CATART: One for All, All for One: Learning and Transferring User Embeddings for Cross-Domain Recommendation
Cross Domain Recommendation
목록 보기
3/11
Chenglin Li at al
WSDM (2023)
ABSTRACT
- CDR이 single-domain, dual-domain target에만 집중
- negative transfer problem이 여전히 잔재
- multi-domain을 target으로 하는 CATART를 제안
- Contrastive AuToencoder (CAT)
- global user embedding을 생성
- Attention based Representation Transfer (ART)
- domain-specific user embedding을 target-domain으로 전송
- Global user embedding과 domain-specific user embedding 전송으로 MDR에 큰 향상을 이룸
- Contrastive AuToencoder (CAT)
1. INTRODUCTION
- 이전의 CDR scenario들은 single-target (STCDR), dual-target (DTCDR)에 집중하고 있음
- STCDR, DTCDR은 pair-wise domain-domain relationship을 모델링
- Multi-target CDR (MTCDR)이 좀 더 general하고 challenging problem임
- n개의 domain이 참여하기 때문에 STCDR, DTCDR의 방법을 확장시켜야함
- Current MTCDR SOTA solution은 각 유저에 대한 shared user representation을 생성하여 specific feature와 결합하여 사용함
- HeroGRAPH: 모든 도메인에서의 유저 행동을 하나의 heterogeneous graph로 만들어 GCN을 통해 user, item embedding을 생성하여 타겟 도메인으로 전송한다.
→ 대부분의 추천 시스템은 사용자의 민감한 정보가 이용되기 때문에 공유할 수 없다. - MPF: 각 유저마다 global embedding을 학습하여 도메인간 공유한다
→ global embedding은 상호작용이 많은 도메인의 정보를 더 많이 반영하기 때문에 bias가 있어 negative transfer problem으로 이어짐
- HeroGRAPH: 모든 도메인에서의 유저 행동을 하나의 heterogeneous graph로 만들어 GCN을 통해 user, item embedding을 생성하여 타겟 도메인으로 전송한다.
- 저자는 CDR에 도움이 되는 두 가지 유형의 user embedding을 관찰
- Global user embedding: 사용자의 전반적인 doamin-invariant 특성을 나타냄
- Domain-specific user embedding: 각 도메인에서의 사용자 행동을 모델링
- 이 두 임베딩에 관한 두 가지 Questions
- individual domain들로부터 얻어진 user embedding을 이용해서 global representation을 만들 수 있을까?
- 표현력이 풍부하고 bias가 없는 global user representation은 모든 도메인에서의 추천 향상이 있을 것이다
- First Goal: “One for All”, 모든 도메인에서의 추천을 위한 하나의 global user embedding
- 민감한 사용자 정보(로그)를 그대로 사용하는 것이 아닌 각 도메인에서 학습 된 domain-specific user embedding을 활용
- Negative transfer를 회피하는 domain-specific user embedding을 전송할 수 있을까?
- Prior MTCDR은 global embedding에만 치중하고 domain-specific을 효과적으로 전달하기 위한 방법은 생각하지 않았음
- domain-specific embedding을 효과적으로 전송하지 않으면 negative transfer problem이 발생
- Second Goal: “All for One”, All domain-specific embedding이 하나의 도메인에 도움이 되게하기
- individual domain들로부터 얻어진 user embedding을 이용해서 global representation을 만들 수 있을까?
- 저자들은 MTCDR, CATART를 제안
- CAT (Contrastive AuToencoder)
- Pre-trained domain-specific user embedding을 기반으로 Global user embedding을 학습
- Concatenated domain-specific user embedding (Input)을 reconstruction함으로서 global user embedding 학습
- Input sequence에 마스킹을 하여 원본과 대조학습을 진행
→ Robust representation만 추출
- ART (Attention-based Representation Transfer)
- pre-trained domain-specific user embedding을 활용하여 타겟 도메인으로 전송
- Attention mechanism을 사용하여 다른 domain-specific user embedding을 target-domain에 적용시킨다
- ART는 target-domain user embedding과 global user embedding, domain-specific user embedding을 combination하여 target domain에서의 추천을 개선
- Large dataset으로 실험 (5 domains)
- App-install
- App-use
- Article viewing
- short-video viewing
- long-video viewing
- CAT (Contrastive AuToencoder)
CAT, ART 모두 pre-trained domain-specific user embedding을 이용한다.
