3.1 애그리거트
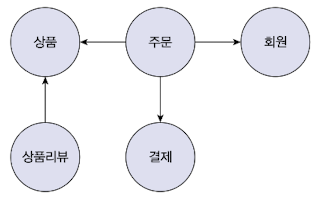
상위 수준에서 모델을 정리했을 때의 도메인 모델들이다. 상위 수준에서 모델을 정리하기 위해선 도메인 전문가와 많은 대화를 나눠야 상위 수준에서 모델 간의 관계가 이해가 된다.
많은 테이블을 한 장의 ERD에서 표현을 하고 테이블 간의 관계를 파악하느라 큰 틀에서 데이터 구조를 이해하는데 어려움을 겪는 것처럼, 도메인 객체 모델이 복잡해지면 개별 구성요소 위주로 모델을 이해하게 되고 전반적인 구조나 큰 수준에서 도메인 간의 관계를 파악하기 어려워진다.
도메인 요소 관계 파악이 어렵다는 것은 코드 변경을 하고 확장하는 것이 어려워진다는 것이다. 세부적인 모델만 이해한 상태로는 코드를 수정하는 것이 꺼려지기 때문에 코드 변경을 최대한 회피하는 쪽으로 요구사항을 협의하게 된다.
복잡한 도메인을 이해하고 관리하기 쉬운 단위로 만들려면 상위 수준에서 모델을 조망할 수 있는 방법이 필요하다. 래그리거트는 관련된 객체를 하나의 군으로 묶어준다. 수많은 객체를 애그리거트로 묶어서 바라보면 상위 수준에서 도메인 모델 간의 관계를 파악할 수 있다.
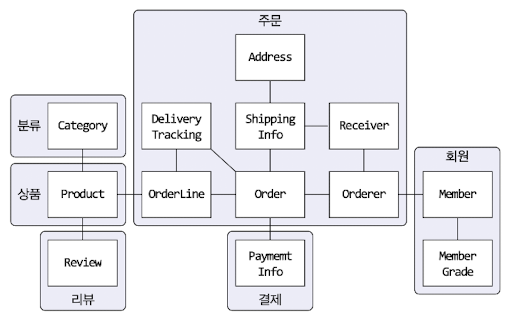
애그리거트는 모델을 이해하는데 도움을 줄 뿐만이 아니라 일관성을 관리하는 기준도 된다. 모델을 보다 잘 이해할 수 있고 애그리거트 단위로 일관성을 관리하기 때문에 애그리거트는 복잡한 도메인을 단순한 구조로 만들어준다. 복잡도가 낮아지는 만큼 도메인 기능을 확장하고 변경하는데 필요한 노력도 줄어든다.
애그리거트에 속한 객체는 유사하거나 동일한 라이프 사이클을 갖는다. 도메인 규칙에 따라 일부 객체를 만들 필요가 없는 경우도 있지만 애그리거트에 속한 구성요소는 대부분 함께 생성하고 함께 제거한다.
애그리거트는 경계를 갖는다. 한 애그리거트에 속한 객체는 다른 애그리거트에 속하지 않는다. 독립된 객체군이며 각 애그리거트는 자기 저신을 관리할 뿐 다른 애그리거트를 관리하지 않는다.
경계 설정
- 도메인 규칙과 요구사항을 따른다.
- 도메인 규칠에 따라 함께 생성되는 구성요소는 한 애그리거트에 속할 가능성이 높다. 함께 변경되는 빈도가 높은 객체는 한 애그리거트에 속할 가능성이 높다.
- "A가 B를 갖는다"로 해석할 수 있는 요구사항이 있다고 하더라고 이것이 반드시 A와 B가 한 애그리거트에 속한다는 것을 의미하는 것은 아니다.
- ex)
ProductEntity 와ReviewEntity는 상춤 상세 페이지에서 함께 볼 수 있지만,Product와Review는 함께 생성되지 않고, 함께 변경되지도 않는다. 또한Product를 변경하는 주체가 상품 담당자라면Review를 생성하고 변경하는 것은 고객이다.
3.2 애그리거트 루트
- 애그리거트는 여러 객체로 구성되기 때문에 한 객체만 상태가 정상이면 안 된다.
