Jiangxia Cao et al.
WSDM 2023
ABSTRACT
- 데이터가 풍부한 기존 서비스에 비해 스타트업같은 새롭게 시작한 서비스는 데이터 부족으로 인한 cold-start 문제를 겪게 된다.
⇒ 이러한 문제를 해결하기 위해 cross-domain recommendation이 주목받고 있다.
- CDR은 source domain의 user-item 상호작용 정보를 유사한 target domain으로 전이하는 것을 목표로 함.
- 이전의 CDR 방법은 두 개로 나눌 수 있음
- Data Sparsity : 사용자의 상호작용이 적은 intra-domain (같은 도메인) recommendation을 위해 다른 도메인의 사용자 선호도를 활용한다.
- Cold-start : CDR은 사용자의 상호작용이 없는 inter-domain(다른 도메인) recommendation을 위해 다른 도메인의 사용자 선호도를 활용한다.
⇒ 현재까지 이 두 가지 문제를 동시에 해결할 CDR 방법은 시도되지 않았다.
⇒ 저자들은 UniCDR Framework를 제공한다. → domain-shared information을전송하여 여러 CDR 시나리오를 모델링할 수 있다고 한다.
⇒ 6개의 large-scale 산업 데이터셋과 4개의 CDR 시나리오를 이용하여 2가지 문제(Data Sparsity, Cold Start)에 대한 실험을 진행하였고, UniCDR의 효과성을 입증하였다.
1. INTRODUCTION
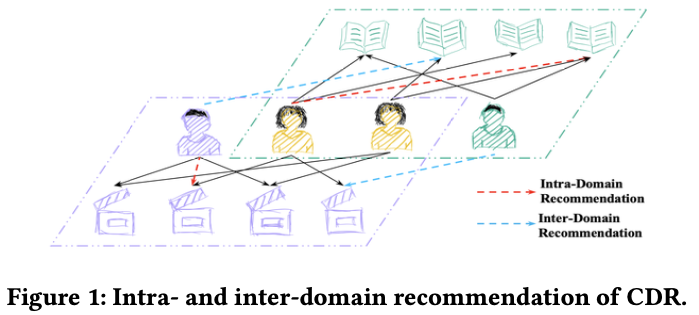
- CF 기반의 추천 방법들은 data sparsity, cold-start 문제에 직면한다. → 두 문제는, 유저-아이템 representation learning과 추천 결과에 영향을 줌.
- 이러한 문제를 해결하기 위해, Cross-Domain-Recommendation이 제안되었다. → 핵심 아이디어 : 관련된 source-domain에서 풍부한 상호작용 정보를 전이하여 target-domain에서의 예측 결과를 개선하는 방법(겹치는 사용자, 아이템을 통해 이루어짐)
- 기존 CDR 연구는 두 가지 분기로 나누어짐
- Data sparsity : 다른 도메인에서의 정보를 전이하여 intra-domain(내부)의 성능을 향상시키는 방법
- CoNet, Bi-TGCF
- 각 도메인의 사용자/아이템 representation을 인코딩 → 정보 전송 모듈을 정교하게 만들어 융합하기 → 각 도메인의 학습된 representation을 개선
- Cold-start : 다른 도메인에서의 정보를 전이하여 inter-domain(외부)의 성능을 향상시키는 방법 (Figure 1, 책 도메인의 사용자가 영화 도메인에서의 신규 사용자라면, 책 도메인의 정보를 이용하여 영화 도메인의 추천 성능을 향상시킨다.)
- EMCDR, SA-VAE
- training process
- 각 도메인에서 유저/아이템 representation을 사전 학습 → 사전 학습된 representation을 겹치는 사용자에 따라 정렬하는 mapping function을 학습
- source-domain의 user representation을 target-domain의 user representation으로 매핑할 수 있음.
- source-domain user에게 target-domain item을 추천할 수 있음.
- 각 도메인에서 유저/아이템 representation을 사전 학습 → 사전 학습된 representation을 겹치는 사용자에 따라 정렬하는 mapping function을 학습
- 두 방법(Data sparsity, Cold-start)은 각자의 시나리오에 대한 해결에 중점을 두고 있으며, 다른 시나리오에 적용시키기에는 부족하다.
- Data sparsity : 다른 도메인에서의 정보를 전이하여 intra-domain(내부)의 성능을 향상시키는 방법
- 우리는 좀 더 다양한 CDR 시나리오에 적용시킬 복잡한 프레임워크가 필요하다.
- All-domain에서의 성능을 올리기 위해 무슨 정보를 전이시켜야할까?
- 도메인에서의 사용자 행동은 다른 선호도를 만든다.
- Trustworthy information은 positive effects를 제공한다.
- Biased preference는 negative transferring problem을 야기한다.