INTRODUCTION에는 해당 embedding이 어떻게 학습되는지 언급되지 않으므로 뒷부분에서 자세히 나올 거 같음
2. METHODOLOGY
- Global user set,
- Item set, domains
- User-Item interaction matrix,
- Data isolation scenario도 고려하기 때문에 특정 도메인에서의 user-item interaction information은 다른 도메인에서 알 수 없음, 즉 를 확인할 수 없음
→ 를 기반으로 학습이 된 domain-specific user embedding을 이용하자
2.1 Architecture Overview of CAT-ART
- MTCDR을 위한 두 가지 목적을 정의함
- One for All: global user embedding을 학습
- All for one: Negative transfer를 방지하며 domain-specific user embedding을 transfer
- 두 가지 목적과 raw data의 직접적인 사용을 막기 위해 CAT-ART를 제안
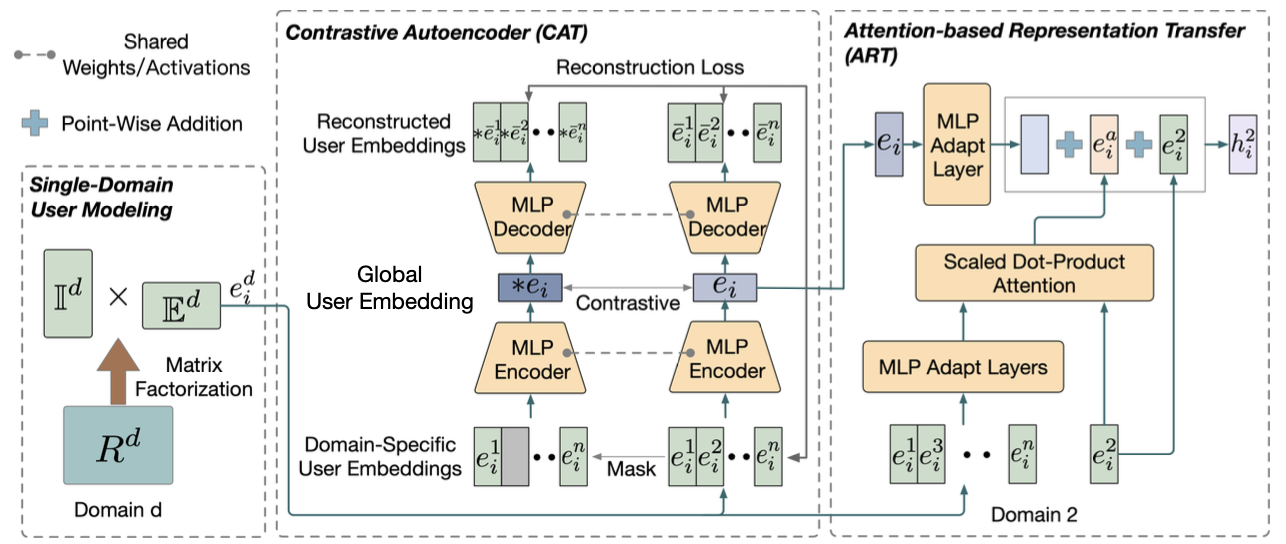
- 먼저 CAT, ART에서 input으로 사용되는 domain-specific user embedding은 BPRMF로 사전학습 시켰음
- CAT Module
- All domain의 pre-trained domain-specific user embedding을 하나로 모아 global user representation을 생성
- bias를 없애기 위해 reconstruction loss, contrastive loss를 결합해서 모델 학습에 사용
- ART Module
- target domain을 제외한 다른 모든 domain-specific user embedding을 target domain으로 transfer
- Attention mechanism을 적용하여 target domain에 유효한 embedding만 사용
- Negative transfer problem 해결
2.2 Domain-specific User Embedding
- BPRMF를 이용하여 user, item embedding을 얻음
- BPR loss를 최소화함으로서 domain-specific user embedding을 얻음
- 해당 임베딩만 사용하여 raw data isolation 제약을 준수
2.3 Contrastive Autoencoder
- Pre-trained domain-specific user embedding을 하나로 모아 CAT module에 input → Global user representation
- domain 1 ~ n 순서로 domain-specific user embedding을 real-valued dense vector로 만듬
- Encoder는 input embedding에서 latent user presentation을 추출
- 추출된 latent user presentation은 decoder로 들어가 input embedding을 reconstruction
- Encoder, Decoder로 MLP를 사용
- Input embedding과 reconstruction embedding 사이의 오차를 MSE로 최소화
- domain-specific user embedding은 해당 domain의 data quality와 sparsity에 영향을 받음
- Contrastive self-supervised learning을 통해 autoencoder가 좀 더 general하고 robust한 latent user representation을 학습
-
Input embedding에 Mask를 적용 -Encoder→ latent user representation
-
positive pair 를 Cosine similarity로 pair의 유사도 계산,
-
Contrastive Loss
- : Temperature Parameter
- 양방향으로 contrastive learning을 진행하여 안정적인 학습이 가능
- latent embedding space에 , 가 서로 가까워짐
- CAT을 통해 좀 더 general, robust user representation을 추출할 수 있음
-
는 다시 한 번 에 들어가 input embedding을 reconstruct
- 을 최소화하여 masked domain에 대한 reconstruction 능력이 충분한 latent representation을 얻을 수 있음
- 어떠한 도메인에 bias 되지 않는 global user representation을 추출할 수 있음
-
- CAT Loss
- : Hyper parameter
- Masking X reconstruction loss, Masking O reconstruction loss, Contrastive loss를 결합
- Masking O, X reconstruction loss: Global user representation이 본래의 domain-specific embedding으로 잘 이루어져 있는가?