- 도메인 규칙을 지키려면 애그리거트에 속한 모든 객체가 정상 상태를 가져야한다.
- 모든 객체가 일관된 상태를 유지하기 위해 관리할 주체가 애그리거트 루트이다.
- 애그리거트에 속한 객체는 애그리거트 루트 엔티티에 직접 또는 간접적으로 속하게 된다.
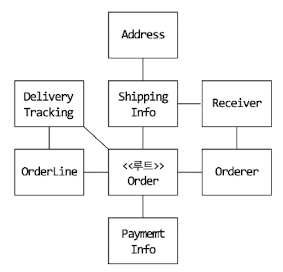
3.2.1 도메인 규칙과 일관성
- 애그리거트 루트가 단순히 래그리거트에 속한 객체를 포함하는 것으로 끝나는 것은 아니다.
- 핵심 역할은 애그리거트의 일관성이 깨지지 않도록 하는 것이다.
- 애그리거트 루트는 애그리거트가 제공해야 할 도메인 기능을 구현한다.
- 애그리거트 외부에서 애그리거트에 속한 객체를 직접 변경하면 안 된다.
var si = order.getShippingInfo()
si.setAddress(newAddress)위 코드는 도메인 규칙을 무시하고 직접 DB 테이블의 데이터를 수정하는 것과 같은 결과를 만든다. 논리적인 데이터 일관성이 깨지게 되는 것이다. 일관성을 지키기 위해 상태 확인 로직을 응용 서비스에 구현할 수도 있지만, 동일한 검사 로직을 여러 응용 서비스에서 중복으로 구현할 가능성이 높아져 유지 보수에 도움이 되지 않는다.
불필요한 중복을 피하고 애그리거트 루트를 통해서만 도메인 로직을 구현
- 단순히 필드를 변경하는 set 메서드를 공개 범위로 만들지 않는다.
- Value 타입은 불변으로 구현한다.
class Receiver(
private var name: String,
// ...
) {
// ...
fun setName(name: String) {
this.name = name
}
}공개 set 메서드는 도메인의 의미나 의도를 표현하지 못하고 도메인 로직을 도메인 객체가 아닌 응용 영역이나 표현 영역으로 분산시킨다. 도메인 로직이 한 곳에 응집되지 않으므로 코드를 유지 보수할 때에도 분석하고 수정하는 데 더 많은 시간이 필요하다.
공개 set 메서드를 만들지 안흔 것의 연장으로 Value는 불변 타입으로 구현한다. Value 객체의 값을 변경할 수 없으면 애그리거트 루트에서 Value 객체를 구해도 애그리거트 외부에서 Value 객체의 상태를 변경할 수 없다.
애그리거트 외부에서 내부 상태를 함부로 바꾸지 못하므로 애그리거트의 일관성이 깨질 가능성이 줄어든다.
Value 객체가 불변이면 Value 객체의 값을 변경하는 방법은 새로운 Value 객체를 할당하는 것뿐이다.
class Order(
private val orderNumber: String,
private var state: OrderState,
private var orderLines: MutableList<OrderLine>,
private var totalAmounts: Money,
private var shippingInfo: ShippingInfo,
) {
private fun setShippingInfo(newShippingInfo: ShippingInfo) {
this.shippingInfo = newShippingInfo
}
}3.2.2 애그리거트 루트의 기능 구현
애그리거트 루트는 애그리거트 내부의 다른 객체를 조합해서 기능을 완성한다.
private fun calculateTotalAmounts() {
val sum = orderLines.stream()
.mapToInt {value -> value.getAmounts() * value.getAmounts()}
.sum()
this.totalAmounts = Money(sum)
}위 코드처럼 애그리거트 루트가 구성요소의 상태만 참조하는 것은 아니다. 기능 실행을 위임하기도 한다.
class OrderLine(
// ...
private var lines: List<OrderLine>
) {
// ...
fun changeOrderLines(newLines: List<OrderLine>) {
this.lines = newLines
}
}위 코드처럼 상태 변경을 위임하는 방식으로 기능을 구현한다. 애그리거트 외부에서 상태를 변경할 수 없도록 Value를 불변으로 만드는 것으로 구현을 한다. 그렇지 않으면 버그가 발생될 경우가 많다.
