PFCDR: Privacy-Friendly Cross-Domain Recommendation via Distilling User-Irrelevant Information
Cross Domain Recommendation
Cheng Wang at al
WWW (2025)
ABSTRACT
- Privacy-preserving CDR은 사용자의 민감한 정보를 보호하면서 source domain을 보조정보로 활용해 cold-start 문제를 해결함
- 존재하는 privacy-preserving CDR은 민감한 사용자 임베딩이나 행동 로그 전송에 의존하고 있는데, 보호를 위해 전송전에 데이터를 왜곡시키는 방법을 사용
→ 이 방법은 전체적인 성능을 감소시킴 - 저자들이 제안하는 방법은 기존의 privacy preserving CDR의 개인정보보호를 중점으로 두는 것과는 다름
→ 민감한 사용자의 정보를 사용하지 않고 아이템 임베딩에서 transferable information을 추출 (Prototype) - 구체적으로 사용자들을 위한 정교한 prototype 추출을 위한 conditional model inversion mechanism을 제안
- Prototype은 domain shift의 bridge를 수행할 수 있음
- 게다가 cold-start 환경에서 더 나은 추천 성능을 보임
1. Introduction
-
source domain의 선호도 정보를 보조정보로 사용하여 target domain에서의 추천을 향상시키는 CDR
-
따라서, CDR은 knowledge transfer process가 필수적임
→ 주로 user embedding, mapping relationship에 대해 집중하고, user preference를 전송되는 latent space와의 bridge function에 의존 -
이를 위한 original plaintext embedding, interaction data은 GDPR이라는 새로운 보안규제로 인해 사용할 수 없음
→ CDR은 data privacy의 보장하는 모델을 고안해야함 -
저자들은 privacy-preserving knowledge transfer에 집중
- 이전 CDR setting에서 두 도메인은 사용자는 일부 겹치지만 아이템은 겹치지 않음
-
최근 많은 privacy-preserving CDR은 다른 privacy mechanism을 적용시켜 original embedding에 대한 보안을 유지하고 있음
→ Privacy budget이라는 노이즈 강도를 조정함- Privacy Budget
1. original embedding에 noise를 추가하여 학습
2. 이때 noise의 강도를 조절하는게
3. 을 크게 → noise를 약하게 → privacy 강도 ⬇️
을 작게 → noise를 강하게 → privacy 강도 ⬆️
- Privacy Budget
-
이러한 방식으로 인해 기존의 privacy-preserving CDR은 utility-privacy 간의 균형을 잘 잡아야 함 → Traditional CDR보다 optimal하지 못함
-
user privacy를 보호하는 건 CDR의 challenge임
-
CDR에서의 개인정보유출은 도메인간 original user embedding, user rating information를 transfer하는 중 발생함
→ user information 대신 item embedding을 사용하여 privacy도 지키고 satisfactory performance도 달성할 수 있을까? -
저자는 이러한 idea를 확장한 Privacy-friendly Cross-domain recommendation (PFCDR)을 제안
→ target domain을 promote하는 prototype을 아이템 임베딩으로부터 추출 -
user embedding을 사용하지 않는 data-free 조건을 추가하고, 이 조건때문에 prototype을 사용, 이를 생성하기 위해 conditional model inversion mechanism을 고안
- Data-free
- 기존의 보안을 강조한 추천 모델들은 noise를 추가하는 방식을 사용하지만, 그럼에도 민감한 정보가 유출될 수 있음
- data-free 조건을 추가함으로서 민감한 정보가 하나도 유출되지 않도록 함
- data-free 조건하에서 source domain의 user-item interaction, user embedding을 전혀 사용하지 않음
→ item embedding과 pre-trained model만을 가지고 conditional model inversion을 이용하여 모델 내부의 collaborative signal을 distill
- Data-free
-
하지만, CDR task에서 model inversion을 구현하는 것은 task의 특징으로 인해 어려움
-
RS의 데이터는 ont-hot representation으로 표현이 됨
→ gradient 계산이 어려움 -
universal learning paradigm이 필요
⇒ gradient 계산을 위한 continuous & dense data format을 설계
- 새로운 data format에 맞는 learning paradigm도 소개
- 정리
-
개인정보보호를 위해 사용자 정보를 아예 사용하지 않는 data-free 조건이 추가되었음
-
source domain의 user-item interaction, user embedding을 전혀 사용하지 않음
-
pre-trained model을 이용하여 input을 조정해야함 → model inversion
-
하지만 input이 one-hot이라 gradient를 계산하는데 어려움
-
gradient를 계산하기 쉽게 continuous & dense data format을 설계
5-1. 현재 방법으로는 아이템 4번째, 5번째 그 자체에 대해서만 수정할 수 있지만, 아이템 4번째를 30%만 조정해보는 조작이 안됨
-
-
-
추가로 cold-start scenario에서 source domain의 user prototype을 pre-trained bridge function을 통해 target domain으로 전송하여 cold-start를 완화시킬 수 있음
2. Preliminaries and Challenges
2.1 Problem Setting
- User set
- Item set
- Rating matrix
- Source / Target domain
- Overlapping users
- One-hot interaction instance
- latent factor mode에서 instance는 low-dimensional dense vector로 매핑됨
- : Embedding matrix
2.2 Challenges
- PFCDR의 목적은 user-sensitive data의 전송 없이 informative knowledge를 추출하는 것
→ collaborative signal이 들어있는 Item embedding을 사용해야함
→ 다음과 같은 challenge가 존재 - CH1: 두 도메인간 아이템이 겹치지 않는 상황일 때, 아이템 임베딩으로부터 어떻게 transferable information을 추출할까?