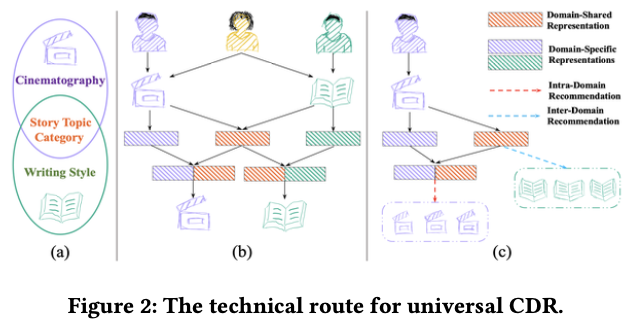
💡 Figure 2
- (a) 그림
- 두 개의 다른 도메인에서의 공통된 Story Topic과 Category와 같은 shared user preferences는 유저가 다른 도메인에서도 비슷한 취향을 보일 수 있음을 의미한다.
- 하지만 Cinematography와 Writing Style과 같은 specific user preferences는 다른 도메인에 기여하지 않는 정확한 intra-domain information을 제공한다.
⇒ domain-shared information을 포착하고 전송하는 것이 optimal way이다.
⇒ 이는 universal CDR을 구축하기 위한 reasonable한 기술적인 접근법이 될 것이다.
- 저자는 domain-shared information을 전송할 수 있는 통합 모델인 UniCDR을 제안한다.
- (b) 그림
- Training stage : UniCDR은 domain-shared representation과 domain-specific representation을 학습한다.
- (c) 그림
- Evaluation stage : UniCDR은 domain-shared information을 이용하여 intra- / inter-recommendation을 만든다.
- UniCDR을 구현하기 위해 간단하지만 효과적인 요소들을 활용한다. 각 요소에는 많은 대안이 있다.

- Mean, User-attention, Item-similarity based aggregators를 제공한다.
- Interaction & Domain masking mechanism을 제시한다. → domain-shared representation과 domain invariant information을 뚜렷하게 할 증강된 데이터를 생성한다.
- 4개의 다른 시나리오와 6개의 데이터셋을 이용한 실험을 통해 UniCDR이 경쟁력 있는 성능을 보여준다고 함.
2. PROBLEM STATEMENT
- : Domain, : User set, : Item set, : Interaction set,
- 는 binary interaction matrix
- : 도메인 X, Y, Z
- Dual vs Multi : 두 개의 도메인 간 지식을 전이? 여러 도메인간 지식을 전이?
- User vs Item : 도메인 간 user가 겹치는지? item이 겹치는지?
- Intra vs Inter recommendation : evaluation에서 Intra Rec인지? Inter Rec인지?
3. UNIVERSAL CDR
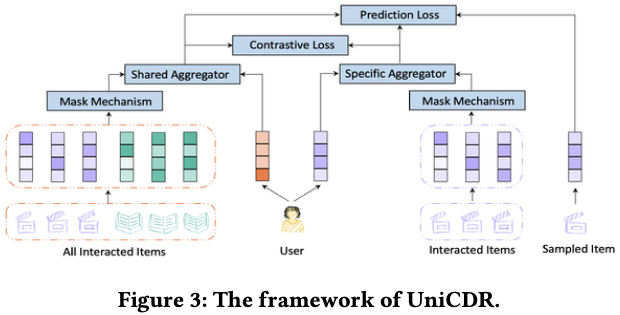
- Embedding Layer : domain-shared, specific representation matrix을 제공.
- Aggregator Architecture(Encoder) : domain-shared, specific representation을 생성.
- Masking Mechanism And Contrastive Loss : domain-shared representation과 domain-specific representation의 상관관계를 모델링함.
3.1 Embedding Layer
- domain-specific
- : 도메인 X의 사용자 특화 표현
- : 도메인 Y의 사용자 특화 표현
- domain-shared
- : 두 도메인에서 공유되는 사용자 표현
⇒ look-up operation을 이용하여 specific representation, shared representation을 쉽게 얻을 수 있음.
3.2 Aggregator Architecture
- 저자들은 UniCDR에서 세 가지의 aggregator를 실험했음.
- : 와 상호작용한 아이템들의 집합
- : 와 상호작용한 아이템들의 집합
- 겹치지 않는 사용자가 있기 때문
3.2.1 Mean-pooling aggregator
- 상호작용한 아이템의 정보를 동등하게 평균을 내는 직접적인 방법을 활용할 수 있다.
- : learnable parameter, : 최종 출력
- Mean-pooling aggregator는 GCN의 convolutional propagation과 유사하며, 간단한 디자인은 널리 알려져 있다. (PinSage, YouTubeNe)
3.2.2 User-attention-pooling aggregator
- Mean-pooling aggregator는 간단한 방법이어서 유저 별 아이템 가중치들을 무시할 수 있음.
