어제까지 어찌저찌 Service layer 까지는 작성을 마쳤다. 강의와 프로세스를 맞추기 위해 양식은 거의 다 맞췄지만 구조적인 부분은 이해를 한 상태고 진행하는 방식에서 생기는 의문점은 전부 짚어가며 공부하고 있으니 부작용은 크게 없을 거라고 생각한다.
이거 적으면서 강의를 보며 반례라던가 궁금한 부분을 챗봇까지 겸해서 머리에 꾹꾹 담다보니 진행 속도가 정말 느리다. 배우는 느낌은 확실하게 드는데 새삼 제로베이스로 부트캠프에 왔다면 대체 이 강의를 어떻게 보고 있었을까 생각이 들기도 했다.
DB와 Repository 작성하기
DB는 그래도 꼬박꼬박 볼 일도 생기고 문제로 풀 일도 생기는지라 아주 기초적인 부분은 이해하고 넘어갔다. 그래도 백엔드고 명령어를 치기보단 GUI를 애호했던 만큼 복습하는 느낌으로 열심히 지켜봤다.
사실 공부보다 가장 궁금한 점은 요즘 AI 챗봇이 그렇게 스키마도 잘 짜고 SQL도 잘 한다던데.. 하는 생각인 것 같다. 직접 써보고 싶다.
Repository, Entity
- Repository 작성을 마치면 Service 에서 주입 받는다
- @Column에 nullable 속성은 Table을 JPA에서 만들 거 아니면 딱히 필요 없다.
- @Enumerated(EnumType.STRING) 을 지정하면 Enum 의 이름으로 DB에 저장한다.
- Id는 Entity의 생성자에서 필요하지 않기 때문에 블럭 내부에서 지정을 하면 좋다.
- Id는 Nullable이 아닌데 Optional 표기를 해준 이유는 어차피 DB에 @GeneratedValue(GenerationType.IDENTITY) 로 자동 생성하게 위임을 해주기 때문이다.
- @Embeddable, @Embedded 어노테이션이 있는데 모델이 다른 도메인에 종속될 때 세트로 쓰면 되고 Embeddable 클래스는 data class로 작성해도 된다.
- Value Object를 정의한 거고 엔티티의 속성으로 사용할 수 있게 됨.
- Embedded 어노테이션으로 JPA가 얘는 Entity의 속성으로 쓰는 값 객체로 여겨서 영속성을 부여함
- 엔티티 클래스를 가볍게 만들고 도메인을 표현하기 쉬워짐
- 강의에서 Domain 정의할 때 Id 코드가 계속 중복되는데 이걸 방지하기 위해 @MappedSuperclass 어노테이션을 사용해서 기본 Entity를 만들고 상속받을 수 있는데 강의에선 다루지 않음
- Join 으로 관계 표현하는 걸 코드에선 그냥 변수로 선언하냐 마냐로 객체지향적으로 구분지을 수 있음 (어노테이션도 써서)
- mappedBy를 항상 표시해주는게 좋은데 FK를 누가 소유하고 있는지를 표기해주는 것, 소유하고 있지 않은 쪽에 표기를 해주는 경우가 많음
- 강의로 보면 Course - Lecture는 1:n 이고 Course Entity에서 lectures를 가지고 있고 이 Lecture는 course_id 를 들고 있으므로 연관관계의 주인
- 1:n 이면 FK는 n에 있고 mappedBy는 1로 간다고 보면 됨
- 강의로 보면 Course - Lecture는 1:n 이고 Course Entity에서 lectures를 가지고 있고 이 Lecture는 course_id 를 들고 있으므로 연관관계의 주인
- @JoinColumn 으로 FK 이름을 명시적으로 할 수 있음
- 지연 로딩, 즉시 로딩은 관계 설정쪽에서 fetch를 설정하고 LAZY, EAGER 를 설정하면 됨
- 거의 LAZY로 쓰지만 거의 항상 붙어다녀서 계속 조회 해야하면 그냥 EAGER를 씀
DB
- 강의에선 빠른 테스트를 위해 Firestore 처럼 클라우드 DB지만 PostgreSQL을 사용하는 RDBMS인 Supabase를 씀 (UI 제공도 해주고 500MB까지 무료라 프로토타이핑에 적합함)
- BIGSERIAL 은 BIGINT 값이고 1로 시작해서 계속 증가처리돼서 Index에 적합 (MySQL의 AUTO_INCREMENT)
- IntelliJ도 DB 연결을 잘 지원한다.
