AMLCDR: An Adaptive Meta-Learning Model for Cross-Domain Recommendation by Aligning Preference Distributions
Cross Domain Recommendation
Fanqi Meng and Zhiyuan Zhang
WSDM (2025)
Abstract
- Data sparsity를 해결하기 위해 source domain의 overlapping user interaction을 target domain으로 전송하는 방식을 사용
- 대부분의 기존의 방식은 preference transfer network를 설계하여 user preference information을 전달
→ source / target domain간의 고유한 data distribution difference를 무시 - 그 결과, mapped user embedding은 target domain의 item embedding과 align 되어 있지 않음 → 추천 품질의 하락
- 저자는 Adaptive Meta-Learning CDR (AMLCDR)을 제안
- meta learning network: user 특징 추출 및 user preference loss
- domain adaptation network: user preference와 target domain과 align
1. Introduction
- 추천 시스템의 목적은 사용자에게 이전의 행동과 선호도를 기반으로 유사한 정보 또는 제품을 제공하는 것
- 하지만 real world에서는 user interaction이 적어 interaction matrix가 sparse하여 그들의 특징이나 선호도를 제대로 계산할 수 없음
- Data Sparsity는 추천 시스템의 bottleneck임
Data sparsity
- CDR이 data sparsity를 해소시킬 수 있음
- core task는 유사한 두 도메인 간의 user preference mapping이며, 이는 target domain의 data sparsity를 해결하며, 추천 퀄리티를 향상시킬 수 있음
- CDR 역시 heterogeneity, mismatch, 도메인 간 imbalance와 같은 challenge가 존재
- 이러한 challenge를 해결하기 위해 meta-learning을 CDR에 도입
Unaligned Data Distribution
- source domain에서 target domain으로의 direct transfer를 하기 위해서는 independent and identically distributed data (iid) 를 만족시켜야함
→ real-world application에서는 도메인별 data distribution이 다르기 때문에 (domain shift) direct transfer할 경우 negative transfer가 발생 - adversarial learning으로 source domain과 target domain간의 domain shift를 줄여 공통된 특성을 추출하면 됨 (domain adaptive)
- DARec: domain adaptive recommendation model
DNN을 통해 shared representation을 추출 - RecSys-DAN: domain invariant feature를 학습하기 위해 adversarial loss를 사용
- DARec: domain adaptive recommendation model
- adversarial learning의 branch인 domain adaptation은 domain shift를 줄여줌을 입증
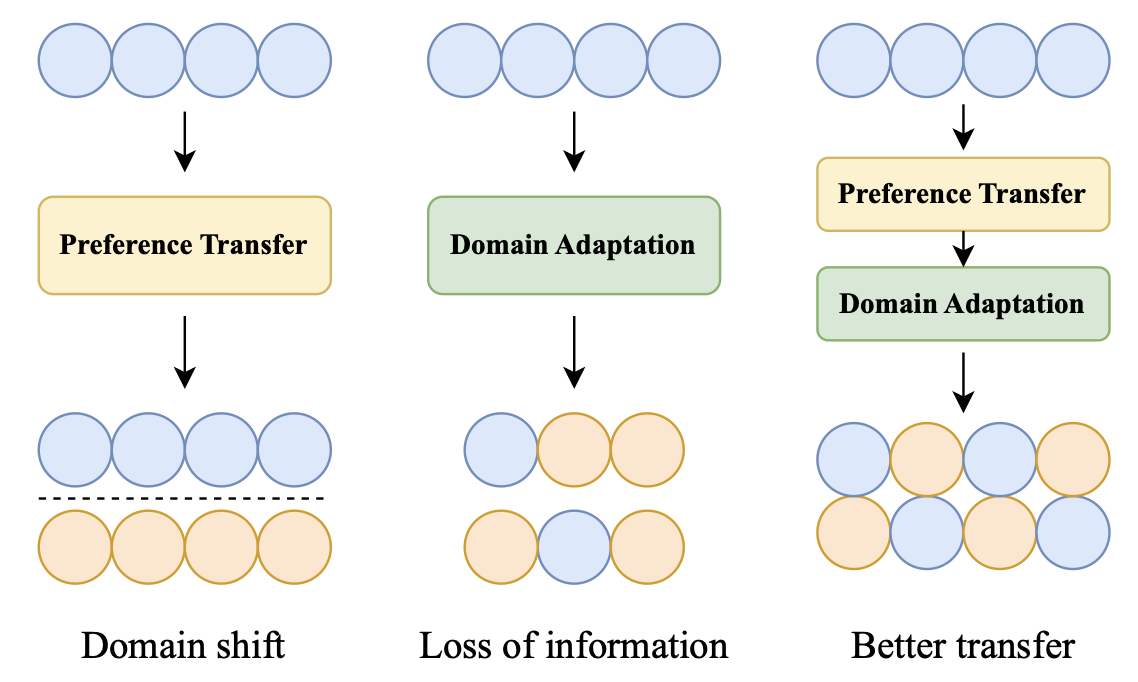
- Preference Transfer: direct transfer를 진행 후, domain shift가 남아있음
- Domain Adaptation: adversarial learning으로 domain shift가 줄었지만, domain feature가 덜 반영되어있음
- Preference Transfer + Domain Adaptation: domain feature를 잘 반영하면서도 domain shift가 줄어들어 추천 향상
- AMLCDR은 두 가지로 나뉨
- User preference transfer network based on meta-learning
- Data distribution based on domain adaptation
2. Related Work
2.1 Cross-domain Recommendation
- Transfer learning은 보조 분야에서의 지식을 활용하여 target domain이 필요로 하는 정보의 양을 줄이는 방법