- 저자는 좀 더 복잡한 aggregator로 확장시킴.
- 이때, attention weight 는 음수가 될 수 없고, 각 아이템의 중요도를 0 이상으로 표현
- 이 방법은 이웃 노드들의 중요도를 계산하는 GAT와 밀접하게 관련되어 있음.
3.2.3 Item-similarity-pooling aggregator
- 목적 : 사용자가 유사한 아이템에 흥미를 가지는 특성을 반영하여 item-item similarity 정보를 활용해 user-item 관계를 학습하고, 이를 통해 더 정교한 추천을 수행
-
(수식 3) item-item similarity 행렬 B 생성
- interaction matrix 가 주어진다면, item-item similarity weight 을 를 통해 생성한다.
- : Frobenius norm regularizer
-
(수식 4) 최적화 해법
- P
- 중간 계산 결과 ()
- : 아이템 간의 상호작용 정보를 기반으로 유사도 계산
- : 정규화 항 추가
- : 정규화된 아이템 유사도 정보의 역행렬
- 최종 B
- P의 대각선 값의 역수를 활용해 아이템 간 유사도를 정규화
- 대각선이 0인 최종 유사도 행렬 B를 생성
-
(수식 5) 아이템 유사도를 기반으로 user-item 스코어 계산
- : 사용자별 개인화된 아이템 스코어 행렬
- : 아이템 간 유사도 행렬 B와 user-item Interaction 행렬 A의 곱
- : 사용자 가 아이템 와 얼마나 관련 있는지를 나타내는 점수
- 정규화 ()
- : 각 아이템의 가중치
- 모든 가중치 합이 1이 되도록 정규화
- : 사용자별 개인화된 아이템 스코어 행렬
-
(수식 5) 최종 아이템 표현 계산
- WEIGHTEDMEAN : 를 가중치로 사용해 아이템 벡터들의 가중 평균 계산
- : 학습 가능한 가중치 행렬로, 최종적인 아이템 표현을 계산
3.2.4 Domain-specific & domain-shared representations
- 3.2.3의 세 가지 aggregator를 기반으로 domain-specific & domain-shared representation을 생성할 수 있다.
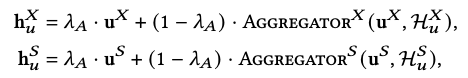
- : 도메인 X에서의 사용자 임베딩, 해당 도메인에서의 사용자의 고유 특징
- : 도메인 X에서의 사용자가 상호작용한 아이템들의 정보 → 사용자가 상호작용하는 아이템의 정보를 통해 사용자의 선호도를 추론
- : 사용자 임베딩이 최종 표현에서 얼마나 기여할지를 조정
- : 아이템 정보가 최종 표현에서 얼마나 기여할지를 조정
⇒ 사용자 데이터가 충분하다면 의 값을 높게, 사용자 데이터가 부족하다면 를 낮게 설정
3.3 Masking Mechanism and Contrastive Loss
- 대조 학습(Contrastive learning)은 추천 시스템에서 큰 발전을 이루었음
- 데이터 증강(Multi-view augmentation)
- 원본 데이터를 변형하여 새로운 데이터를 생성
- 이 과정에서 masking mechanism이 사용되며, 일부 정보를 가리거나 변형하여 다양한 뷰를 만듬
- 양성 쌍(Positive pairs)
- 동일 사용자의 데이터에서 원본 데이터와 증강된 데이터를 쌍으로 묶음 → 한 사용자가 도메인 X와 Y에서 상호작용한 데이터를 각각 하나의 뷰로 생성하고, 이 둘을 양성쌍으로 설정
- 동일 사용자의 데이터에서 원본 데이터와 증강된 데이터를 쌍으로 묶음 → 한 사용자가 도메인 X와 Y에서 상호작용한 데이터를 각각 하나의 뷰로 생성하고, 이 둘을 양성쌍으로 설정
- 음성 쌍(Negative pairs)
- 관련 없는 데이터를 샘플링하여 음성 쌍을 만듬 (다른 사용자의 데이터를 음성 쌍으로 설정)
- 데이터 증강(Multi-view augmentation)
- Positive / Negative -pair 구별
- Binary discriminator를 사용
- positive pair : 같은 사용자의 데이터를 묶음
- negative pair : 다른 사용자의 데이터를 묶음
- 모델은 양성 쌍의 유사성을 높이고, 음성 쌍 간의 차별성을 증가시키도록 학습함
- Binary discriminator를 사용
- Mutual information 관점에서의 Contrastive Learning
- 대조 학습은 다양한 뷰 간의 상호정보량(Mutual Information)을 극대화함
- domain-specific, domain-shared representation을 학습하여 도메인 간 공통된 특징을 극대화
- Domain-shared Aggregator와 Domain invariant information
- 저자는 domain-shared aggregator를 사용하여 domain invariant information을 추출
- domain invariant information을 학습하여 두 도메인 간의 차이를 초월한 추천 성능을 제공
- domain-specific 정보의 여러 뷰를 활용하여 양성 쌍의 가능성을 최적화
- domain-shared 정보를 더 잘 학습하여 추천 품질을 개선
- 저자는 domain-shared aggregator를 사용하여 domain invariant information을 추출
3.3.1 Masking Mechanism
- Interaction Masking
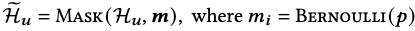
- 다양한 Item context information을 구성하기 위해 에서 랜덤으로 아이템을 삭제
- 베르누이 확률분포를 따르는 masking 벡터 을 생성
- augmened data는 specific / shared aggregator의 input data를 생성한다.