- Gradle 종속성을 추가할 때 runtimeOnly를 써서 Application 실행 시에만 추가한다. (App이 실행될 때 DB가 드라이버로 한 번 붙어주기만 하면 되기 때문)
- src/resources/application.properties 에서 DB 연결 설정을 해줘야 한다.
- application.yml 로 작성할 수도 있다.
- Secrets를 숨기기 위해 Run Configurations - Run Options 에서 Environment variables를 쓸 수 있다.
- Spring 에서 기본 환경변수로 SPRING_DATASOURCE_URL 을 제공해주고 설정하면 yml도 필요가 없다. (properties or yml로 쓰던 값을 실행 환경변수로 주입)
- Github Actions에서 쓰려고 시도했던 Workflow yml도 이런식으로 Github Secrets 에서 환경변수를 읽어오려고 했다고 이해할 수 있다.
- 그냥 IDE를 쓰는게 편할 뿐 Export SPRING_DATASOURCE_URL={} 같은 식으로 작성해도 같은 방식이다.
- Spring 에서 기본 환경변수로 SPRING_DATASOURCE_URL 을 제공해주고 설정하면 yml도 필요가 없다. (properties or yml로 쓰던 값을 실행 환경변수로 주입)
SQL
- DDL, DML, DCL은 얼추 알고 TCL(Transaction Control Language) 으로 Transaction을 제어하는데 Service에서 사용한 @Transactional 어노테이션을 건게 TCL로 변환된다고 이해할 수 있다.
- 직접 TCL을 작성할 일은 딱히 없다.
- Create Table 제약조건 NOT NULL, UNIQUE, PRIMARY KEY, FOREIGN KEY
- FK를 통한 관계를 크게 나누면 1:1, 1:N, N:M 으로 구분 가능하다.
- 1:1의 경우 User 하나당 Profile 하나 있는 것 같은 관계다.
- 1:N의 경우 Post 하나에 Comment 여러 개 있는 것 같은 관계다.
- N:M의 경우 User, GroupMember, Group 테이블 세개가 있고 GroupMember 에서 user_id, group_id를 맵핑하면 그룹에 유저가 많든 유저에 그룹이 많든 상관 없이 표현 가능하다.
- User-GroupMember 1:N, Group-GroupMember 1:N을 합쳐 User-Group을 N:M이라고 표현한다.
- FK는 받는 쪽에서 정의한다.
- ORM을 쓰면 편하지만 테이블 생성은 스키마가 예상과 달라질 수 있으니 SQL에서 생성하는걸 권장한다.
JPA
Java Persistence API
얘는 개념적으로 아예 몰라서 완전 새로 배우는 ORM이니 따로 남기기로 했다.
ORM 개념 자체는 들어봤는데 어디서 들어봤나 했더니 Realm을 쓰느라 알았던 것 같다. 그런데 Realm을 어디다가 썼었는지 기억이 안나는데 굉장히 소규모로 쓸려고 대충 Library로 집어왔던 것 같다. 너무 조금 써봐서 잘 기억도 안나니 JPA 공부에 힘쓰기로 했다.