- CDR model은 transfer learning을 활용하여 source domain으로부터의 정보를 target domain으로 전이
- EMCDR: user, item representation을 학습한 후, network를 통해 도메인간 연결 후 representation transfer
- DDTCDR: 서로 다른 latent space의 user간의 interaction을 연결하여 user preference를 capture
- CLCDR: contrastive learning을 통해 overlapping user, interaction에서 knowledge를 활용하여 user, item representation을 향상
2.2 Domain Adaptation
- Transfer learning의 branch로서, 도메인간 유용한 정보를 전이 및 학습을 목표로 함
- adversarial learning을 통해 도메인간 data distribution을 최소화하여 domain-invariant feature를 추출
- DSN: common network를 통해 도메인을 separate
- 이전의 domain adaptation은 주로 NLP, CV에 적용
→ 최근 RecSys 특히, CDR에 적용을 연구하는 중
- DARec: autoencoder 기반 domain adaptation CDR
- modified DANN: domain-adaptive network를 활용하여 rating matrix로부터 user feature 전이
- AFT: adversarial learning으로
generator: 모든 도메인에서 사용자의 관심있는 추천 후보군을 생성
discriminator: 실제로 관심을 가졌던 아이템인지 구별
- STAR: domain-shared network, domain-specific network를 통해 multi domain adaptation을 진행 - 소개한 방법들은 network와 parameter를 optimizing하는 데 집중하고 있음
2.3 Meta-Learning
- 학습하는 방법을 학습하는 것
- 여러 학습 에피소드를 통해 학습 알고리즘을 개선
- 세 가지 methods
- parameter based: task에 최적화된 parameter를 생성하여 학습 없이 바로 task에 적용가능
- gradient based
- metric-based
- AMLCDR은 parameter based meta-learning을 채택, meta-learning layer를 활용하여 preference transfer layer의 parameter를 생성
→ 동적으로 생성
- TMCDR: BPFMF로 학습된 representation을 meta-learning layer를 통해 preference mapping function을 학습
- PTUPCDR: 사용자별 특성 임베딩을 input으로 받는 meta network를 통해 user personalized bridge를 생성 - meta-learning은 user feature mapping network를 더 잘 생성한다.
3. Methodology
3.1 Problem Formulation
- Source domain
- Target domain
- Overlapped user
- Embedding layer
- K: number of dimensions
- embedding은 dense vector
- sequence of interaction items
- t: Timestamp
3.2 Overall Framework
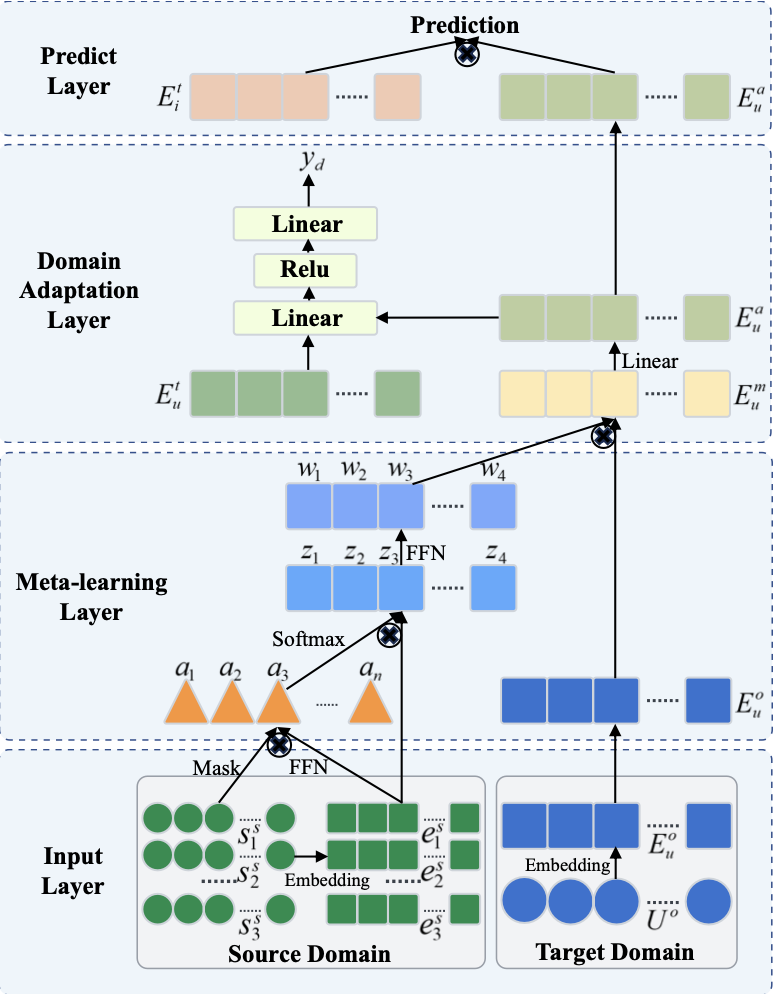
- Input layer
- user와 item은 임베딩으로 변환됨
- Meta-learning layer
-
input embedding으로 preference transfer의 parameter를 생성, target domain에 대한 user embedding을 출력
소스도메인 사용자 임베딩을 바탕으로 이 사람이 타겟 도메인에서는 어떤 임베딩을 가질 것인가? (task) 를 담당
-
- Domain adaptation layer
- meta-learning을 통해 출력된 user embedding과 기존 user embedding을 align
- Prediction layer
- aligned target domain user embedding과 target domain item embedding과의 prediction score 계산
3.3 Meta-Learning: reduce user preference loss
- Meta-learning network는 source domain에서의 user interaction을 기반으로 latent preference feature를 학습 후, target domain에 매핑한다.