- Contrastive loss: Masked latent user representation과 latent user representation이 동일한가?
2.4 Attention-base Representation Transfer
- Domain-specific user embedding은 specific-domain에서의 사용자 추천을 위한 유용한 feature이지만, 이를 바로 target domain으로 transfer할 경우, negative transfer problem이 발생할 수 있음
- 저자는 ART module을 고안
→ domain-specific user embedding 중 target domain에 유효한 것들만 가져옴 - target domain을 제외한 domain-specific user embedding을 MLP-based domain adaptation layer에 통과시켜 Query(Target domain-specific user embedding)와의 관계를 계산 (Attention)
- Target domain에 유용한 domain-specific embedding을 가져와서 사용 (Negative transfer problem 해결)
Final User Embedding
- domain adaptation module에 global user embedding을 통과시켜 target domain embedding, attention-based embedding과 결합하여 final user embedding을 얻음
- user preference score of the user to an item in domain
2.5 Model Training
- BPRMF를 이용하여 domain-specific user embedding 계산
- CAT module에서 contrastive loss, reconstruct loss를 이용해 global user embedding 생성
- ART module에서 attention이 적용된 domain-specific embedding과 target domain embedding, adaptation layer를 통과한 global user embedding을 결합하여 final user embedding 생성
3. EXPERIMENTS
3.1. Datasets
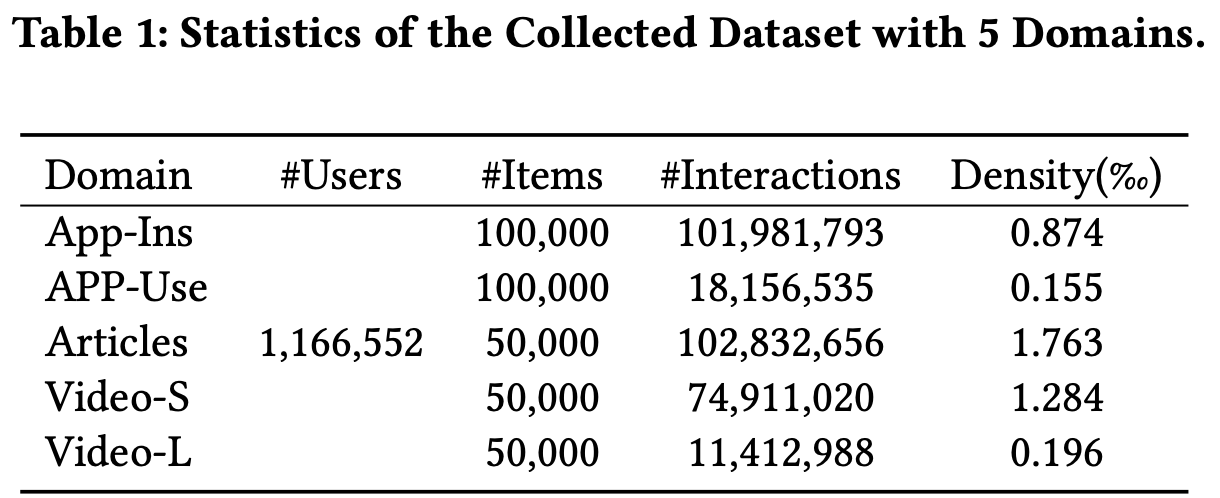
- Tencent App내의 5개의 도메인으로부터 user log를 dataset으로 사용
- ~ 8.20.