- Application 코드 그대로 DB를 다룰 수 있어 생산성이 좋아짐
- DB를 바꿔도 코드를 수정만 수정하면 대응이 가능함 DB에 대해 독립적임
- 단점으로 러닝 커브가 있고 복잡한 조건을 짜는 데에는 SQL을 직접 작성하는게 쉬움
같이 등장하는 주변 단어들
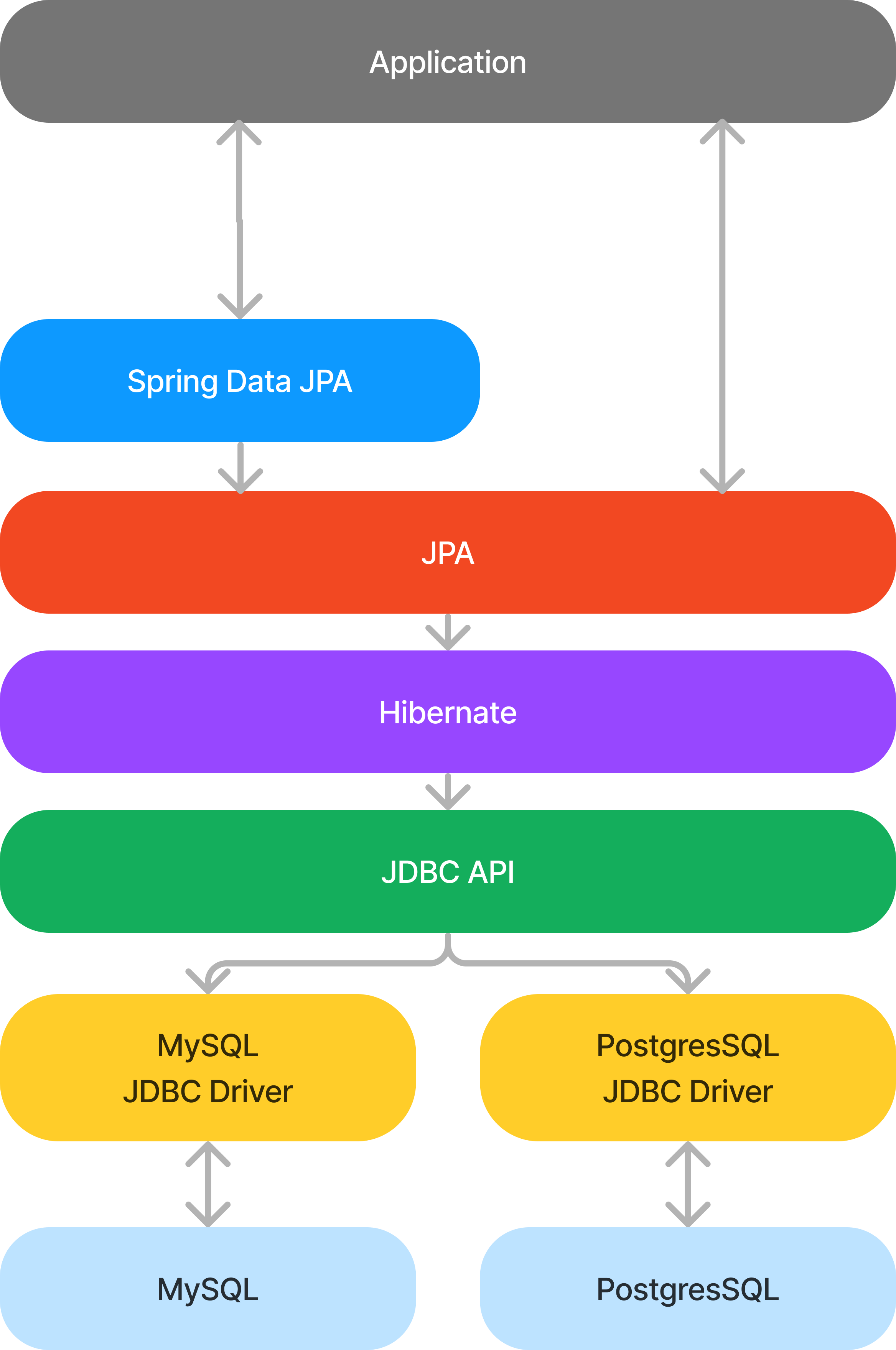
- JDBC
- DB url 설정할 때 주소 맨 앞에 있던 키워드로 제일 하위에서 DB에 접근해서 SQL을 사용할 수 있게 해줌
- JDBC API는 하나의 인터페이스고 JDBC Driver는 DB별 구현체라 Driver만 바꾸면 DB를 바꾸기 수월함
- Hibernate
- JPA의 구현체, 여러 구현체가 있지만 가장 성숙도가 높아 최근엔 가장 많이 씀
- EclipseLink, OpenJPA 같은 다른 구현체도 있고 이런 걸 JPA Provider 라고 부름
- JPA
- 이것도 하나의 인터페이스, JDBC API를 내부적으로 사용하고 SQL을 다루는 느낌보다 객체지향적으로 다룰 수 있게 함
- Spring Data JPA
- JPA는 그냥 JDBC를 다루는 인터페이스일 뿐이라 Spring 에서 추가로 개발한 게 Spring Data JPA임
- Repository 인터페이스는 얘가 제공하는 것, 얘 구현체가 JPA를 호출함
- 주로 이걸 다루고 다른 기능이 필요하면 JPA도 쓰게 될거임
- @Entity 어노테이션을 사용해서 Bean 처럼 JPA에서 관리하는 객체로 만듬
- Name이 일치하면 자동으로 맵핑해주긴 하는데 명시적으로 맵핑해주는 것도 좋음
- @Id, @GeneratedValue, @OneToMany, @ManyToOne 같은 어노테이션이 있음
- GeneratedValue 는 그냥 BIGSERIAL 처럼 자동 생성되는 값을 지정 가능
- 1:N, N:1 을 인식시켜주는 @OneToMany 같은것도 있으니 그냥 알아두기
Persistence Context (영속성 컨텍스트)