- 다양한 Item context information을 구성하기 위해 에서 랜덤으로 아이템을 삭제
- Domain Masking
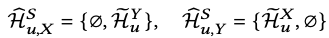
- domain-invariant information을 추출하고, domain-shared representation을 학습하기위한 마스킹 기법
- : 도메인 Y에서 사용자 가 상호작용한 원본 데이터 를 변형한 것
- : shared aggregator Input
- : 도메인 X에서 학습 시 shared aggregator에 입력
- 사용자 가 다른 도메인 에서 상호작용한 아이템들로 구성
- : 도메인 Y에서 학습 시 shared aggregator에 입력
- 사용자 가 다른 도메인 에서 상호작용한 아이템들로 구성
- : 도메인 X에서 학습 시 shared aggregator에 입력
3.3.2 Contrastive loss calculating process
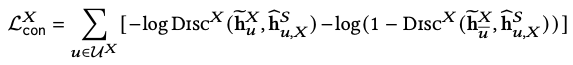
- 두 마스킹 기법을 통해 specific-shared augmentation representation pair를 얻을 수 있음 ,
- 좌항 : positive specific representation → 1로 수렴해야 함 → log(1) = 0
- 우항 : negative specific representation → 0으로 수렴해야 함 → 1-0 = log(1) = 0
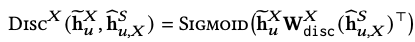
- 판별함수를 자세히 보면 두 임베딩간의 관계를 확률(0~1)로 나타냄 → 값이 1에 가깝도록, 값이 0에 가깝도록
- 이때 는 Learnable weight matrix임.
3.4 Prediction Loss
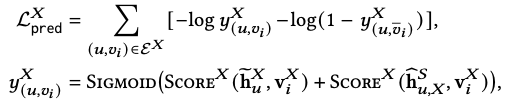
- 기존의 prediction loss 설명
- pair-wise : ranking loss, 실제 상호작용한 아이템 더 높은 점수를 얻도록, (Hinge, BPR)
- point-wise : 실제 상호작용한 아이템을 맞추는 데에 초점을 둠, (BCE, Squared loss)
- user-item interaction은 implicit score로 표현 (0 or 1).
- 모델은 user-item pair에 대해 상호작용할 확률을 0과 1사이로 출력(sigmoid) → BCE loss는 이 확률값과 실제 레이블(0 or 1)을 비교해 계산
- 저자는 BCE loss로 prediction을 진행하였음.
3.5 Training and Evaluation
3.5.1 Model training
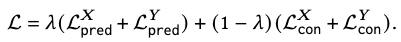
- : harmonic factor, 0~1사이의 값
- → 1 : 예측 손실 항목이 더 큰 비중을 차지하여 모델이 예측 정확도를 높이는 데 집중
- → 0 : 대조 손실 항목이 더 큰 비중을 차지하여 도메인 간의 일반화 능력을 향상시키는 데 집중
3.5.2 Model Evaluation
- evaluation 과정에서 masking mechanism은 생략하고 domain-specific, domain-shared representation을 생성한다. → 학습 과정에서는 도메인 간 차별화를 위해 마스킹을 적용했지만, 평가에서는 모든 정보를 기반으로 표현을 생성
- 도메인 X의 사용자를 예시
-
intra-domain item score
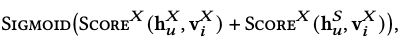
-
좌항 : 사용자 의 domain-specific representation 와 아이템 의 유사도를 계산
-
우항 : 사용자 의 domain-shared representation 와 아이템 의 유사도를 계산
-
두 점수를 더해 최종적으로 가 를 선호할 가능성을 예측
-
inter-domain item score
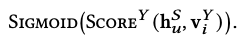
-
domain-shared representation 이므로, 가 다른 도메인 Y에 있는 아이템 를 선호할 가능성을 예측