- parameter generator+ preference transfer layer를 포함
- parameter generator
-
상호작용했던 아이템으로부터 사용자의 전송할만한 특징을 뽑아냄
예를 들어, 영화 도메인에서 사용자가 특정 배우가 나오는 영화를 많이 봤다면 사용자가 특정 배우를 선호한다는 특징은 전송할만함
-
Interaction sequence 를 활용하여 transferable feature를 찾음
-
interaction sequence내의 아이템들중 distinct impact를 가지는 component를 찾기 위해 attention mechanism을 사용
-
: 사용자 j의 preference embedding
-
: attention score
수식(1)만보면 단순 아이템 임베딩에 어텐션 스코어를 곱하여 합산한 것이다. 이게 왜 선호도 임베딩을 의미하는지 의아했지만,
사용자가 상호작용한 아이템 임베딩에서 어텐션 스코어를 곱하여 합산한 것은 의미적으로 사용자가 대표적으로 어떤 아이템들과 상호작용했는가를 뜻하기 때문에 사용자의 선호도를 나타낸다라고 말할 수 있을 거 같다.
-
-
Attention layer
- Attention layer: 2-layer Feed Forward Network
-
source domain에서의 user preference를 target domain으로 mapping하는 function을 만들기 위해 parameter generator를 설계
- : parameter generator, double layer feed forward network
- : 특정 사용자의 선호도를 반영하는 parameter, size는 preference mapping function마다 다름
-
Preference mapping function, target domain으로 선호도 매핑
- 각 user preference를 최적화한 parameter를 통해 target domain으로의 preference mapping이 이뤄짐
- 본 논문에서는 을 단순히 linear layer로 사용
-
Transferred user embedding
-
overlapped user embedding을 target domain으로 mapping하여 얻은 transferred user embedding
meta-learning section을 읽으며 내가 이해한 과정은 다음과 같다.
- 먼저 전체적인 목적은 source domain에 있는 specific user i의 preference를 활용해서 target domain에서의 source domain-specific user i의 preference 예측.
- 1번을 행하기 위해서는 먼저 source domain에서 user i와 interaction한 item embedding을 가져옴. 이게 interaction sequence
- 그 후 attention mechanism을 적용시켜 user i의 source domain에서의 전체적인 선호도를 가져옴. 이게 수식 1번
- 그 후, meta-layer에서 source domain에서의 user i의 preference 정보를 담고 있는 parameter를 추출. 이게 수식 4번
하지만 이때, 학습이 되는건 . 이를 통해 어떤 user preference가 들어와도 해당 preference를 잘 담고 있는 parameter를 생성할 수 있음
- 그 다음 user i의 preference parameter를 preference mapping function에 넣어 user i가 target domain에서 어떤 preference를 가지고 있는지 예측해.
수식 6번에 는 overlapped user라고 논문에서 언급하는데, source domain의 preference를 이용해서 target domain에서의 preference를 예측하는 task를 위해 meta-learning을 사용했다고 생각한다. 그러나 overlapped user embedding에 source domain preference parameter를 적용시켜 target domain preference로 조정하는 것이라면, specific user의 경우에는 mapping function에 들어갈 수 있는지가 궁금함.