영속성 관리해주는 매니저같은 느낌이다 (사실 영속성 Entity를 전문적으로 관리하는 EntityManager는 일단 따로 존재함, 약간 하위 일꾼같은 느낌)
- 영속성을 관리하기 위한 개념, Application 에 변수를 저장하고 실행후 종료하면 메모리의 해당 데이터는 모두 사라질 뿐이지만 DB에 저장하면 영속성을 부여한다고 생각할 수 있음
- 어쨌든 영속성(Persistence)은 데이터를 영구적으로 저장하고 관리하는 개념이고 반대에 휘발성이 있다고 생각하면 됨
- Entity가 영속성 Context에 포함되면 DB에 변경사항을 저장하여 영속성을 부여한다 라고도 표현 가능
- 영속성을 관리하는 Context에 그냥 모든 Entity를 담으면 메모리 부하가 커지고 매니저가 계속 Entity의 변경사항을 추적해야 하므로 영속, 비영속을 구분하는 것
- 그리고 Transaction 을 처리할 때 반영되야 하는 정보를 확실히 구분할 수 있고 관리도 쉬워짐
- 매니저가 트랜잭션을 시작하고 그 사이에서 Entity의 영속성만 관리하다가 커밋했을 때 영속성 컨텍스트가 JPA를 통해서 쿼리 처리를 한다고 볼 수 있다
- 트랜잭션을 안쓰는 GET이라고 무조건 비영속인건 아니고 매니저가 Entity를 조회해서 반환하면서 자기 1차 캐시에도 저장하고 있어서 같은 Entity를 조회하면 그걸 뱉어주고 이렇게 매니저한테 한 번 이상 관리된 적 있으면 준영속 상태라고 부름 (한번도 없으면 비영속)
영속성 컨텍스트가 관리하는 Entity의 상태
- Transient(New)
- 아직 영속성 컨텍스트에 포함되지 않은 Entity 상태
- Managed
- 영속성 컨텍스트에 저장한 상태
- Detached
- 영속성 컨텍스트에 있었다가 분리된 상태
- Removed
- 삭제된 상태
- 결국 커밋할 때 Managed, Removed를 보고 어떤 Entity를 추가, 수정, 삭제를 할지 JPA에서 구분한다
- 캐싱은 ORM의 기능이고 DB 조회를 줄여서 네트워킹 효율을 높이는 느낌임
지연 로딩, 즉시 로딩