불변으로 구현할 수 없다면 변경 기능을 패키지나 protected 범위로 한정해서 외부에서 실행할 수 없도록 제한하는 방법이 있다. 보통 한 애그리거트에 속하는 모델은 한 패키지에 속하기 때문에 패키지나 protected 범위를 사용하면 애그리거트 외부에서 상태 변경 기능을 실행하는 것을 방지할 수 있다.
3.2.3 트랜잭션 범위
- 트랜잭션 범위는 작을수록 좋다.
- 한 번에 많은 테이블을 수정을 하면 잠금 대상이 많아진다. 그만큼 동시에 처리할 수 있는 트랜잭션 개수가 줄어든다는 것을 의미하고 전체적인 성능을 떨어뜨린다.
- 동일하게 한 트랜잭션에서는 한개의 애그리거트만 수정해야 한다. 두 개 이상의 애그리거트를 수정하면 트랜잭션 충돌이 발생할 가능성이 더 높아지기 대문에 한 번에 수정하는 애그리거트 개수가 많아질수록 전체 처리량이 떨어지게 된다.
주의점
- 한 트랜잭션은 하나의 애그리거트만 변경해야된다. 한 트랜잭션에서 다른 애그리거트를 변경한다면 애그리거트가 자신의 책임 범위를 넘어 다른 애그리거트의 상태까지 관리하는 꼴이 된다.
- 애그리거트는 독립적이여야되는데 다른 애그리거트의 기능에 의존하기 시작하면 애그리거트 간 결합도가 높아진다. 결합도가 높아지면 높아질수록 향후 수정 비용이 증가한다.
3.3 레포지터리와 애그리거트
- 애그리거트는 개념상 완전한 한 개의 도메인 모델을 표현하므로 객체의 영속성으 ㄹ처리하는 레포지터리는 애그리거트 단위로 존재한다.
Order와OrderLine을 물리적으로 별도의 DB 테이블에 저장한다고 해서Order와OrderLine을 위한 리포지터리를 각각 만들지 않는다.
새로운 애그리거트를 만들면 저장소에 애그리거트를 영속화하고 애그리거트를 사용하려면 저장소에서 애그리거트를 읽어야 하므로, 레포지터리는 save와 findById 두 메서드를 기본으로 제공한다.
애그리거트는 개념적으로 하나이므로 레포지터리는 애그리거트 전체를 저장소에 영속화해야한다.
// 레포지터리에 애그리거트를 저장하면 애그리거트 전체를 영속화해야 한다.
orderRepository.save(order)val order = orderRepository.findById(orderId)
// order가 온전한 애그리거트가 아니면 기능 실행 도중 NullPointerException과 같은 문제가 발생한다.
oreder.cancel()RDBMS를 이용해서 레포지터리를 구현하면 트랜잭션을 이용해서 래그리거트의 변경이 저장소에 반영되는 것을 보장할 수 있다.
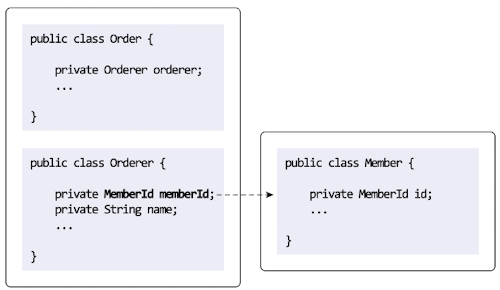
3.4 ID를 이용한 애그리거트 참조
- 한 객체가 다른 객체를 참조하는 것처럼 애그리거트도 다른 애그리거트를 참조한다.
애그리거트 관리 주체는 애그리거트 루트이므로 애그리거트에서 다른 애그리거트를 참조한다는 것은 다른 애그리거트의 루트를 참조한다는 것과 같다.
애그리거트간 참조는 필드를 통해 쉼게 구현할 수 있다.