- Solution: conditional model inversion을 통해 transferable knowledge를 직접 추출후 이를 통합 → 이를 Prototype
- CH2: overlapping user와 behavior log없이 어떻게 domain shift를 줄일 수 있을까?
- Solution: overlapping user prototype도 추출하여 domain shift problem을 해결하는 bridge function을 설계
- CH3: source domain으로부터 추출한 prototype으로 어떻게 cold-start user preference를 예측할까?
- Solution: prototype을 전송해 top-k similar user를 식별하면 cold-start user preference를 계산할 수 있음
3. Methods
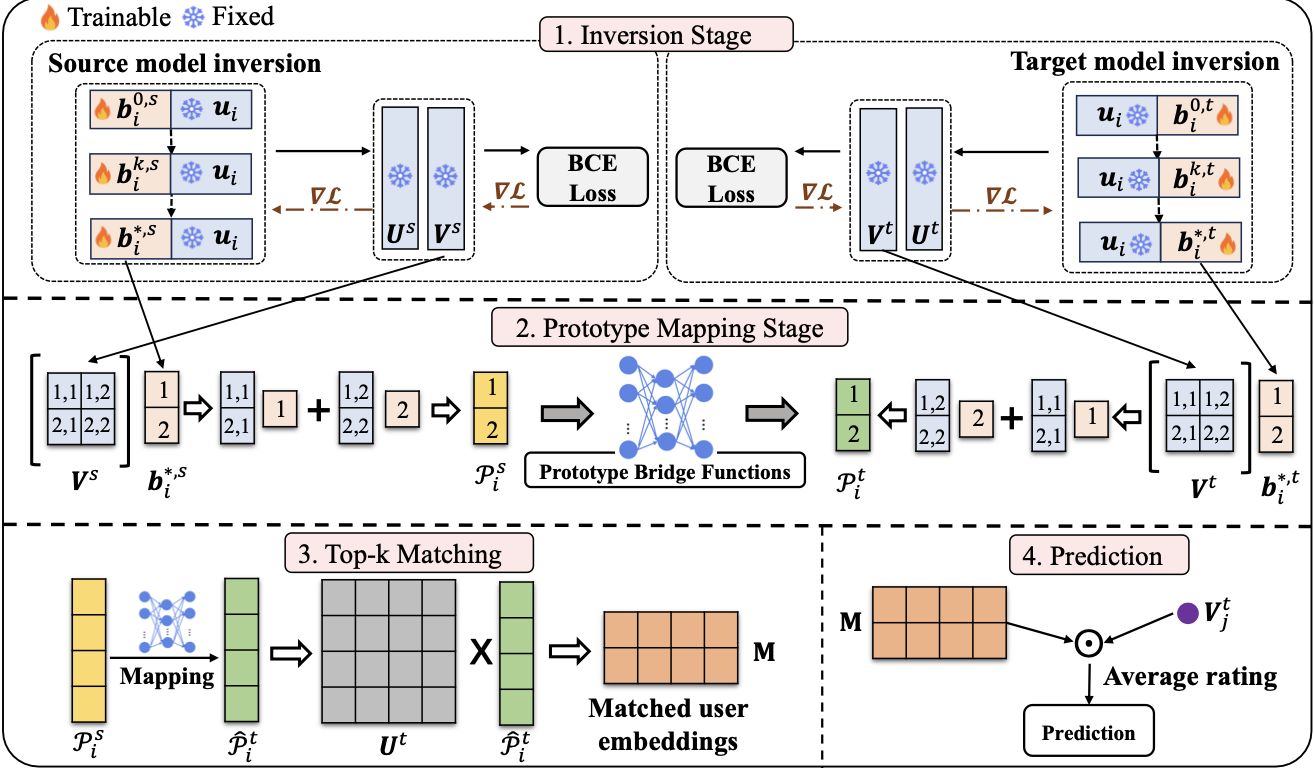
- Inversion Stage: source-target의 user prototype을 추출
- Prototype Mapping Stage: domain간 gap을 align하기 위해 prototype을 이용하여 bridge function을 학습
- Top-k Matching: bridge function을 이용해 top-k similar user 식별
- Prediction: 추천 예측
3.1 New Data Format and Learning Paradigm for Adopting Model Inversion
- model inversion은 일반적으로 class conditional generation이라고 부르며, pre-trained classifier에서 원하는 label을 출력하는 input을 생성하는 것
- : pre-trained model parameterized by
- : pre-trained loss function
- Recommendation scenario에서 model inversion은 loss function을 최소화해야함
- 기존의 추천모델은 lookup embedding table을 이용하여 embedding을 return함
→ gradient를 이용한 optimization이 안됨 - 저자는 new data format을 고안
3.1.1 The new data format
- the new data format은 다음과 같은 제약조건이 있음
- inversion 동안 성공적으로 optimize 되어야 함
- 추천모델에 적용할 수 있어야 함
- lookup embedding에 영감을 받아 ont-hot representation을 식별할 수 있는 data format을 정의
- one-hot representation인 original data와는 달리 continuous value
- Softmax로 정규화된 값
- new data format으로 RS model inversion을 구현은 다음과 같음
3.1.2 The additional learning paradigm for adopting new data format
- 기존 RS model은 new data format으로 사용할 수가 없음
- MF로 예시:
- Input data를 new data format인 로 바꾸게되면 feed-forward 과정에서 다음의 임베딩을 얻음
- 이렇게 얻어진 임베딩은 end-end optimization으로 직접 사용할 수 없음
→ 임베딩의 차원이 다르기 때문 → weigted sum 계산 추가 - user embedding matrix U와 item embedding matrix V를 이용해 MF에서의 model inversion이 가능
3.2 The Generation of Users’ Prototypes
- : user 에 대한 model inversion을 통해 추출된 벡터
- 의 Prototype은 와 전체 item embedding 를 weighted sum을 통해 얻어진
- Eq 6.은 특정 interaction r을 기대하는 input만을 유도하기 때문에, 여러 사용자의 정보들이 섞여버릴 수 있음. 즉 어떤 사용자의 정보가 들어갔는지, 어떤 아이템의 정보가 들어갔는지 알 수 없음
- 직관적으로 user’s rating preference는 그 사용자의 특성을 나타냄
-
따라서 user embedding과 interaction r을 고정시켜 b에 대한 gradient update를 수행하는 conditioned model inversion을 고안
-
- source domain에서 얻어진 특정 사용자에 대한 아이템 조합인 b는 바로 다른 도메인으로 전송시킬 수 없음
-
두 도메인의 아이템들이 다름
-
두 도메인의 임베딩 사이즈가 다름
⇒ b를 source domain item embedding V와 weighted sum으로 해당 사용자에 대한 대표 성향을 나타내는 prototype으로 함축
-
- P는 source domain에서 user 에 대한 prototype
3.3 User Prototype Mapping
- CDR에서는 knowledge transfer 과정이 필수적임
→ 이전 방법들은 overlapping user를 이용해서 domain align을 위한 mapping function을 만듬 - PFCDR에서는 overlapping user의 prototype을 이용하여 domain shift를 해결 → prototype mapping function
-
: Prototype
-
: parameter of mapping function
-
: A linear layer
-
: MSE
여기에서 는 linear layer의 parameter 포함
-
3.4 Search top-k Similar users for Prediction
- Source domain으로부터 전송된 user embedding은 target domain의 cold-start user의 preference rating prediction에 사용됨 (기존 방법)
- 은 item side knowledge임
→ user embedding과 item embedding을 입력으로 받는 prediction function에 바로 사용할 수 없음 - target domain의 pre-trained user embedding 중 prototype과 유사한 top k의 user embedding을 선별하자
- : Matrix
- : Hyperparameter
- Final Prediction