💡
도메인 Y의 사용자는 반대로 적용시키면 됨
-
4. EXPERIMENTS
4.1 Datasets
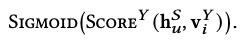
- Amazon dataset으로 실험을 구성하였음. → 공평한 비교를 위함
[시나리오 구성]
- Scenario 1 : Dual-Intra-Domain recommendation
- Object : 두 도메인 내에서 추천 성능을 평가
- 데이터셋 : DisenCDR에 의해 전처리된 데이터 사용
- Sport-Cloth
- Elec-Phone
- 특징 : 두 개의 독립된 도메인 내 사용자와 아이템 간 상호작용 데이터
- Scenario 2 : Dual-Inter-Domain recommendation
- Object : 도메인 간 추천 성능을 평가
- 데이터셋 : CDRIB에 의해 전처리된 데이터 사용
- Sport-Cloth
- Game-Video
- 특징 : 도메인 간 상호작용 데이터로, 두 도메인 간 정보 전이를 평가
- Scenario 3 : Item-Overlapped Multi-Intra-Domain recommendation
- Object : 아이템이 겹치는 다중 도메인 내 추천 성능을 평가
- 데이터셋 : M3Rec에서 전처리된 데이터 사용
- Electronic domain : 5개의 익명 국가 데이터 포함
- 특징 : 여러 도메인에서 동일한 아이템이 등장하며, 도메인 내 상호작용에 초점을 둠
- Scenario 4 : User-Overlapped Multi-Intra-Domain recommendation
- Object : 사용자가 겹치는 다중 도메인 내 추천 성능을 평가
- 데이터셋 : MYbank의 3개 실제 서비스
- 특징 : 금융 서비스 특성 상 아이템 수가 Amazon보다 훨씬 적음
- 문제점 : 이 시나리오에 대한 공개 데이터셋 부족으로 자체 데이터셋을 구축
4.2 Experimental Setting
4.2.1 Evaluation Protocol
- Leave-One-Out Technique
- Scenario 1, 2, 3에서 사용
- 방법
- 각 사용자에 대해 테스트 세트에 있는 정답 아이템 (ground-truth item)을 하나 남기고 나머지 데이터를 훈련에 사용
- 모델이 테스트 아이템을 얼마나 잘 예측하는지 평가
- 샘플링
- 테스트 및 검증 세트에 대해, 각 정답 아이템(ground-truth item)과 함께 999개의 negative items(상호작용 X 아이템)을 무작위로 샘플링하여 비교
- Full-Rank Method
- Scenario 4에서 사용
- 방법
- 모든 아이템에 대해 모델이 예측한 점수를 계산한 뒤, 순위를 매김
- 전체 아이템 집합을 고려하기 때문에 전체 순위 기반 평가 방식
- Item list ranking
- 두 평가 방식 모두에서, 모델은 테스트 세트의 사용자-아이템 쌍에 대해 점수를 예측하고, 아이템들을 점수 순위에 따라 정렬
- Top-10 아이템을 추출하여 평가 지표를 계산
4.2.2 Compared Baselines
- UniCDR을 평가하기 위해 비교한 다양한 기존 방법들을 네 가지 그룹으로 분류
- Single-Domain Baselines
- 목적 : 단일 도메인에서 추천 성능을 평가하는 기존 방법과 비교
- 비교 모델
- BPRMF : 행렬 분해(MF)를 기반으로 한 베이스라인 방법
- NeuMF : 신경망 구조를 활용한 협업 필터링 모델
- CML : User-Item 임베딩 유사성을 학습하는 대조 손실 기반 방법
- : 행렬 기반 추천 방법
- Graph-based Models
- Random Walk
- NGCF
- LightGCN
- Intra-Domain CDR Baselines
- 목적 : 도메인 간 상호작용을 고려한 CDR 성능 비교
- 비교 모델
- CoNet, DDTCDR : MLP 기반 인코더를 도메인 별로 설계하여, 소스 도메인과 타겟 도메인 간 상호작용을 학습
- GNN 기반 모델 : PPGN, Bi-TFCF, DisenCDR
- GNN을 활용하여 사용자와 아이템의 표현을 강화