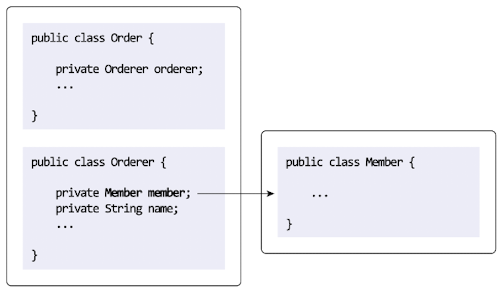
필드를 이용해서 다른 애그리거트를 직접 참조하는 것은 개발자에게 구현의 편리함을 제공한다. JPA에서 @ManyToOne, @OneToOne과 같은 애너테이션을 이용해서 연관된 객체를 로딩하는 기능을 제공하고 있으므로 필드를 이용해 다른 애그리거트를 쉽게 참조할 수 있다.
order.getOrder().getMember().getId()주의할 점
- 편한 탐색 오용
- 한 애그리거트 내부에서 다른 애그리거트 객체에 접근할 수 있으면 다른 애그리거트의 상태를 쉽게 변경할 수 있게 된다.- 트랜잭션 범위에서 언급한 것처럼 한 애그리거트가 관리하는 범위는 자기 자신으로 한정해야 한다.
- 애그리거트 간의 의존 결합도를 높여서 애그리거트의 변경이 어려워진다.
- 성능에 대한 고민
- 애그리거트의 상태를 변경하는 기능을 실행하는 경우에는 불필요한 객체를 함께 로딩할 필요가 없으므로 지연 로딩이 유리할 수 있다. - 확장 어려움
- 사용자가 늘고 트래픽이 증가하면 자연스럽게 부하를 분산하기 위해 하위 도메인별로 시스템을 분리하기 시작한다.
해결 방법
- ID를 이용해서 다른 애그리거트를 참조한다면 외래키로 참조하는 것과 비슷하게 사용할 수 있다.
- 모든 객체가 참조로 연결되지 않고 한 애그리거트의 속한 객체들만 참조로 연결된다. -> 물리적인 연결을 제거하기 때문에 모델의 복잡도를 낮춘다. 애그리거트간 의존을 제거하므로 응집도를 높여준다.
- 구현 복잡도가 낮아진다. -> 참조하는 애그리거트가 필요하면 응용 서비스에서 ID를 이용해서 로딩하면 된다.
3.4.1 ID를 이용한 참조와 조회 성능
- ID로 참조하면 참조하는 여러 애그리거트를 읽을 때 조회 속도가 문제 될 수 있다.
- 조인을 이용해서 한 번에 모든 데이터를 가져올 수 있음에도 불구하고 주문마다 상품 정보를 읽어오는 쿼리를 실행하게 된다.
orders.stream()
.map { order -> {
var prodId = order.getOrderLines().get(0).getProdcutID()
// 각 주문마다 첫 번째 주문 상품 정보 로딩 위한 쿼리 실행
var product = productRepository.findById(prodId)
return OrderView(order, member, product)
} }
.collect(Collection::toList)위 코드는 조회 대상이 N개일 때 N개를 읽어오는 한 번의 쿼리와 연관된 데이터를 읽어오는 쿼리를 N번 실핸하는 N+1 조회 문제가 발생한다.
N+1 조회 문제는 더 많은 쿼리를 실행하기 떄문에 전체 조회 속도가 느려지는 원인이 된다. 이 문제가 발생하지 않도록 하려면 조인을 사용해야 된다. 하지만 즉시 로딩을 사용하도록 매핑 설정을 바꾸는 것이 객체 참조 방식으로 다시 되돌리는 것이므로 추천하진 않는다.
ID 참조 방식을 사용하면서 N+1 조회와 같은 문제가 발생하지 않도록 하려면 조회 전용 쿼리를 사용하면 된다. 조회를 위한 별도 DAO를 만들고 DAO의 조회 메서드에서 조인을 이용해 한 번의 쿼리로 필요한 데이터를 로딩하면 된다.
해결 방법
- 애그리거트마다 다른 조회 전용 저장소를 구성한다.
- 코드가 복잡해지는 단점은 있지만 시스템의 처리량을 높일 수 있다는 장점이 있다.