- App installation (APP-Ins)
- App usage preferences (APP-Use)
- ~ 8.
- Articles
- Short Video (Video-S)
- Long Video (Video-L)
- 5개 이상의 item tag와 상호작용한 사용자만 사용
3.2 Experimental Setup
- Research Question
- RQ1: CATART vs SOTA MTCDR Methods
- RQ2: Negative transfer를 잘 해결하였는가
- RQ3: CAT, ART module이 어떻게 도움이 되는가
- Train : Validation : Test = 7 : 1 : 2
- Evaluation Metrics
- Precision@K
- Recall@K
- NDCG@K
- Compared Methods
- single-domain : SMF
- Cross-domain: CMF, HeroGRAPH-L, MPF
- Multi-domain: GA-MTCDR
3.3 Model Implementation and Complexity
Environment
- Framework: PyTorch
- Hardware (모델 학습 환경)
- GPU: Tesla P40
- Memory 22.38 GiB, Memory Clock (1.53 GHz)
Proposed Method Implementation
- BPRMF (domain-specific user embedding)
- Embedding dimension: 64
- CAT Module
- Encoder: [5m, 3m, m]
- Decoder: [m, 3m, 5m]
- Activation Function: PReLU
- Minibatch Size: 4096
- (Temperature): 0.1
- 마스킹: 5개 도메인 중 1개 도메인을 randomly masking
- ART Module
- 각 도메인마다 단일 ART unit 존재
- single head attention
- Model Complexity
3.4 Experimental Results
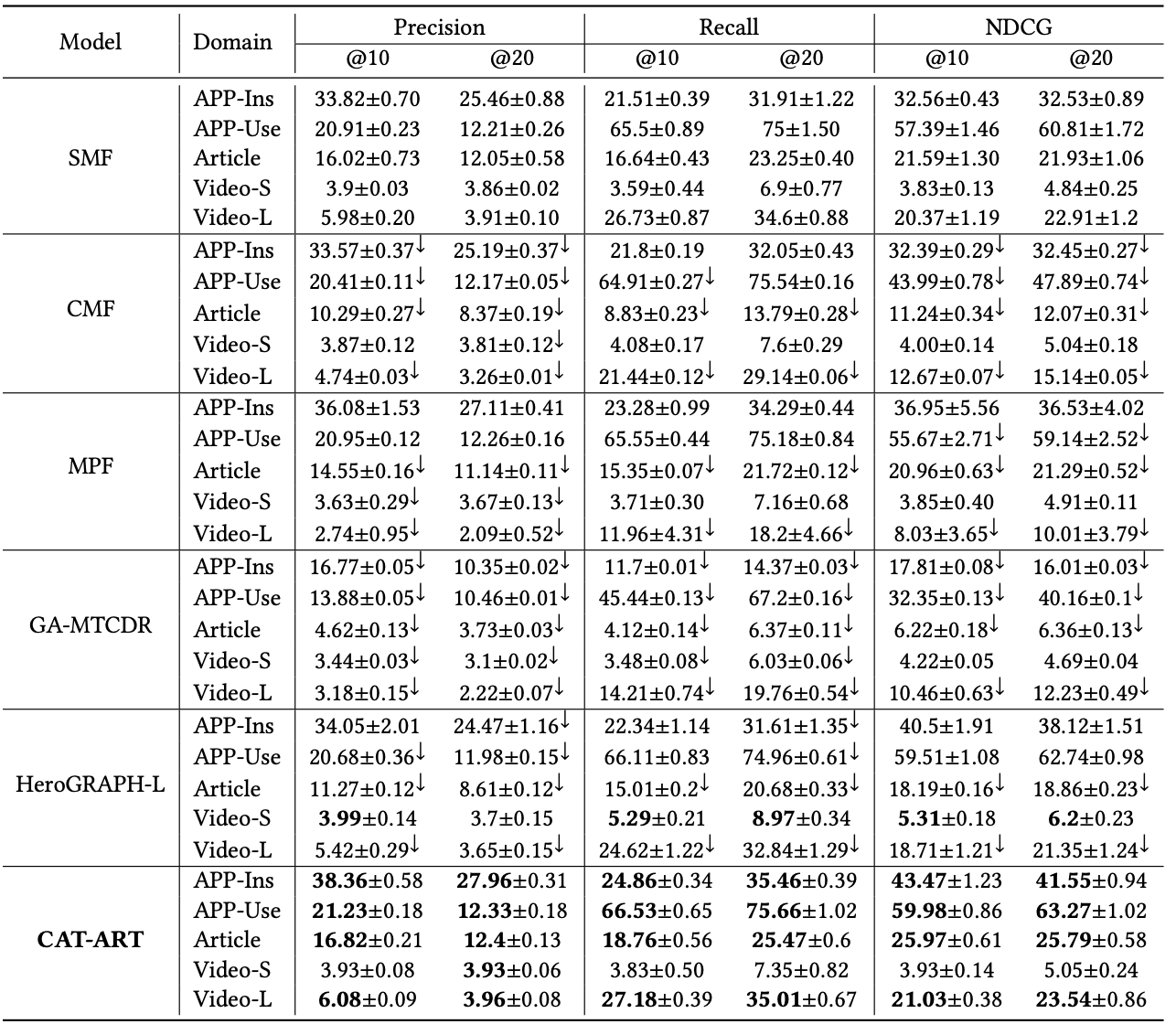