- Inter-Domain CDR Baselines
- 목적 : 소스 도메인 데이터를 타겟 도메인으로 전이하는 방법의 성능 비교
- 비교 모델
- EMCDR, SSCDR, TMCDR, SA-VAE : 사용자 임베딩을 소스 도메인에서 타겟 도메인으로 매핑하는 함수 학습
- CDRIB : variational information bottleneck principle을 사용하여 domain-invariant 표현을 학습
- Multi-Domain Baselines
- 목적 : 여러 도메인을 동시에 고려하는 추천 문제에서의 성능 비교
- 비교 모델
- User-Overlapped Scenario
- GA-MTCDR, HeroGraph : 전역 그래프와 지역 그래프를 동시에 모델링
- Item-Overlapped Scenario
- FOREC, : 아이템 간의 유사성을 학습하여 도메인 내/ 도메인 간 추천 성능 개선
- dms intra-domain과 inter-domain 아이템 유사성을 강조
- Multi-Task Framework
- Cross-Stitch, MMoE, STAR : MLP 기반 shared encoder와 specific decoder을 사용
- User-Overlapped Scenario
- Single-Domain Baselines
4.3 Performance Comparisons
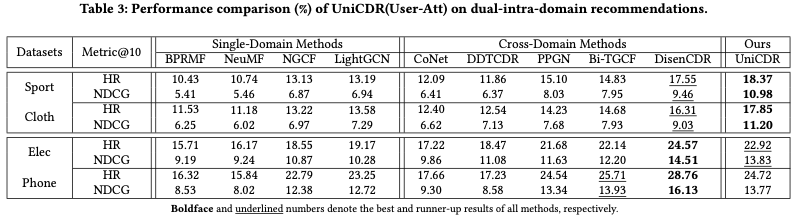
- Dual-Intra-Domain Recommendation
- UniCDR이 Sport-Cloth 데이터셋에서 가장 높은 HR@10과 NDCG@10 값을 기록
- Elec-Phone 데이터셋에서 HR@10, NDCG@10 지표가 각각 2위, 3위를 기록함
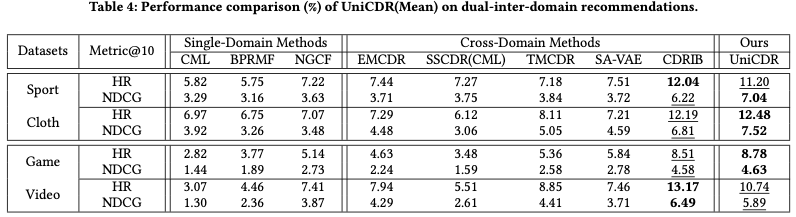
- Dual-Inter-Domain Recommendation
- UniCDR은 Cloth와 Sport 데이터셋에서 가장 높은 NDCG@10와 HR@10 점수를 기록
- Game-Video 데이터셋에서는 CDRIB가 가장 우수했지만, UniCDR도 상위권 성능을 유지(2위)
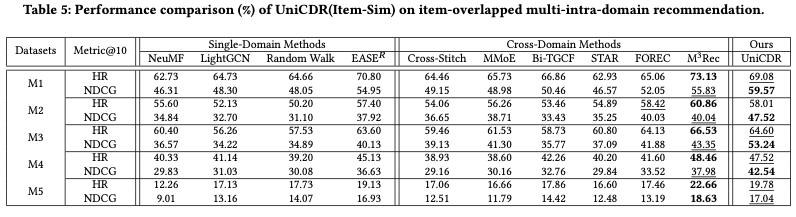
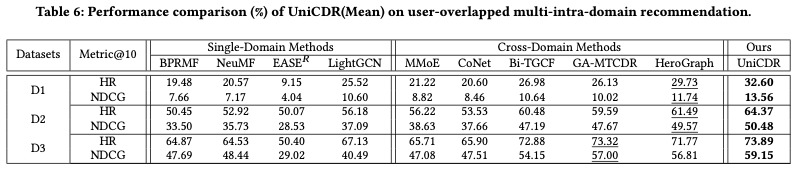
- Single-Domain Methods와 Cross-Domain Methods
- cross-domain 모델은 single-domain 모델과 비교하여 일관된 예측 성능 개선을 보였음
- 이는 도메인 간의 차이를 무시하고 데이터를 단일 도메인으로 합쳐서 학습하는 것보다 도메인 간의 차이를 인식하고 정보를 전이하는 전략을 사용하는 것이 더 효과적임
- graph-based encoder method(PPGN, Bi-TGCF, HeroGraph)는 Feed-Forwarding methods(CoNet, MMoE)보다 큰 성능 개선을 보여준다.
- 그래프 기반의 모델은 직접적인 상호작용뿐만 아니라 간접적인 연결 또한 학습하므로 복잡한 도메인 구조를 잘 반영하기 때문이다.
- Domain-shared information을 포착하고 전송하는 모델(DisenCDR, CDRIB)이 다른 베이스라인 모델들에 비해 더 나은 성능을 보였음 → 적절한 transferring 전략이 예측 결과에 큰 영향을 끼침
- 저자들이 제안한 UniCDR은 최신 graph-encoder baseline(DisenCDR, CDRIB, M^3Rec)와 competitve prediction result를 보여줌 (UniCDR은 high-order neighboring information을 위한 graph-encoder를 쌓지 않음 → 연산량이 적고 효율적임)
⇒ domain-shared information을 포착하고 전송하는 것이 CDR Scenario에 필수적임을 보여줌
DisenCDR과 CDRIB은 variational inference framework를 통해 목표를 구현하지만, UniCDR은 Maskin Mechanism과 Contrastive loss를 통해 목표를 달성했다.