3.5 애그리거트 간 집합 연관
- 애그리거트 간 1-N과 M-N 연관에 대해 살펴본다. 컬렉션을 이용한 연관이다.
1-N, N-1
개념적으로 존재하는 애그리거트 간의 1-N연관을 실제 구혀에 반영하는 것이 요구사항을 충족하는 것과는 상관없을 때가 있다. 개념적으로는 애그리거트 간에 1-N 연관이 있더라도 실행 속도가 급격히 느려지는 성능 문제 때문에 애그리거트 간의 1-N 연관을 실제 구현에 반영하지 않는다.
해결 방법
- 1-N이 아니라 N-1로 연관지어 구하면 된다. ex)
Product에Category로의 연관을 추가하고 그 연관을 이용해서 특정Category에 속한Product목록을 구한다.
카테고리에 속한 상품 목록을 제공하는 응용 서비스는 ProductRepository를 이용해서 categoryId가 지정한 카테고리 식별자인 Product 목록을 구한다.
M-N
- 개념적으로 양쪽 애그리거트에 컬렉션으로 연관을 만든다.
개념적으로는 상품과 카테고리의 양방향 M-N 연관이 존재하지만 실제 구현에서는 상품에서 카테고리로의 단방향 M-N 연관만 적용하면 되는 것이다.

@Entity
@Table(name = "product")
class Product(
private val id: ProductId,
) {
@Embedded
var id: ProductId = id
private set
@ElementCollection
@CollectionTable(name = "proudct_category", joinColumns = @JoinColumn(name = "product_id"))
var categoryIds: Set<CategoryId>
private set
}3.6 애그리거트를 팩토리로 사용하기
- user가 특정 상점에서 여러 차례 신고해서 해당 상점이 더 이상 물건을 등록하지 못하도록 차단한 상태이다.
상품 등록을 위한 응용 서비스 로직이다.
class RegisterProductService {
fun registerNewProduct(req: NewProductRequest) {
val store = storeRepository.findById(req.storeId)
checkNull(store)
if (store.isBlocked()) {
throw StoreBlockedException()
}
val id = productRepository.nextId()
val product = Product(id, store.id)
productRepository.save(product)
return id
}
}위 코드는 상품 생성이 가능한 지 판단할 수 있는 코드가 분리되어 있어 나빠 보이지는 않지만 중요한 도메인 로직 처리가 응용 서비스에 노출되어 있다. Store가 Product를 생성할 수 있는지를 판단하고 Product를 생성하는 것은 논리적으로 하나의 도메인 기능인데 이 도메인 기능을 응용 서비스에서 구현하고 있는 것이다.
Product를 생성하는 로직을 Store 애그리거트에 구현할 수도 있다.
class Store {
fun createProduct(newProductId: ProductId): Product {
if (isBlocked()) throw StoreBockedException()
return Product()
}
}Store 애그리거트의 createProduct()는 Product 애그리거트를 생성하는 팩토리 역할을 한다. 팩토리 역할을 하면서도 중요한 도메인 로직을 구현하고 있다.
class RegisterProductService {
fun registerNewProduct(req: NewProductRequest) {
val store = storeRepository.findById(req.storeId)
checkNull(store)
val id = productRepository.nextId()
val product = store.createProduct(id, store.id)
productRepository.save(product)
return id
}
}위처럼 응용 서비스에서 팩토리 기능을 이용해 Product를 생성할 수 있다.
방법
- 도메인 로직이 응용 서비스 입장에서 보여지지 않게 한다.
- 집합 연관이 있는 애그리거트를 생성할 때 한 애그리거트가 많은 정보를 알아야 한다면 다른 애그리거트를 직접 생성하지 않고 다른 팩토리에 위임하는 방법
팩토리를 사용했을 때의 장점
Product생성 가능 여부를 확인하는 도메인 로직을 변경해도 도메인 영역의Store만 변경하면 되고 응용 서비스는 영향을 받지 않는다.- 도메인의 응집도도 높아졌다.
- 다른 팩토리에 위임하더라도 도메인 로직은 한 곳에 계속 위치한다.
활용 시점
- 애그리거트가 갖고 있는 데이터를 이용해서 다른 애그리거트를 생성해야 할 때