만약 specific user embedding이 들어갈 수 없다면 학습과정에서는 overlapped user만이 모델 학습에 사용되는 것인지 궁금함
-
-
- parameter generator
3.4 Domain Adaptation: align user preference distributions
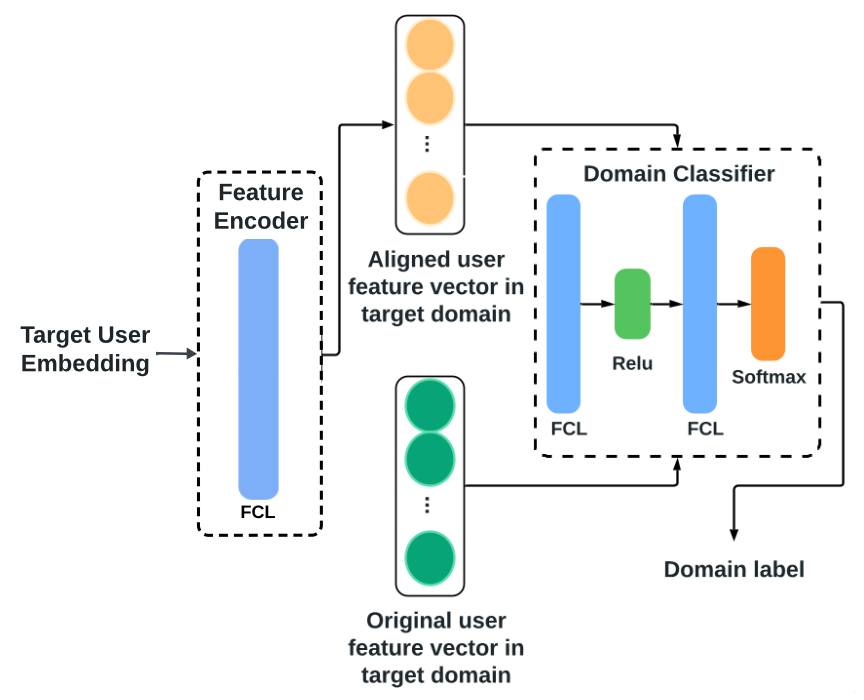
- DAN(Domain Adaptation Network) module은 2 parts로 구성
(Feature Encoder, Domain Classifier) - Feature Encoder(E)
- source domain user latent vector 을 input으로 받아 transformed feature space로 mapping
→ target domain distribution으로 align 진행$$ \hat e_{u_j}^a = E(e_{u_j}^m;\theta_E) \ \ \ \ \ \ (7) $$
- source domain user latent vector 을 input으로 받아 transformed feature space로 mapping
- Domain Classifier(D)
- aligned embedding 가 target domain data distribution에 일치하는지 검사
domain discrepancy를 최소화$$ y_d = D(e_{u_j}^a; \theta_D) \ \ \ \ \ \ (8) $$ - $y_d$: Domain label (s or d)
- aligned embedding 가 target domain data distribution에 일치하는지 검사
- DAN loss function
- Cross entropy
- align이 잘 되었나 검사 (adversarial learning)
- Final prediction score
- aligned target domain user embedding과 target domain item embedding의 score를 계산하여 rating을 출력
4. Experiments and Analysis
- RQ1: AMLCDR과 other baselines와의 비교
- RQ2: meta-learning, domain adaptation이 CDR에 기여하는가?
- RQ3: meta-learning, domain adaptation이 CDR에 어떻게 기여하는가?
