. - Time Multiplexing: 운영체제는 CPU가 빠르게 프로세스를 바꾸어 가며 작업을 수행할 수 있게 한다.
2. - Space Multiplexing: 운영체제는 프로세스가 메모리 공간을 어떻게 나눠서 쓰거나 공유해서
쓸지 관리 한다.
C. Protection
1. 운영체제는 특정 프로세스가 다른 프로세스가 점유중인 메모리 공간에서의 데이터를 바꾸거나
접근할 수 없게 한다.
D. Fairness
1. 운영체제는 특정 프로세스가 하드웨어를 독점하지 못하게 한다.
E. Performance
1. 운영체제는 하드웨어의 자원을 낭비하지 않고 최선의 성능을 낼 수 있게 한다.
VI. CPU의 Architecture
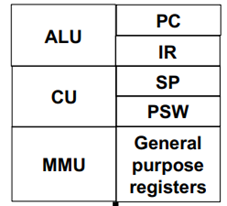
CPU는 산술논리연산장치인 ALU, 프로그램의 실행 플로우를 제어 (Control)하는 CU, 메모리관리장치인 MMU,
여기에 더해 임시기억장치인 Register로 구성되어 있다. Register는 PC, IR, SP, PSW, GPR로 나뉘는데
각각의 역할은 다음과 같다.
A. PC(Program Counter): 메모리 속 코드영역에 존재하는 실행할 명령어들을 가르키는 레지스터이다.
B. IR(Instruction Register): PC가 가르키는 명령어를 가져와 저장하는 레지스터이다.
C. SP(Stack Pointer): 메모리 스택 영역(function call이 발생할 때마다 관련된 데이터들이 들어가게
되는 영역)의 맨 위를 가르키는 레지스터이다.
D. PSW: 프로세스의 상태를 저장하는 레지스터이다.
E. GPR(General Purpose Register): function call이 발생할 때 입력 파라미터를 저장하거나
이외의 다양한 목적으로 이용되는 레지스터이다.
VII. CPU Architecture(폰 노이만 아키텍처 vs 하버드 아키텍처)
CPU의 구조는 폰 노이만 아키텍처와 하버드 아키텍처로 나뉜다. 폰 노이만 아키텍처는 하나의
CPU가 하나의 메모리와 데이터를 주고 받는 구조이며, 하버드 아키텍처는 하나의 CPU가 두개의
메모리(하나의 메모리는 code 영역만 저장, 하나의 메모리는 상수, 전역변수 영역을 저장)와
데이터를 주고 받는다. 하버드 아키텍처는 메모리의 가용성을 최대로 높이기 어렵고 하드웨어
구조상 만들기 어렵다는 단점이 있지만 이러한 구조를 조금 변경한 XIP가 임베디드에서 주로
쓰이고 있다.
VIII. CPU Architecture(CISC vs RISC)
A. CISC: 자주 사용되는 최소한의 instruction들을 한번에 실행하는 구조인데, CPU 회로 설계가 복잡해지며 하드웨어 오버헤드가 발생한다.
B. RISC: 최소한의 instruction들을 각각 실행하는 구조이다. 여러번 instruction들을 수행하므로
오버헤드가 발생하지만 CISC의 하드웨어 오버헤드보다는 준수하다.
IX. RISC의 성능을 극대화 하는 Pipelining
CPU는 Fetch(PC가 지정한 instruction & 데이터 가져옴) -> Decode(instruction을 파악) ->
Execute (instruction을 실행) -> Write back(실행 후 바뀐 것을 메모리에 갱신)의 과정을 수행한다.
Pipelining은 F와 D, E와 W가 대부분 상호간 영향을 미치지 않는다는 점에서 탄생하였고, 최대 4배의
성능을 가질 수 있다.
하지만 항상 4배의 성능을 끌어올릴 수 없는데 이유는 다음과 같다.
A. 한 작업의 Execute 시간이 너무 길어서 같이 수행할 작업의 Decode 작업이 밀려날 수 있다.
B. 한 작업의 결과가 같이 수행하는 작업의 입력으로 들어가야 하는 경우가 있다 (dependency 존재)
C. CFI (Control Flow Instruction)이 수행 될 때 dependency가 발생할 수 있다.
X. 완벽한 병렬 처리를 위한 기법(ILP)
ILP는 pipeling이 완벽한 병렬 처리를 하지 못하는 점을 극복하는 Instruction-Level Parallelism 기법이다.
ILP의 예는 다음과 같다.
A. Superscalar: 런타임시 동적으로 동시에 실행시킬 수 있는 instruction이 있다고 판단하면 동시에 실행
B. VLIW: 컴파일시 동시에 실행시킬 수 있는 instruction이 있다고 판단하면 동시에 실행
C. Simultaneous Multithreading: 스레드가 여러 개인 것
D. Multi-Core: CPU속 코어가 여러 개인 것
XI. 병렬처리와 분산처리의 차이점
병렬처리(Parallel)는 한 시스템에서 여러 개의 CPU를 가져 여러 작업을 처리하는 것이고
분산처리(Distributed) 시스템은 개별 시스템을 네트워크로 모은 것을 의미한다.