RQ1: CATART vs SOTA MTCDR Methods
- CATART가 5개의 도메인 중 4개의 도메인에서 best performance를 달성 (Video-S 제외)
- Video-S 도메인 내 user behavior가 더 풍부하기 때문에 다른 도메인의 영향을 덜 받음
- GCN기반의 HeroGRAPH-L이 MF 기반 모델보다 단일 도메인에서의 임베딩을 잘 생성함, 그래도 negative transfer 문제가 발생
3.5 Ablation Study and Analysis
RQ2: Negative transfer를 잘 해결하였는가
- more sparsity domain일수록 다른 domain의 영향을 받아 negative transfer가 더 발생함
RQ3: CAT, ART Module이 어떻게 도움이 되는가
- SMF에 모듈을 하나씩 추가하여 성능을 비교해봄
- SMF
- +Autoencoder
- +Contrastive
- +ART
- -Attention
- Results
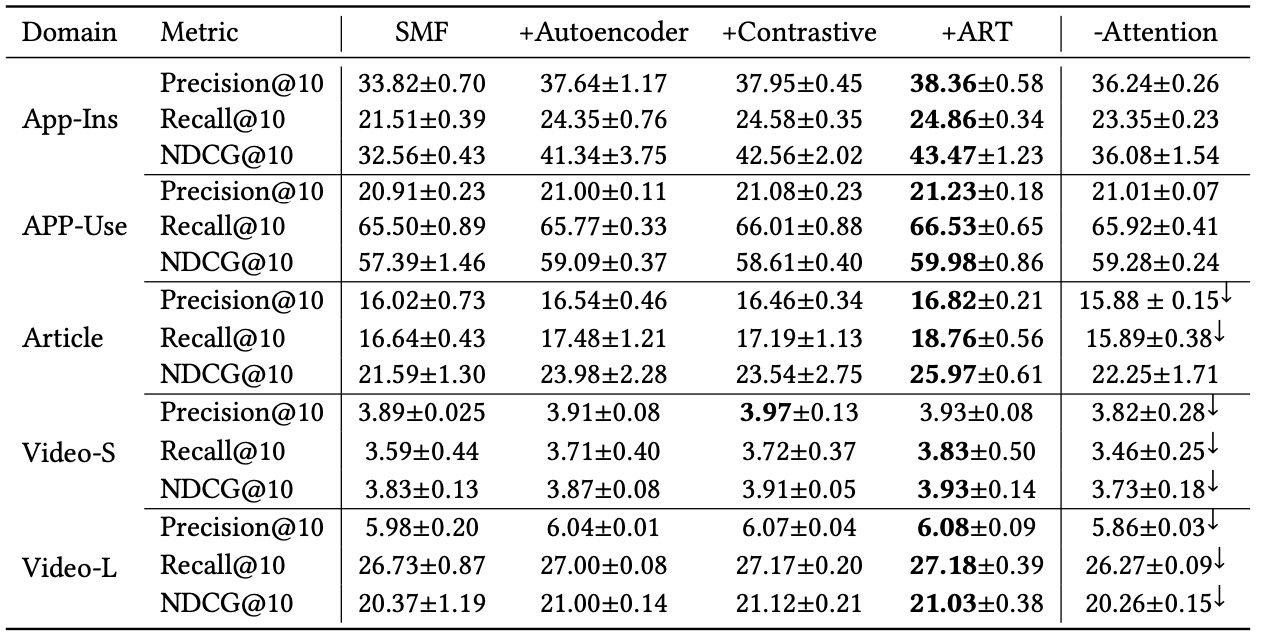
- Autoencoder를 추가하는 과정에서 이미 negative transfer를 해결한다고 주장
→ Reconstruct learning을 통해 noise를 제거 - Contrastive를 추가함으로서, general user representation을 생성하여 대부분의 domain에서 성능을 향상시켰지만, Article domain에서는 그러지 못함
- Contrastive loss의 목적은 domain-specific information의 의존도를 낮추고 noise를 제거하여 robust한 global user representation을 만드는 것임
- Article domain은 다른 도메인들과의 관계가 긴밀하지 않음
→ Global embedding에 Article domain의 정보가 적기 때문에 성능이 약간 떨어짐
- ART module내의 attention을 통해 negative transfer 문제를 회피하면서 추천 성능을 올릴 수 있음
- Video-S 도메인에서 ART module이 best performance
- Attention을 제거한 모델은 performance가 크게 하락
