RAG(검색 증강 생성)
RAG (Retrieval-Augmented Generation)는 Vector Database와 LLM을 결합하여 검색된 데이터를 활용해 문맥 기반 응답을 생성하는 기술이다.
작동 원리
검색 : 사용자의 질문을 벡터화해 관련 데이터를 Vector DB에서 검색
생성 : 검색된 데이터를 바탕으로 LLM이 자연어 응답 생성
구성 요소
- Vector DB
- LLM
- 검색 엔진
장점
- 최신 정보 제공
- 정확성 향상
- 유연성
한계
- 데이터 품질 의존성 : 검색된 데이터가 부정확하면 생성된 응답도 부장확
- 속도 문제 : 검색과 생성 단계를 거치므로 반응속도가 느려질수 있음
활용 사례
- 고객 지원 시스템
- 학습 자료 기반 지의응답
- 의료 분야 최신 데이터 제공
- 문맥 기반 검색 엔진
RAG구조(VectorDB와LLM결합)
VectorDB와 LLM을 결합해 검색된 데이터를 바ㅏㅇ으로 문맥 기반 응답 생성 기술 / 유사도 검색과 자연어 생성 단꼐 포함/ 최신 정보 활용과 정확한 응답 제공에 유리
- 작동 원리
- 벡터화: 텍스트 데이터를 임베딩 벡터로 변환해 Vector DB에 저장
- 유사도 검색: 사용자의 질문을 벡터로 변환해 관련 데이터를 검색
- 응답 생성: 검색된 데이터를 컨텍스트로 사용해 LLM이 자연어 응답 생성
RAG 성능 최적화 기법
검색 성능 향상 기법
검색 성능은 데이터 전처리, 임베딩 모델 선택, 검색 전략 등에 따라 크게 좌우된다. 효과적인 검색을 위해 다음과 같은 최적화 기법을 사용할 수 있다
1. CHUNKING 전략 : 문서를 일정 크기의 단위로 나누어 벡터롸(검색 정확도 향상)
2. Embedding 모델 선택 :
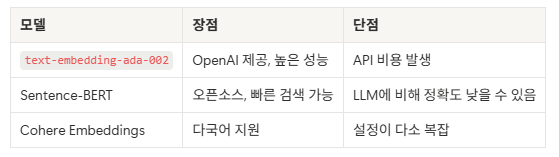
- Retrieval 전략
- Top-K 검색: 관련성이 높은 상위
K개의 문서를 검색 한다. (일반적으로K=3~5) - Re-ranking 기법: 검색된 문서들을 다시 정렬하여 가장 관련성이 높은 문서만 활용한다.
- Hybrid Search: 벡터 검색 + 전통적인 키워드 검색 조합을 사용하는 전략이다.
RAG 문제점과 최적화
- 속도 문제 해결
- 캐싱활용
- 사전연산
- 데이터 품질 문제 해결
- 데이터 정제
- 지식 그래프 연동

공부하는거 정리하는 블로그