- 연관된 Entity가 실제로 필요한 시점에 DB에서 불러오는게 지연 로딩, 연관된 Entity를 즉시 불러오는 게 즉시 로딩
- 이 관련은 FK라 생각하고 게시글과 댓글이 있다 치면 게시글 불러올 때 그 게시글의 댓글을 미리 다 불러올지 필요할 때 불러올지 판단하는 거임
- JPA가 언제 쿼리를 DB에 날릴지 시점을 코드로 결정 내려준다고 생각하면 됨
- 지연 로딩일때 그럼 Entity에 뭘 저장하냐면 Proxy 객체라고 가상의 값을 넣어줌
트랜잭션
- Spring 내부에 있는 SQL 저장소에 쿼리를 전부 저장만 해두고 있다가 쭉 보내는게 트랜잭션 커밋임
- Commit 종료 시점 이전에 동기화를 하는 걸 Flush 라고 하고 이 때는 Rollback이 가능함, Commit 끝나면 못함
- Flush는 어떤 쿼리를 보낼지 판단하는 과정이라 생각하면 된다
- Flush 가 어떻게 쿼리 보낼지 판단하려고 Entity의 변경 사항을 추적하는 과정을 Dirty Checking 이라고 함
post.title 이 변경됐으니까 update 쿼리를 실행해야겠구나!를 판단해줌- Dirty checking이 없으면 불필요한 Update query가 실행될거고 성능 최적화가 안될거임
Entity Manager
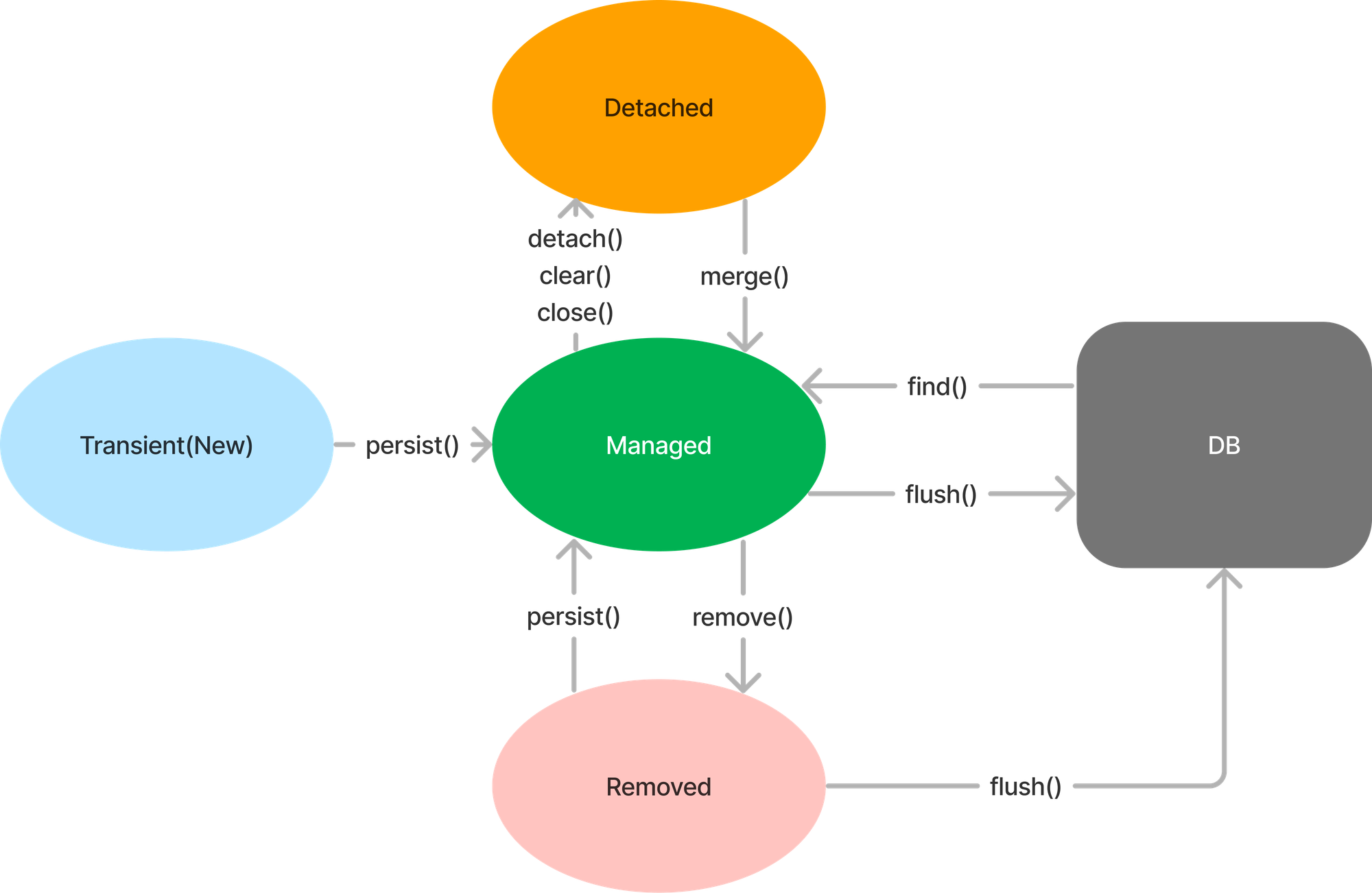
- 사실 영속성 컨텍스트 밑에서 Entity 관리하는 주체가 Entity manager임
- 위에서 배운 Entity 상태를 변경하는 함수를 제공해줘서 영속성 관리하라고 있는거임
- 제공해주는 함수 (위 Entity 상태 추적을 잘 떠올릴 것)
- persist(): Entity를 영속성 컨텍스트에 추가함
- merge(): Detached 상태(준영속) Entity를 다시 영속성 컨텍스트에 추가함
- remove(): Entity를 삭제함
- detach(): 영속성 컨텍스트에서 Entity를 분리하여 Detached 상태(준영속)로 만듬
- clear(): 영속성 컨텍스트를 초기화하여 모든 Entity를 Detached 상태(준영속)로 만듬
