llm
1.자연어

분류 : 감정분석, 스팸메일, 유형분류검색 / 추천 : Q&A, 유사문서 찾기 검색정보추출 : 개체 뽑기요약/번역/대화(멀티미디어(음성, 이미지)) -> 텍스트 -> 전처리(토큰화, 벡터화)-> 모델 학습 -> 성능 평가언어 이해 → 언어 변환언어별 어순 차이, 그 언
2.자연어 처리
전처리 모델의 성능과 학습 속도에 큰 영향을 미침 일관성 있는 데이터 형식을 제공해 모델이 효율적으로 학습 가능 > 어휘 크기 (vocab), oov -> 학습 안정성 maxdf, mindf => 과하게 정보를 지우면 필요한 정보도 같이 사라질수있다 ex : 히히히/ㅋ
3.자연어 데이터 준비
Bow : 각 단어의 출현 빈도를 벡터로 표현TF-IDF : 단어의 중요도 평가N-gram : 연속된 N개의 단어를 묶어서 분석단어 빈도 : 특정 단어가 얼마나 자주 등장하는지문장 길이 : 각 문장의 단어 수고유 단어 수 : 텍스트에서 중복되지 않는 단어의 수사전에 정
4.서브워드 토크나이저
자연어 처리(NLP)에서 하나의 단어를 더 작은 의미 단위인 부분 단어로 분절하는 방식딥러닝 모델은 문자열을 그대로 연산 불가능 따라서 텍스트를 모델에 넣기 위해서는 문자열 -> 토큰 -> 정수ID시퀸스 -> (임베딩) 실수 벡터로 바꿔야함유사도 학습(비슷한 단어/문장
5.자연어 임베딩
자연러 임베딩이란 단어를 고정된 크기의 실수 벡터로 표현하는 방법 즉, 텍스트 데이터를 수치 데이터(벡터)로 변환하여 컴퓨터가 처리할 수 있도록 만드는 기술 자연어 임베딩의 역할 단어/문장 간 관련도 계산 단어 또는 문장을 벡터로 표현하여 벡터 간의 코사인 유사도,
6.자연어 딥러닝(RNN)
텍스트 -> 토큰화(사전) -> ID 시퀀스 -> 임베딩 -> 모델(transfomer 등)-> 출력Speech recognition: 파동의 연속 → 단어의 연속으로 변환 음성 → 문자/단어 (시퀀스 → 시퀀스)Music generation : 연속된 음표 출력
7.자연어 처리(GRU)
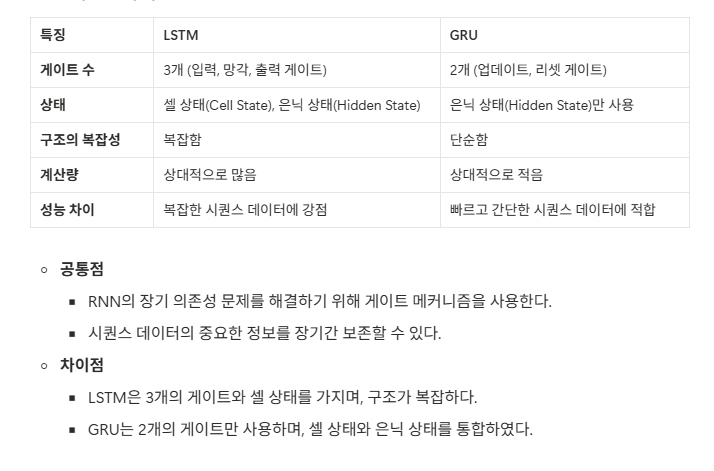
RNN의 변형 구조중 하나로 lstm이랑 유사라지만 게이트 수를 줄여 구조가 더 간단lstm은 3가지 게이트를 사용하는 대신 GRU는 업데이트 게이트/ 리셋 게이트의 2가지만 사용구조가 단순하기 떄문에 계산량이 적고 학습 속도가 더 빠르다과거 정보를 얼마나 잊을지 결정
8.자연어 기초 (텍스트 분류)
단어 간 독립성을 가정해 확률적으로 텍스트 분류이 문서는 어떤 클래스 (주제/감정/스팸) 일 확률이 가장 큰가시퀸스 데이터를입력받아 텍스트분류 작업을 수행장점 : 텍스트의 수너소아 문맥 정보를 효과적 반영 / 가변적 시퀸스 처리 용이 / 감성 분석, 기계 번역 등에서
9.RNN 추가
순서가 중요한 데이터(문장, 시계열)을 한 칸씩 순서대로 읽으면서 처리하는 신경망읽는 동안 지금까지 읽은 내용을 은닉상태(h)라는 메모에 꼐속 업데이트입력을 한번에 다 보는것이 아닌 순서대로 읽고 메모 갱신RNN은 시간(step)이 바뀌어도 같은 가중치를 반복단어가 1
10.IMDB감성분류 과정(LSTM)
리뷰 텍스트와 라벨(긍정=1, 부정=0)을 가져옴텍스트를 전처리(소문자화/정규식 처리 등)단어 사전(VOCAB)을 만들고각 리뷰를 단어 -> 정수 시퀸스로 바꿈)"i loved this movie" → 10, 532, 21, 88리뷰 길이가 제각각이라 모델 입력이 불편
11.MDB감성분류 과정(GRU)
리뷰 텍스트와 라벨(긍정=1, 부정=0)을 가져옴텍스트 전처리(소문자화/정규식 처리 등)단어 사전(VOCAB) 만들고 각 리뷰를 단어 -> 정수 시퀀스로 바꿈"i loved this movie" → 10, 532, 21, 88리뷰 길이가 제각각이라 모델 입력이 불편최대
12.Seq2Seq
번역 과정 영어 문장(Encoder 입력)을 넣음 LSTM 인코더가(h,c)를 요약상태를 만듦 디코더가 `` 부터 시해 한 토큰씩 한국어를 생성 ``가 나오면 멈추는 Seq2Seq 번역기를 학습/추론까지 구현 학습 데이터 준비 개념 설명 데이터는 manythings.
