GRU란
RNN의 변형 구조중 하나로 lstm이랑 유사라지만 게이트 수를 줄여 구조가 더 간단
- lstm은 3가지 게이트를 사용하는 대신 GRU는 업데이트 게이트/ 리셋 게이트의 2가지만 사용
- 구조가 단순하기 떄문에 계산량이 적고 학습 속도가 더 빠르다
리셋 게이트
- 과거 정보를 얼마나 잊을지 결정
- 이전 은닉 상태가 현재 입력에 얼마나 반영될지 제아
rt = \sigma(W_r \cdot [h{t-1}, x_t] + b_r) (b는 편향 -> 으로 갈수록 리셋 안함(기억 유지))
은닉 상태 업데이트
- 새로운 은닉 상태는 리셋게이트를 적용한 이전 은닉 상태와 현재 입력 정보를 결합하여 제어
\tilde{h}t = \tanh(W_h \cdot [r_t \cdot h{t-1}, x_t] + b_h)
업데이트 게이트
- 정보의 기억 여부 결정
zt = \sigma(W_z \cdot [h{t-1}, x_t] + b_z)
최종 은닉 상태
- 이전 은닉 상태와 새로운 은늑 상태를 조합하여 최종 은닉 상태 계산
ht = (1 - z_t) \cdot h{t-1} + z_t \cdot \tilde{h}_t
(z는 0에 가까울수록 기존 기억 유지)
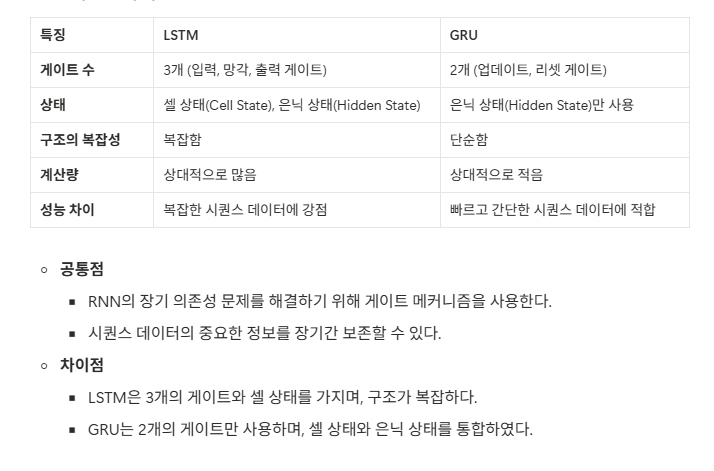
LSTM과 GRU 비교
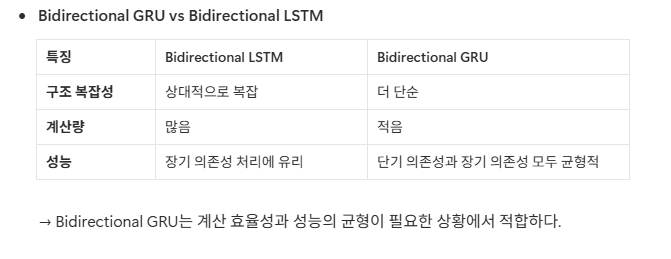
[참고] Bidirectional GRU
양방향 변형 모델로, 데이터를 순방향(Forward)과 역방향(Backward)으로 동시에 처리하여 더 풍부한 정보를 학습
양방향 정보 학습
순방향 GRU: 문장을 왼쪽 → 오른쪽으로 읽음
- “앞에서 나온 내용(과거)”을 기억하면서 지금 단어를 해석
역방향 GRU: 문장을 오른쪽 → 왼쪽으로 읽음
- “뒤에서 나올 내용(미래)”을 미리 알고 지금 단어를 해석
양방향(BiGRU)는 “한 방향 GRU”보다 두 번 돌리므로 연산이 늘어남(순방향+역방향).
그럼에도 “양방향 LSTM”과 비교하면, GRU가 구조가 단순한 편이라 상대적으로 가볍다는 뜻
한계
- 추론 시 제한: 학습 시 전체 시퀀스를 참조하지만, 실시간 추론 환경에서는 이후 데이터를 사용할 수 없어 제한적
- 메모리 사용량 증가: 양방향 처리로 인해 메모리 사용량과 연산량이 단일 GRU보다 많음

공부하는거 정리하는 블로그