- close(): EntityManger를 종료함
- flush(): 영속성 컨텍스트 내에서 변경된 Entity를 감지하여 데이터베이스와 동기화 (Commit 이전에 쿼리를 DB에 전달하는 단계)
- find(): 주어진 Entity의 PK를 이용해서 Entity를 데이터베이스에서 조회하여 영속성 컨텍스트에 추가함
- 이렇게 세부적으로 Entity 상태를 관리해주는 게 가능하긴 하지만 어려우니까 Spring Data JPA 에서 제공해주는 Repository를 쓰는 거임
Repository (Spring Data JPA 인터페이스)
- Repository는 기본적인 인터페이스고 얘를 상속받은 CrudRepository, PagingAndSortingRepository, JPARepository 를 제공한다.
- 순서대로 상속받아가며 확장한 거라 기능이 가장 많을 JPARepository를 사용하면 편하다.
- JPA Repository를 상속받을 때 Entity와 PK의 타입을 지정해야한다.
- 이거 쓰면 EntityManager 사용을 최소화 할 수 있다.
코드카타 - 프로그래머스 과일 장수
과일 장수가 사과 상자를 포장하고 있습니다. 사과는 상태에 따라 1점부터 k점까지의 점수로 분류하며, k점이 최상품의 사과이고 1점이 최하품의 사과입니다. 사과 한 상자의 가격은 다음과 같이 결정됩니다.
- 한 상자에 사과를 m개씩 담아 포장합니다.
- 상자에 담긴 사과 중 가장 낮은 점수가 p (1 ≤ p ≤ k)점인 경우, 사과 한 상자의 가격은 p * m 입니다.
과일 장수가 가능한 많은 사과를 팔았을 때, 얻을 수 있는 최대 이익을 계산하고자 합니다.(사과는 상자 단위로만 판매하며, 남는 사과는 버립니다)
예를 들어, k = 3, m = 4, 사과 7개의 점수가 [1, 2, 3, 1, 2, 3, 1]이라면, 다음과 같이 [2, 3, 2, 3]으로 구성된 사과 상자 1개를 만들어 판매하여 최대 이익을 얻을 수 있습니다.