- RQ4: AMLCDR이 practical, specific Rec scenario에서는 어떤가?
4.1 Datasets
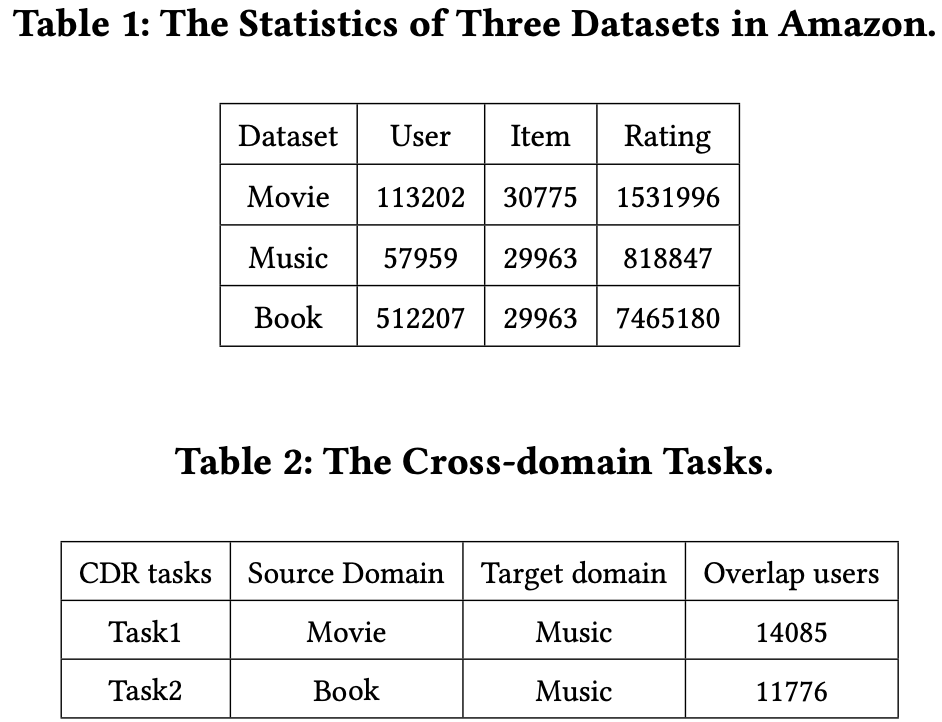
- Amazon review data
- Movie
- Music
- Book
- CDR Task
- 도메인간 관련성과 크기를 기반으로 2가지 CDR task를 설정
- Movie → Music
- Book → Music
- 10번 미만의 interaction user, item은 제거
- 도메인간 관련성과 크기를 기반으로 2가지 CDR task를 설정
4.2 Baseline Methods
- single-domain
- MF
- GMF
- YouTube DNN
- classic CDR
- CMF
- EMCDR
- recent SOTA CDR
- PTUPCDR
- CMVCDR
- TransFR
- ALCDR
4.3 Experimental Settings
Implementation Details
- Framework: PyTorch
- Optimizer: Adam
- Dimension of embedding: 10
- Batch Size: 512
- Meta-learning layer: Double-layer structure
- Output size of the meta-layer:
Experimental Procedure
- 일부 random selection Overlapped user를 test에 사용하기 위해서 학습 데이터에서 제거
→ 나머지 overlapped user는 모델 학습과정에 사용 - 실험은 cold-start scenario, warm-start scenario 두 가지 진행
- cold-start scenario
-
전체 overlapped user의 20%를 cold-start user로 사용,
-
20%의 overlapped user의 rating set은 전부 test dataset으로 사용
-
overlapped user는 8:2로 분리가 되지만, interaction item은 겹칠 수 있음
→ test set에서만 등장하는 item은 cold-start item이기 때문에 제거Cold-start scenario 정리
overlapped user는 8:2 (Train : Test)로 완벽하게 분리item