4.4 Analysis of Aggregators
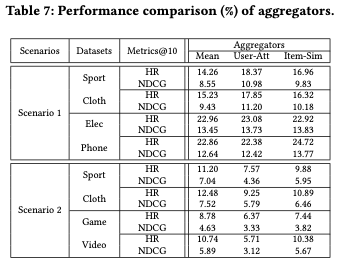
- Scenario 1 (Dual-Intra-Domain) 에서는 User-Attention > Item-Similarity > Mean 순으로 높은 성능을 보임 → Intra-Domain Rec에서는 아이템 간 차별적인 중요도를 고려하는 것이 성능 향상에 기여 → 각 아이템의 중요도를 반영하여 user representation을 학습하는 것이 효과적
- Scenario 2 (Dual-Inter-Domain) 에서는 Mean-Pooling Aggregator가 가장 안정적인 성능을 보임 → Inter-Domain Rec에서는 특정 아이템에 의존하기보다 모든 아이템을 균등하게 고려하는 것이 더 적합 → 다양한 도메인 간 정보가 섞이는 환경에서는 단순한 pooling 전략이 더 안정적
⇒ 적절한 aggregator를 선택하는 것은 CDR 시나리오에 따라 추천 성능에 큰 영향을 미침
4.5 Analysis of Masking Mechanism
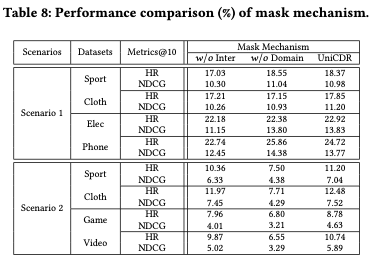
- Masking Mechanism이 CDR에서 representation 학습을 얼마나 지원하는지를 분석함
- Inter, Domain은 각각 Interaction mask, Domain mask가 없는 UniCDR 모델
- Inter과 UniCDR : interaction mask는 모든 CDR 시나리로에서 domain-shared information을 인코딩하기 위해 모델을 강화하는 reliable 방법임
- Domain과 UniCDR : Intra-domain recommendation에서 우수한 성능 개선이 일어나는 것을 발견함
- domain mask가 Inter-domain recommendation을 시뮬레이션한다
- → domain masking은 모델이 domain-specific information 대신 domain-shared information을 더 많이 활용하도록 함
- 이를 통해 학습된 domain-shared representation은 더 일반화된 특성을 가지며, 다양한 도메인에서 효과적으로 작용할 수 있음
- Cold-Start 문제 완화 : 새로운 사용자나 아이템에 대한 데이터가 부족하여 발생
- 마스킹 매커니즘은 domain-shared pattern을 학습하기 때문에, 데이터가 부족한 상황에서도 추천 성능을 유지할 수 있음
- domain mask가 Inter-domain recommendation을 시뮬레이션한다
- Interaction mask는 일관된 추천 개선을 보여주지만, Domain mask는 inter-domain 추천에는 개선을 이룸, 하지만 intra-domain에는 별 영향을 주지 못함.
4.6 Hyperparameter Discussion
-
Aggregator factor
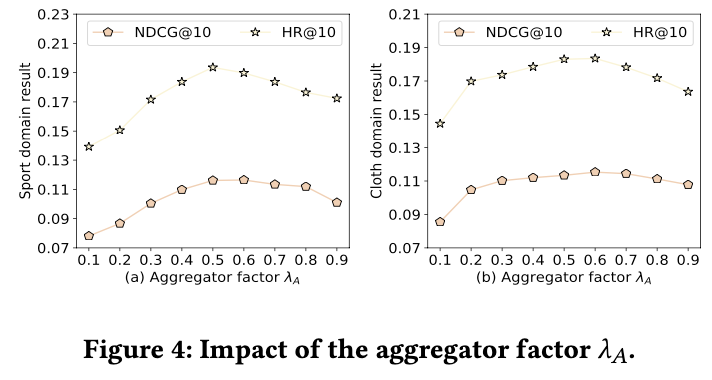
- 유저 임베딩과 유저-아이템 상호작용 정보의 비중을 조절함
- → 1, 유저 임베딩에 중점을 둠, 사용자 기반 CF
- → 0, 아이템 정보에 중점을 둠, 아이템 기반 CF
- 값이 0.4~0.6 범위일 때, 두 도메인 모두 높은 성능과 안정적인 결과를 보임 → 사용자 정보와 아이템 상호작용 정보를 융합하는 것이 더 나은 representation을 생성하는 데 중요함을 의미
- 는 사용자-CF와 아이템-CF 간의 trade-off를 형성
- 따라서 는 0.5에 근사한 값으로 설정하는 것이 성능을 최적화하는 합리적인 선택
-
Training loss factor(harmonic factor)