13.전이학습
Transformer 인코더를 기반으로 한 모델로, 양방향 문맥을 학습해 단어의 앞뒤 의미를 모두 이해양방향 문맥 학습 : 앞뒤 문맥을 모두 반영해 단어 의미 이해학습 방법MLMNSPCLS 문장의 대표 벡터SEP 문장 구분/끝 표시CLS 문장 A SEP 문장 B SEP
14.LLM 기초
Chat GPT : 범용성Claude : 긴 문서Copilot : 마이크로소프트 프로그램과 함께 쓰기에 좋다Perplexity : 과제/리서치/논문Grammarly : 영어 업무Jasper / Copy.ai : 마케팅 업무Copilot은 범용 실무 최강,Cursor는
15.벡터 데이터베이스
벡터 형식으로 저장된 데이터를 관리하고 유사도 기반 검색 및 작업을 최적화 하도록 설계된 데이터베이스이다 AI/ML, 자연어 처리(NLP), 이미지 검색, 추천 시스템에서 주로 사용 / 최근접 이웃 검색(ANN)기법 활용특징벡터 임베딩 저장 : 데이터를 벡터로 변환해
16.프롬프트 엔지니어링 응용
LangChain은 LLM의 기능을 확장하고 체계화하여 복잡한 애플리케이션을 구축할 수 있도록 지원하는 프레임워크검색 -> 정리 -> 추론 -> 출력 => 파이프라인 체인, 에이전트, 메모리들의 기능 제공\-> 벡터DB, LLM, 툴 => 연결(플로그인 형태)체인 구성
17.RAG
RAG (Retrieval-Augmented Generation)는 Vector Database와 LLM을 결합하여 검색된 데이터를 활용해 문맥 기반 응답을 생성하는 기술이다.검색 : 사용자의 질문을 벡터화해 관련 데이터를 Vector DB에서 검색생성 : 검색된 데이
18.검색 품질 기법
BM25 Retrieval (키워드 검색)Dense Retrieval (임베딩 기반 벡터 검색)RRF (BM25 + Dense 결과 결합)HyDE (질문 → 가상 문서 생성 → 검색)Cohere Re-ranking (후보를 뽑은 뒤 정렬만 다시)문서를 "의미"로 보지
19.KERAS
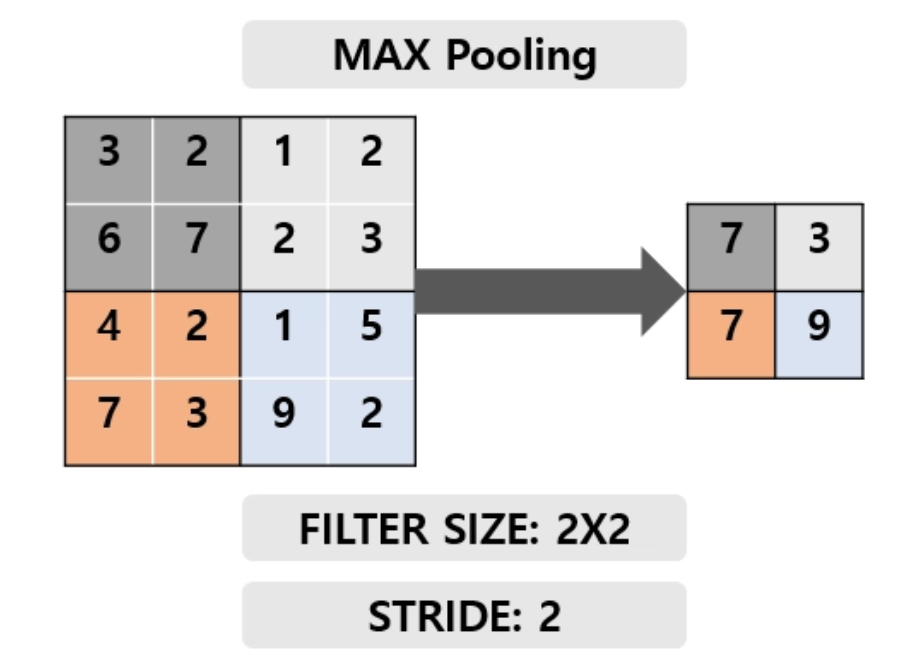
파이썬으로 구현된 딥러닝 모델 구축을 위한 고수준의 신경망API사용자 친화적 : 직관적인 API를 제공하여 모델을 쉽게 구축모듈성 : 다양한 레이어, 활성화 함수, 손실함수를 조합하여 모델 구성 가능확장성 : 새로운 모듈을 쉽게 추가하여 기능 확장 가능활성화 함수분류문
20.vllm 공부
vLLM은 대규모 언어모델(LLM)을 빠르고 효율적으로 서비스 형태로 실행하기 위한 추론·서빙 엔진이다. 단순히 모델 파일을 실행하는 도구가 아니라, 여러 사용자의 요청을 받아 안정적으로 처리할 수 있도록 설계된 LLM 서버 프레임워크에 가깝다. 공식 문서에 따르면 v