Overlapped item, Non-overlapped item → Train
Only overlapped item → Test
-
- warm-start scenario
- test set의 user interaction을 동일하게 2개의 set으로 분리
- cold-start scenario의 fine-tuning에 사용됨
- warm start scenario 평가에 사용
- test set의 user interaction을 동일하게 2개의 set으로 분리
- cold-start scenario
- 모델 평가는 세 가지 파트로 구분
- cold-start dataset을 모델이 학습
- cold-start 성능 평가
- warm-start fine tuning 후, warm-start 성능 평가
Evaluation Metrics
- 1000개의 candidates’ score (10 ground-truth, 990 negative items)를 predict
- Precision@10
- HR (Hit Ratio)@10
- MRR (Mean Reciprocal Rank)@10
- NDCG@10
4.4 Results and Analysis (RQ1)
Cold-start Experiments
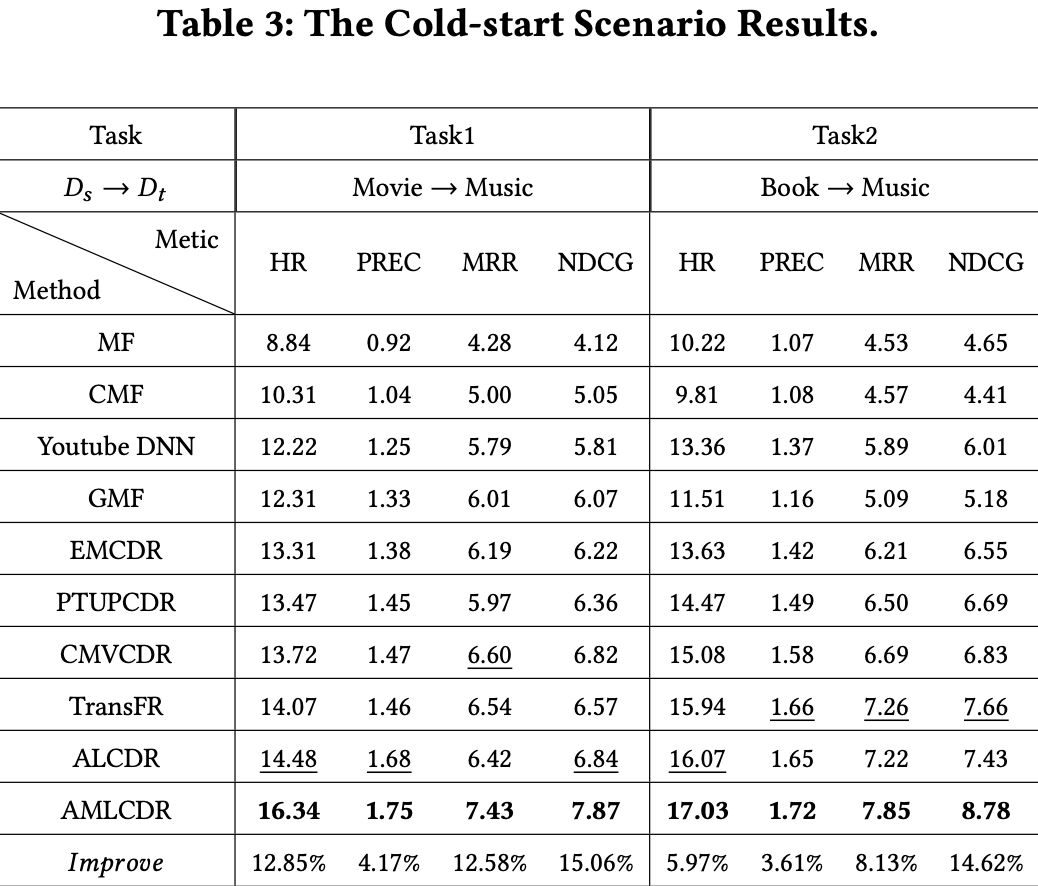
- Observation 1
- MF는 target domain에만 의존하는 single-domain method이기 때문에 성능이 낮음
- GMF, YouTubeDNN은 DNN을 사용해 data mining 능력을 강화시켜 더 나은 결과를 보여줌
→ non-linear network는 추천 성능을 향상시킴 - CDR baseline은 single-domain을 능가
- Observation 2
- CMF는 여러 도메인의 정보를 가져와 하나로 통합하지만 CDR baseline은 도메인간 연결을 함
→ CMF보다 CDR baseline이 더 성능이 좋음, domain shift 때문
- CMF는 여러 도메인의 정보를 가져와 하나로 통합하지만 CDR baseline은 도메인간 연결을 함
- Observation 3
- AMLCDR이 best performance를 달성
Warm-start Experiments
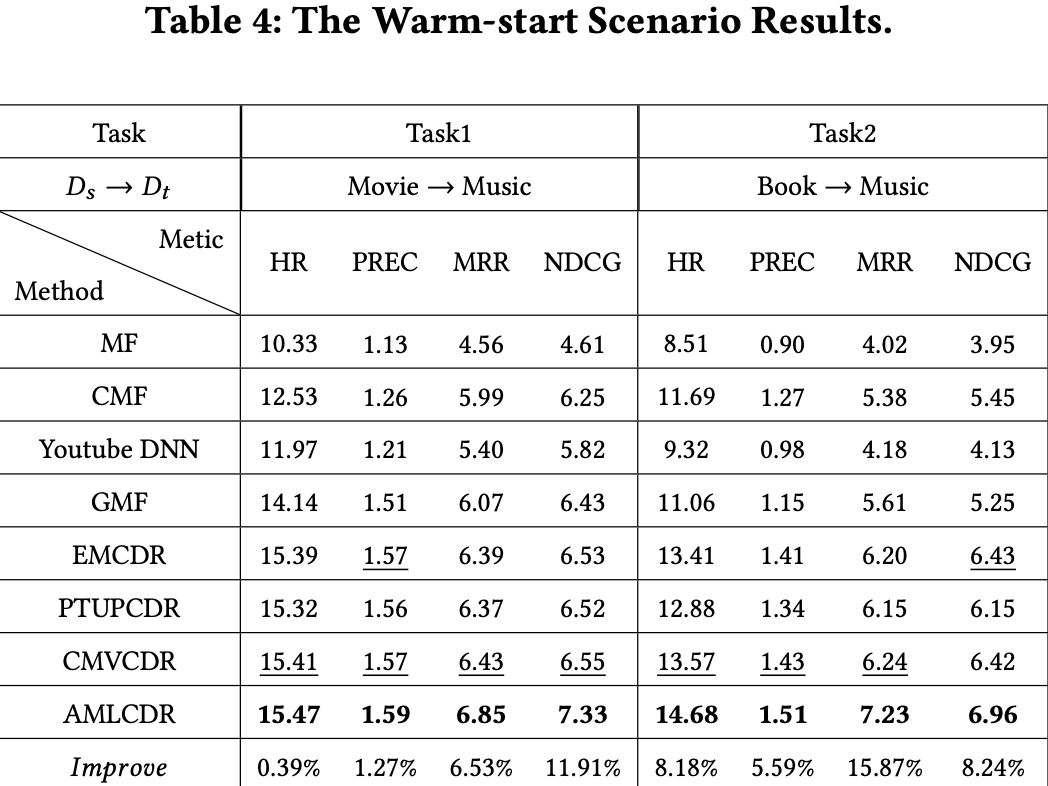
- AMLCDR은 bridge-based CDR임.