3.5 Privacy Analysis
- PFCDR의 privacy 부분에서의 분석
- user-sensitive information을 일절 사용하지 않음 → Prototype
- 해커가 target user rating인 r을 알아내더라도, prototype만으로 user embedding을 알아낼 수 없음
4. Experiments
Reaserch Questions
- RQ1: PFCDR과 SOTA bridge-based model들과의 비교
- RQ2: PFCDR이 real-world에서 사용하기에 실용적인가
- RQ3: Hyperparameter에 따른 PFCDR 성능
4.1 Experimental Setup
Datasets
- Amazon review dataset
- Movie
- Music
- Book
- CDR scenario
- Book → Movie
- Book → Music
- Music → Movie
Task Settings
- Targe domain에서의 overlapping user의 rating을 randomly remove
- 나머지 user들은 prototype bridge function 학습에 사용
- 를 통해 test user의 비율을 설정 (20%, 50%, 80%)
Evaluation Metrics
- MAE
- RMSE
Baselines
- Sindle-Domain baselines
- LightGCN
- Cross-Domain baselines
- CDR with user-sensitive information
- CMF, MF, EMCDR, SSCDR, PTUPCDR
- Privacy-Preserving CDR
- FedCDR, P2FCDR, PriCDR-S, PPGenCDR
- CDR with user-sensitive information
Parameter Setting
- Pretraining Stage
- 목적: 소스·타겟 도메인 각각에 대해 latent space(임베딩)를 학습
- 옵티마이저: Adam
- 학습률: 그리드 서치 {0.001,0.005,0.01,0.02,0.1}{0.001,0.005,0.01,0.02,0.1}
- 임베딩 차원(d): 10
- 비고: 베이스라인 모델과 같은 파라미터 공간 공유
- Inversion Stage
- 목적: 소스·타겟 도메인에서 prototype 추출
- 학습 대상: 랜덤 초기화된 (item‐side weight vector)
- 손실 함수: BCE
- 옵티마이저: Adam
- 학습률: 1e-4
- 가중치 감쇠(weight decay): 1e-4
- Prototype Mapping Stage
- 목적: 브릿지 함수 학습
- 모델 구조: 1-layer MLP (fully connected)
- EMCDR, DCDCSR, SSCDR 등 기존 방식과 동일
- 최적화: MSE
- Top-k Matching Stage
- 목적: 타겟 도메인에서 와 유사도가 높은 상위 K명 사용자 검색
- 하이퍼파라미터: K
4.2 Performance Comparison (RQ1)
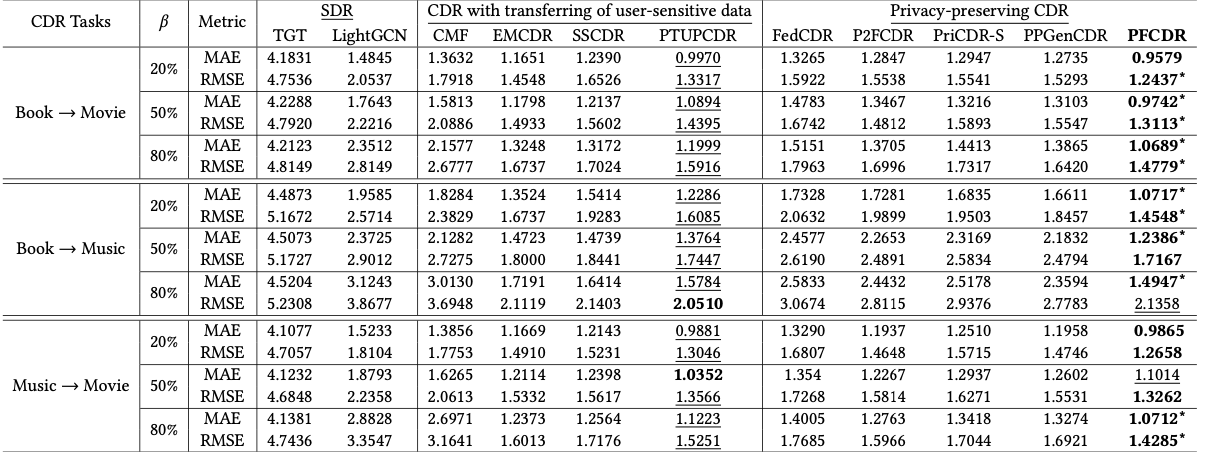
- PFCDR은 user-sensitive information없이 prototype만으로 SOTA model인 PTUPCDR을 능가함