- attention이 negative transfer 문제를 해결해줌
- Autoencoder를 추가하는 과정에서 이미 negative transfer를 해결한다고 주장
- Attention
-
Attention matrix를 통해 target domain이 source domain으로부터 얼마나 참고했는지를 알 수 있음 (row: target, col: source)
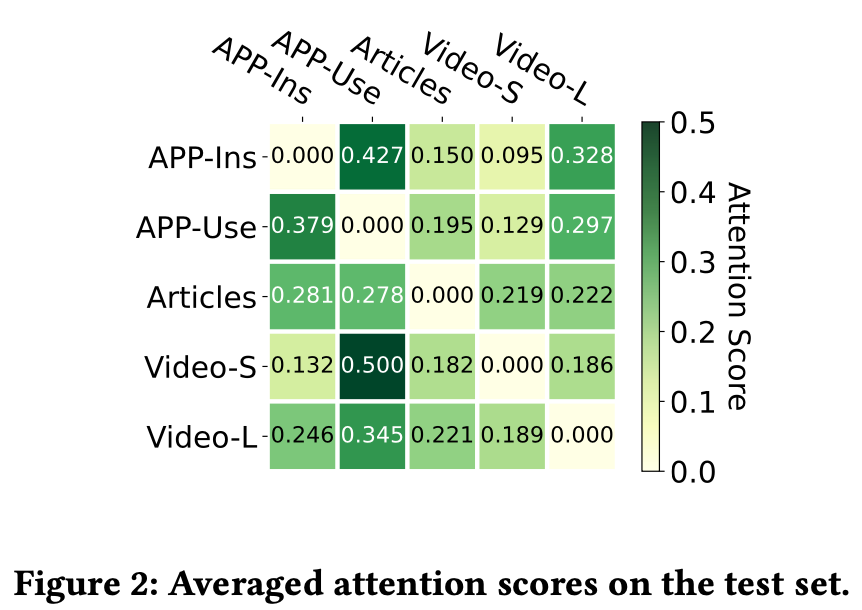
-
- 관련있는 도메인들간의 attention weight가 높게 나옴
- APP-Use - APP-Ins
- 관련없는 도메인들은 attention weight이 낮다
- APP-Ins - Video-L
- Attention matrix는 asymmetrical 하다
- 같은 도메인 쌍이라도 정보의 유용성은 다름 (APP-Use - Video-S)
- source domain에서 중요한 정보만을 가져오는 attention mechanism은 필요하다
4. CONCLUSION
- 저자들이 제안한 MTCDR CATART는 두 가지 모듈을 두어 MTCDR 문제를 해결하고 성능을 개선
- CAT: contrastive learning, autoencoder를 통해 robust global use representation을 생성, “One for All”
- ART: Attention mechanism을 통해 target domain에 유용한 specific embedding만을 가져옴, “All for One”
- 단순히 BPRMF로 얻어낸 domain-specific user embedding 만으로 성능이 좋은 모델을 고안한 게 대단한 거 같다.
- CATART는 M2M
- Overlapping user, item에 관해서는 일절 언급이 없었지만, 학습 과정 중에 자연스럽게 overlap user도 학습이 되는 거 같다.
After Meeting
- Attention mechanism이 negative transfer를 해결할 수 있다는 접근법이 아쉬움
- CATART는 clear한 모델이어서 다른 모델들의 compared baseline으로 많이 정하는 거 같음