- 현재 bridge-based CDR은 cold-start에만 집중하고 있음
→ bridge-based method는 warm-start에서도 유리함,
초기 임베딩에 더 유의미한 정보를 반영시킨상태에서 시작할 수 있어서
- 현재 bridge-based CDR은 cold-start에만 집중하고 있음
- user interaction이 증가할수록 추천 성능도 증가하는 모습을 보임
- 대부분의 baseline들이 cold-start scenario보다 성능이 전체적으로 올라감
- AMLCDR이 warm-start scenario에서도 best performance를 달성
4.5 Ablation Study (RQ2)
- AMLCDR의 각종 모듈을 제거한 버전과 비교
-
AMLCDR
-
w/o ML (meta-learning) 사용자별 target domain preference를 만들지 않음
-
w/o PG (Parameter generator) 사용자별 선호도를 반영하고 있는 parameter를 만들지 않음
-
w/o DA (Domain Adaptation)
-
w/o ML&DA
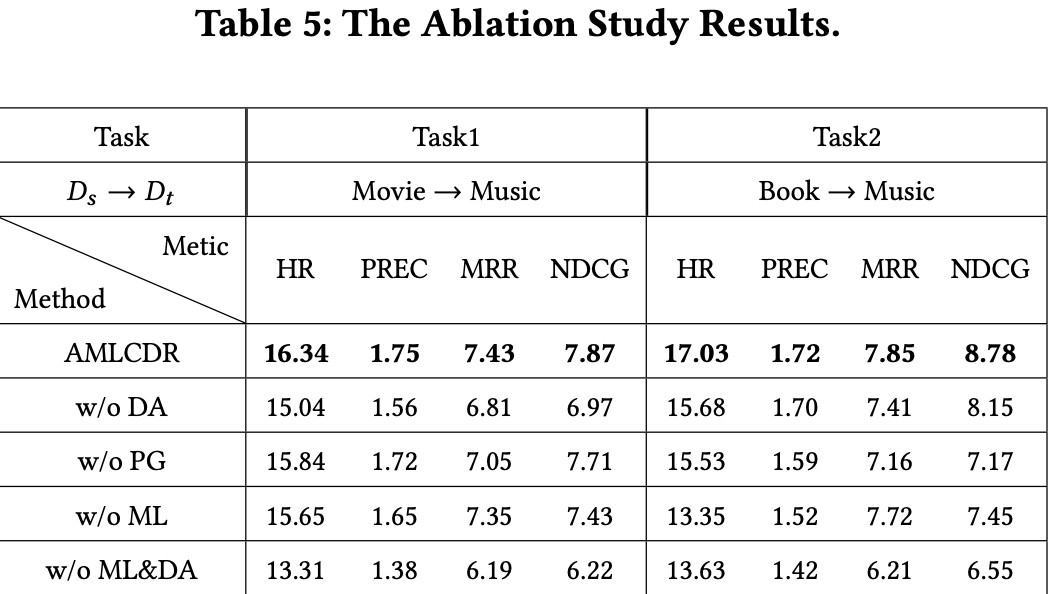
-
Task 1에서는 w/o ML보다 w/o DA가 성능이 더 크게 떨어짐
Task 2에서는 w/o DA보다 w/o ML이 성능이 더 크게 떨어짐 -
Domain Adaptation 제거했을 때 task별 성능 하락이 9.65%, 5.47%
→ Movie-Music, Book-Music에서의 user feature distribution이 다름⇒ alignment의 필요성을 강조 -
w/o ML - AMLCDR간의 성능차이가 4.15%, 12.51%
→ domain invariant preference가 전달되었기 때문임 -
w/o ML - w/o PG를 비교했을 때 parameter generator가 더 성능이 떨어짐
→ AMLCDR의 성능이 attention mechanism으로 사용자 대표 선호도를 만드는 것보다 meta-learning으로 task를 만드는 것으로부터 나옴
-
4.6 Analysis of domain data distribution (RQ3)
- Meta-learning, Domain adaptation이 어떻게 기여하는가?
- 시각화를 통해 domain adaptation이 잘 진행되었는지 확인
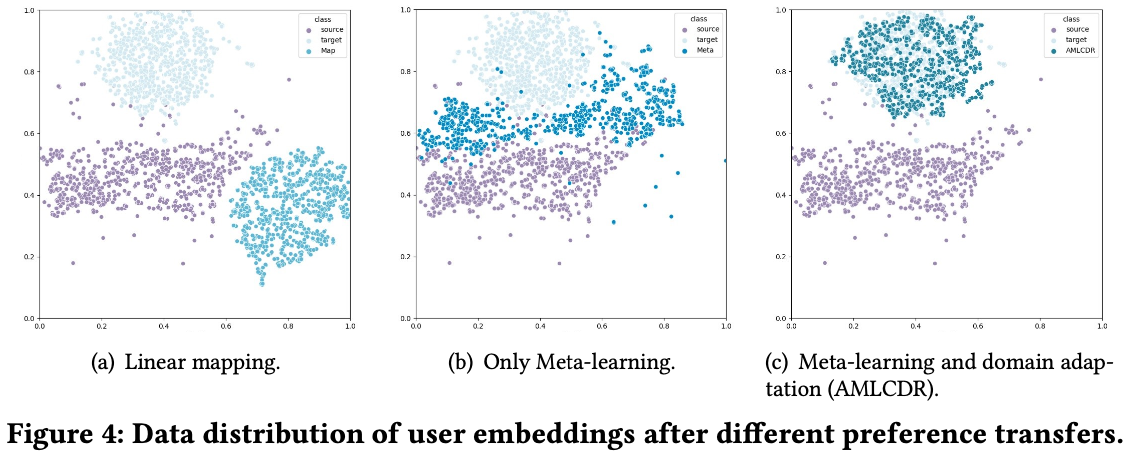
- Observation 1
- target domain distribution에 더 가깝게 조정이 됨
- Observation 2
- linear mapping은 다른 space로 mapping하고 있어 distribution을 control할 수 없음
- Observation 3
- meta-learning으로 source와 target에 더 가까이 할 수 있었지만 여전히 차이가 존재
domain adaptation을 통해 target domain으로 밀착시켜버림
- meta-learning으로 source와 target에 더 가까이 할 수 있었지만 여전히 차이가 존재
4.7 Case Study (RQ4)
- AMLCDR이 practical, specific Rec scenario에서는 어떤가?