4.3 Generalization Experiments (RQ2)
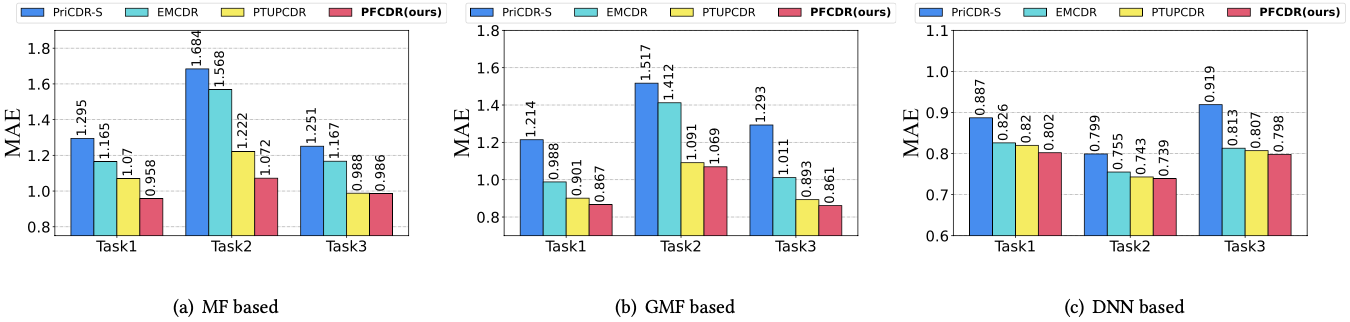
- PFCDR, PriCDR-s, PTUPCDR, EMCDR의 pre-trained model을 MF, GMF, Youtube-DNN으로 바꿔보며 실험
- PFCDR이 best performance를 달성하였으며, source domain의 정보 없이 이를 달성했다는 것이 큰 성과
4.4 Hyperparameters and Visualization (RQ3)
4.4.1 Parameter K
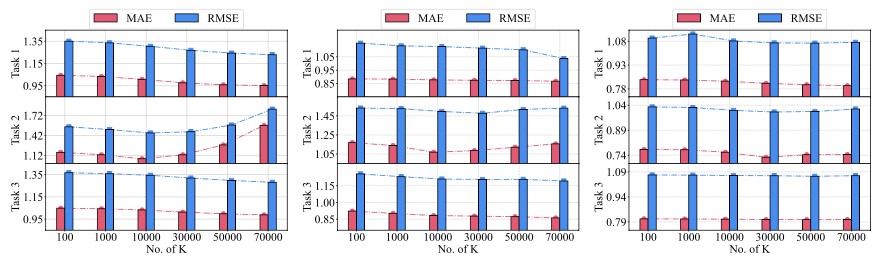
- Task 1(Book → Movie), Task 3(Music → Movie)은 K가 커질수록 성능 상승
Task 2(Book → Music)은 성능 하락
→ Task 1, 2는 domain-shared knowledge가 더 많기 때문, Task 3는 domain-shared knowledge가 적음> Book → Movie: 책을 기반으로 영화를 만듬 Music → Movie: 영화에 음악이 등장 > - K가 MF-based PFCDR에서는 영향을 많이 주고, GMF, DNN은 덜 끼침
4.4.2 Robustness under Variant Target Ratings in Inversion Stage
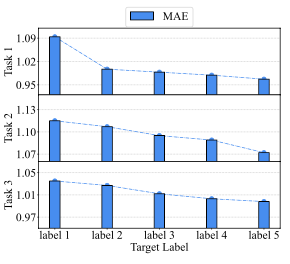
- PFCDR은 conditioned model inversion을 위해 target rating을 설정할 수 있음 → 해당 rating이 나올 거 같은 아이템들의 조합
5. Conclusion
- PFCDR은 user-sensitive information의 transfer없이 유의미한 성과를 냈음
- 저자들은 이를 위해 continuous한 new data format으로 prototype을 정의했으며, 이를 이용한 bridge function도 설계하여 domain shift도 해결
- cold-start scenario에서도 효과적임을 입증
My Opinion
- PFCDR은 논문의 시작부터 끝까지 체계적이며, 논리적으로 잘 풀어냈다고 생각
- 꼼꼼하게 저자의 문제제기와 해결방법을 잘 정의를 하였고, 어떻게 적용을 했는지까지 읽으면서 아주 잘 짜여있다고 생각
- 초반부에는 model inversion을 이용한 prototype이 과연 해당 user의 preference를 진정으로 의미하는가 생각이 들었지만, 실험결과를 보고 의미있구나 생각이 들었음
- PFCDR은 “What to transfer”, “How to transfer”, “Who to transfer” 카테고리 중 “What, How to transfer”에 중점을 둔 모델이며, S2S 모델, Domain bridge로 overlapping user를 사용하였음
- 보안이라는 제약조건으로 인해 original user data를 사용하지 않았지만, 사용할 수 있다면 item 시점에서 얻은 prototype과 user 시점에서 얻은 user embedding, 두 임베딩을 보정해서 차이를 줄인다면?
→ 좀 더 확실한 user preference를 얻을 수 있을 거 같다!