- (최저 사과 점수) x (한 상자에 담긴 사과 개수) x (상자의 개수) = 2 x 4 x 1 = 8
사과의 최대 점수 k, 한 상자에 들어가는 사과의 수 m, 사과들의 점수 score가 주어졌을 때, 과일 장수가 얻을 수 있는 최대 이익을 return하는 solution 함수를 완성해주세요.
fun solution(k: Int, m: Int, score: IntArray): Int = score.sortedDescending()
.subList(0, (score.size - score.size % m))
.chunked(m)
.map {
it.minOrNull()!! * it.count()
}.sum()문제가 원하는 정답 유형이 아닌 걸 확실히 알았지만 대책을 못찾아서 결국 이대로 제출하고 말았다.
일단 문제가 많은 알고리즘인거는 주어진 최대 값 k를 안쓰는 순간 확실히 알았고 문제 제한 조건의 score size가 최대 1,000,000 인 것도 확인했다.
그러면 k를 가지고, 특히 최대 값을 줬다는 건 뭔가 정렬 없이 풀 수 있는 수식이 존재할 거라고 생각해서 숫자를 정렬하지 않고 나열해서 계속 확인했는데 도저히 예제의 답을 도출할 방법을 쉽게 떠올리지 못해서 이대로 제출했다.
단순 가독성을 따지면 만족스럽지만 아마 score size를 엄청 높게 잡았을 11 ~ 15번 테스트 케이스에서 100~200ms 가 나오는 걸 보고 역시 쉬운 방법은 존재함을 알았고 원하는 방향으로 못풀었으니 열심히 물고 뜯어보기로 했다.
질문하기, 다른 사람들의 풀이를 확인해보며 느낀 건 다들 비슷한 고민을 했고 대부분 k를 사용하지 않고 정렬을 이용한 가장 명확한 방법으로 작성한 경우가 많다는 것이었다.
반대로 정렬 없이 풀 수 있는 방법을 해결해서 score size를 최대 10,000,000 으로 늘려서 진행해도 좋았을 것 같은 문제라는 의견을 보고 이 해결 능력이 어렵긴 하구나를 다시 한 번 느낄 수 있었다.
그리고 정렬을 썼더래도 Kotlin 스럽게 작성한 내용중 내가 쓴 subList, chunked 말고도 좋은 방법이 있었다.
(m - 1 until score.size step m).fold(0) { acc, i -> acc + sorted[i] * m }step을 사용하고 fold로 값을 더하니 순회 횟수를 2번 줄여낼 수 있었을 텐데 차라리 k 안쓰고 제출할 거면 이렇게라도 할 걸 싶었다.
fun solution2(k: Int, m: Int, score: IntArray): Int {
var answer: Int = 0
val apple = Array<Int>(k) {0}
for(s in score) {
apple[s-1] += 1
}
for(i in k-1 downTo 0) {
if(apple[i] % m != 0 && i > 0) {
val down = apple[i] % m
apple[i] -= down
apple[i-1] += down
}
answer += (apple[i] / m) * (i+1) * m
}
return answer
}먼저 정렬없이 그냥 score 를 순회해서 사과 점수별 개수를 더해놓고 (점수 3이라면 apple[2]의 개수를 1 증가시킨다)
높은 점수부터 순회를 시작해서 높은 점수의 사과가 정확히 m만큼 나누어 떨어지지 않으면 먼저 남는 개수의 사과만큼 빼고 밑 점수 사과의 Count를 증가시키는 로직을 채용했고 최종적으로 상자의 개수(apple[i] / m) * 사과의 이익(i+1) * m 으로 합계를 구했다.
수많은 상자를 배열로 저장하는 기존 방식과 달리 한 번의 순회에서 점수별 사과 개수만 카운팅하고 적은 순회로 계산하므로 훨씬 효율 좋은 코드가 됐다.
100~200ms가 나오던 테스트 케이스에서도 10~15ms 로 줄어서 대폭 감소했고 나는 내장 함수의 편의성적인 측면에서만 접근하니 알고리즘의 효율이 굉장히 떨어진 것 같다.
최대 1,000,000의 사이즈에 정렬을 쓰는 순간 각오는 했지만 해결법을 보고 크게 공부가 됐다.