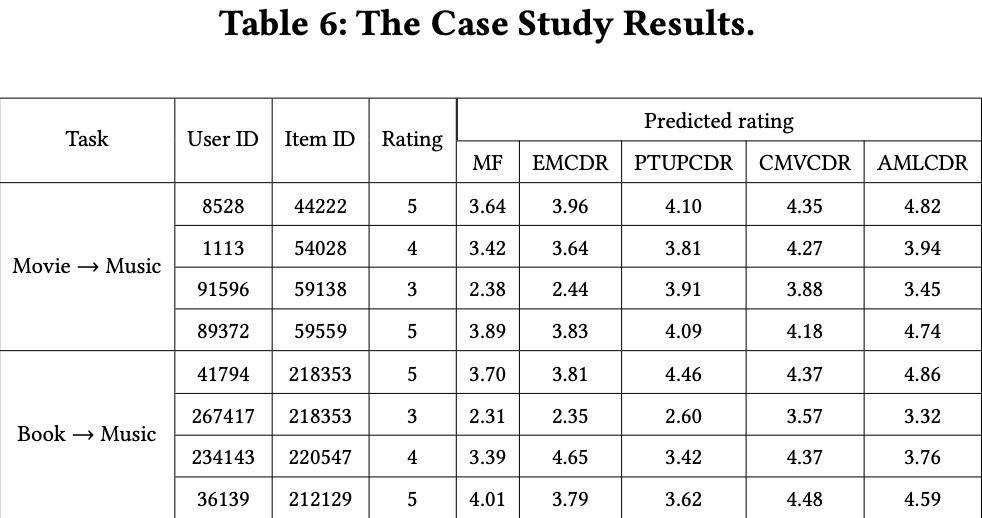
- predicted rating을 기반으로 사용자에게 아이템을 추천해주는 것이 목표
(3점 이상이면 해당 아이템을 선호하는 것으로 간주) - MF, EMCDR, PTUPCDR은 rating보다 더 낮은 predicted rating을 보임
→ 추천 성능이 좋지 않음 - CMVCDR과 AMLCDR은 rating보다 높은 predicted rating을 보여주지만 AMLCDR이 truth에 더 가까운 rating을 보임
- predicted rating을 기반으로 사용자에게 아이템을 추천해주는 것이 목표
5. Conclusion
- AMLCDR은 source domain에서 transferable information을 강화하는 모델임
- most previous CDR methods는 target domain data distribution과의 align에 실패하거나, preference information을 적절하게 전이하지 못함
- Adaptive Meta-Learning을 CDR에 적용시킴으로서 그 성능을 입증함
After meeting
모델 의아점
- 메타러닝에 대한 loss가 따로 있는지, end-end로 학습이 되는지, 메타러닝의 방향성에 어긋날 거 같아 한 번 더 체크
- My opinion
Meta-learning part에 대한 lose가 따로 있는지, DAN loss를 이용하여 end-end로 optimization이 이뤄지는가
해당 부분에 대한 결론부터 말씀드리자면, end-end가 아닌 meta-learning part에 대한 별도의 loss가 따로 존재한다는 게 나의 의견임
그 이유는 다음과 같음
- AMLCDR이 DAN loss만으로 optimize 된다면, 해당 loss function의 지칭을 DAN(Domain Adaptation Network) loss라고 하지 않았을 것임. 해당 loss를 통해서 모델의 전반적인 parameter들을 조정하게 된다면 해당 loss function의 지칭을 AML loss와 같은 전체 모델에 대한 loss로 정의해야 했을 것.
- DAN loss로 meta parameter를 optimization할 경우 meta-learning에 대한 의미가 축소됨. 현재 AMLCDR에서 meta learning을 차용하게 된 이유는 source domain의 user가 target domain에서는 어떤 preference를 보일까? 라는 task를 위함임. 하지만, DAN loss로 meta-learning을 조정하게 된다면 meta-learning을 하는 의의가 source domain과 target domain간의 구분을 어렵게 하는 임베딩 생성으로 축소되게 됨. 이는 초기 목적과 일치하지 않는 부분이라고 생각.
- Domain shift 부분이 어디서 반영이 되는지
- My opinion 해당 논문에서 소개된 Domain shift는 real-world에서 어쩔수없이 발생하게 되는 두 도메인간의 본질적인 차이를 의미. 따라서 domain shift를 극복하기 위한 Domain adaptation을 차용하여 모델에 녹여 해당 문제를 극복한 것으로 보임