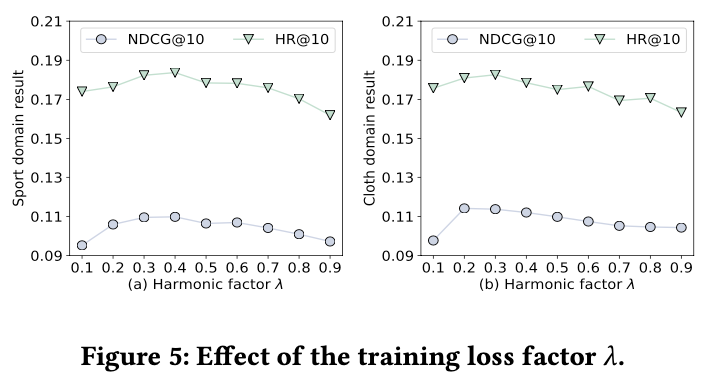
- → 1 : 예측 손실 항목이 더 큰 비중을 차지하여 모델이 예측 정확도를 높이는 데 집중
- → 0 : 대조 손실 항목이 더 큰 비중을 차지하여 도메인 간의 일반화 능력을 향상시키는 데 집중
- = 0.1 일 때, 성능이 낮았으나 0.2~0.4 범위에서 모델 성능이 개선됨
- 가 너무 큰 값으로 설정되면 성능이 감소하는 추세를 보임
- = 0.3 또는 0.4는 성능과 학습 수렴 속도 간의 균형을 제공
- 대조 손실이 도메인 간 정보 공유를 학습하는 데 효과적임을 입증
-
와 모두 모델 성능과 효율성에 큰 영향을 미치는 중요한 하이퍼파라미터임
-
UniCDR은 하이퍼파라미터 설정 변화에도 비교적 robust한 성능을 보이며, 모델의 안정성을 나타냄
⇒ : 사용자 정보와 아이템 상호작용 정보를 균형 있게 융합하기 위해 0.4~0.6 범위로 설정, =0.5는 user-CF와 item-CF 간의 적절한 균형을 제공
⇒ : 대조 손실의 효과를 극대화하고 학습 속도를 유지하기 위해 0.3~0.4 범위가 적절
5. RELATED WORKS
-
CDR for Intra-Domain Recommendation
- Data-Sparsity 문제를 완화하고 도메인 내 추천 성능을 개선
- 중복되는 사용자나 아이템을 통해 관련 도메인들의 정보를 통합하여 해결하는 방법을 사용했음
-
CDR for Inter-Domain Recommendation
- Cold-Start 문제를 완화하여 새로운 사용자나 아이템 경험을 개선
- 소스 도메인 데이터를 활용해 타겟 도메인의 부족한 데이터를 보완
-
대부분의 기존 CDR은 특정 시나리오에만 초점을 둠
- 임베딩 매핑 방식은 Inter-domain rec에 적합하지 않음
-
하나의 기술 프레임워크가 모든 시나리오에서 좋은 결과를 내지 못함
⇒ UniCDR은 CDR의 핵심 과제인 domain-shared information transfer를 효과적을 처리하여 Intra-domain, Inter-domain 시나리오를 모두 모델링할 수 있는 Unified Framework
6. CONCLUSIONS
- UniCDR 공헌
- 통합적 CDR 프레임워크 제안
- 저자는 통합된 domain-shared information transfer 관점에서 모든 CDR 시나리오를 처리할 수 있는 유연한 프레임워크인 UniCDR을 제안함.
- CDR 문제의 최적의 솔루션은 domain-shared information을 포착하고 전이하는 것이라 주장함
- 단순하지만 효과적인 설계
- UniCDR은 간결한 설계로 domain-shared, domain-specific representation을 생성
- 모델 구조가 단순하여 이해하기 쉽고 구현이 간편함
- 향상된 domain-shared representation
- Masking Mechanism과 Contrastive Learning을 도입하여 domain-shared representation이 domain-invariant information을 인코딩하도록 함
- 통합적 CDR 프레임워크 제안
- 실험 결과
- 4가지 CDR 시나리오와 6개의 데이터셋에서 실험을 수행
- 최신 SOTA methods와 비교해 경쟁력 있는 결과를 달성
- 다양한 시나리오에서 유연성과 높은 성능을 입증
- 산업적 활용 가능성
- 간단한 모델 구조로 인해 UniCDR은 산업 환경에서 쉽게 적용 가능
- 대규모 데이터나 다양한 도메인 간 추천 시스템 구축에 적합
- 향후 연구 방향
- Graph-encoder-based aggregator를 UniCDR에 통합
- 포괄적인 masking mechanism을 탐색