XII. Bootstrapping 절차
A. 전원 on
B. CPU가 스스로 초기화하며 스스로 실행가능한 상태인지 점검 한다 (POST, power on self test)
C. CPU의 pc가 가르키는 BIOS의 시작 코드가 실행된다.
D. BIOS가 실행되며 메모리나 다른 I/O 디바이스들이 POST를 수행하게 한다.
E. BIOS는 boot device의 boot loader (LILO/GRUB)을 실행하고 권한을 넘긴다.
F. boot loader는 압축된 커널을 로딩한다.
G. 압축된 커널은 스스로 압축을 풀고 권한을 가지게 된다.
XIII. Interrupt의 종류
A. 소프트웨어 인터럽트(Trap): 프로세스에 의해 발생하며 프로세스는 I/O 디바이스를 컨트롤할 권한이 없기 때문에 권한을 가진 OS(Kernel)에게 시스템콜 인터페이스를 통해 I/O 작업을 요청해야 한다. 그리고 이때 소프트웨어 인터럽트(Trap)가 발생하게 된다.
B. 하드웨어 인터럽트: 주로 I/O 디바이스에 의해 발생하며 CPU 스스로 인터럽트를 거는 Timer 인터럽트도 하드웨어 인터럽트에 속한다.
C. Fault(Exception)에 의한 인터럽트: 숫자를 0으로 나눌 때나 Page Fault, Protection Fault가 발생할 때 일어난다.
XIV. DMA(Direct Memory Access)란?
I/O 작업을 완료할 때마다 인터럽트를 발생시켜 CPU에 알리는 형태가 아닌 한번 허가를 받고 메모리에 직접 엑세스 하여 I/O 작업을 쭉 처리하는 방식이다.
XV. 메모리 계층을 두는 이유
병목현상은 대부분 속도 차이가 있는 저장장치간 데이터를 주고받을 때 발생하는데, 이를 방지하기 위해 그 사이에 캐싱 계층을 두어야 하기 때문이다. Cache란 자주사용 되는 데이터를 더 빠른 장치에 미리 넣어두는 개념이다.
XVI. Caching Management Policy
A. Write Through: CPU가 작업을 수행하여 변경된 부분을 메모리에 반영하는데 이때 즉시 보조기억장치에도 변경 된 부분을 반영하는 기법이다. 이 방식은 오버헤드가 존재하지만 Context의 일관성(Coherency)을 증가시키는 장점이 있다.
B. Write Back: CPU가 유휴상태일 때 한번에 Write Through를 하는 방식이다 오버헤드가 감소하지만 Context의 일관성(Coherency)이 감소한다는 단점이 있다.
XVII. Hard Disk Arm Seek 시간을 줄이기 위한 방법
하드디스크의 인접한 영역(Track, Sector, Cylinder)에 연속적으로 데이터를 저장하는 방식을 이용하면 Arm Seek 시간을 줄일 수 있다.
XVIII. Hardware Protection
A. CPU Protection: 한 프로세스가 CPU를 계속 점유하는 것을 막는다. (이를 위해 Timer가 존재)
B. Memory Protection: Protection Fault가 발생했을 때 그걸 일으킨 프로세스를 죽인다.
C. I/O Protection: Dual Mode Operation을 통해 프로세스가 I/O 디바이스에 직접 접근하는 것을 막는다.
XIX. 컴퓨터의 발전 역사
A. 1세대 컴퓨터: 폰 노이만의 Eniac은 최초로 개발된 컴퓨터이며 크기가 큰 Vacuum Tube(진공관)이 들어가 있음, OS와 Programming Language, Assembly Language 없이 기계어만 사용하였다.
B. 2세대 컴퓨터: 진공관이 크기가 작은 트랜지스터로 바뀌면서 Batch System이 등장하였다 Batch System은 MultiProgramming(MultiProcessing)이 안되었기 때문에 CPU의 Utilization이 적으며 OS가 프로세스 관리를 안해도 되기 때문에 영향력이 적었다. 그렇기 때문에 이때 사용된 OS는 Resident Monitor라고 불린다.
C. 3세대 컴퓨터: Integrated Circuit(집적회로)가 발전하면서 3세대 컴퓨터가 나오게 되었다. MultiProgramming, Time-Sharing이 가능해지면서 2세대 컴퓨터의 단점이 사라졌다.
D. 4세대 컴퓨터: IC를 더 작게 하는 하드웨어 기술이 만들어지면서 MicroProcessor가 등장하게 되었고 이때부터 Personal Computer가 만들어지게 되었다.
