주말에 추가로 과제 작성을 진행해서 어찌저찌 과제 데드라인은 맞췄다. 고민을 많이 하긴 했지만 고민의 해답은 챗봇에 의존을 많이 해서 자아의탁까진 아니어도 정말 올바른 길인지는 레퍼런스를 엄청 많이 살펴보진 않아서 확신을 가지고 있진 않다.
그래도 코드 자체는 내가 이해 가능한 영역에서 짜낸거라 아마 모르는 키워드가 있지 않고서야 아는 선에서는 최대한 고민해본 흔적이라고 생각하기로 했다.
그 중에서도 챗봇도 아니고 대부분 튜터님을 따라한게 OAuth 인증인데 이거는 원래 구조 참고만 하려고 튜터님이 공유해주신 Repository를 보니 구현체까지 다 등록되어 있어서 구조 이해를 하면서 따라짜니 그냥 사실상 클론코딩이 됐다. Enum을 적절히 활용해서 코드의 중복이 확연히 줄어들어 이전에 제출했던 과제보다 훨씬 마음에 들었다.
과제 해설 세션
한 튜터님이 라이브 코딩으로 진행한 코드를 다른 튜터님이 해설 세션을 해주는 방식으로 세션이 진행됐다. 이번엔 기존 Todo 프로젝트에 엮어서 작성하다보니 끼워넣을 때 고민을 더 많이 해야했는데 깔끔한 프로젝트에서 보면 확실히 구조가 눈에 잘 띄었다.
우선 Jwt 인증, OAuth 인증 부분은 다행히도 이해한 부분과 많이 비슷했고 이전 챌린지반 강의도 도움이 많이 된 것 같다. 물론 구현 목표와 비즈니스 로직을 설계하는 부분은 압도적으로 차이가 났다.
테스트 코드
그 다음은 테스트 코드에 대한 세션이었다.
- @SpringBootTest는 유닛 테스트에 사용하기엔 무겁다. Bean도 다 세팅하고 하느라 Unit test를 하는 데에도 무거워지게 된다.
- 세부적으론 @DataJpaTest, @WebMvcTest 처럼 경량화된게 있다
- Stubbing은 Mock 객체의 메소드가 어떤 응답을 할지 결정해두는 것으로 이번에 많이 쓴 every도 이에 포함된다.
- Mocking시 createdAt 같은 값을 LocalDateTime.now() 처럼 하면 테스트가 시간의 영향을 받게 되므로 FIRST 원칙에 위반되니 정적인 값을 쓰는게 낫다.
- 테스트 코드는 제대로 된 시나리오 구성이 코드의 품질보다 더 중요하다.
- 시나리오 시트를 QA 시트처럼 시나리오/결과를 한줄로 간략히 정리하면 더욱 좋다.
- 기능 / Method / 성공,실패 / 시나리오 / 원하는결과
- 시나리오 시트를 QA 시트처럼 시나리오/결과를 한줄로 간략히 정리하면 더욱 좋다.
- 짧은 시간 안에 테스트 코드를 작성해야 한다면 우선순위를 결정하는게 좋다.
- 추천은 Domain Entity > Service > Client > Pojo > Repository > Controller
- 예측이 힘든 메소드는 우선순위랑 관계없이 작성하는게 좋다.
- Domain Entity + POJO
- 다른 객체를 의존 안해서 가장 테스트가 가볍고 쉽다.
- @Test 를 사용해서 jupiter만 써도 충분하다. + kotest assertions
- 도메인 로직이 있다면 다 테스트 해보면 된다.
- ex) Comment.validIsMine(writer, password) 가 있을 경우
- 시나리오 1. 올바른 값이 입력됐으면 TRUE를 반환하는지
- 시나리오 2. 올바르지 않은 값이 입력됐으면 FALSE를 반환하는지
- Service
- 다른 객체를 의존하기 때문에 Mocking + Stubbing이 필요하다.
- 추상화를 잘했으면 Service 내의 로직이 흐름만 갖고 있어서 검증할게 딱히 없을 수도 있다.
- 이 경우엔 예외상황에 대한 테스트만 작성하고 통합 테스트를 고려하는게 좋다.
- ex) create(todoId, request)가 있을시
- 시나리오 1. 존재하지 않는 todoId에 대한 예외 확인
- 시나리오 2. 성공하면 올바른 값의 entity 확인
- 결과 객체가 어떨지는 Mocking한게 있어서 에상하기 쉬우니
verify(exactly = 1) { ~~Repository.save(any()) }처럼 사용하면 .save가 한번만 호출된게 맞는지에 대해 테스트 해볼 수 있다.
- 결과 객체가 어떨지는 Mocking한게 있어서 에상하기 쉬우니
- Controller
- 특별한 코드가 들어간게 아니면 우선순위가 낮다.
- 유닛 테스트보단 E2E 테스트 코드를 고려하는게 더 효과적일 수 있다.
- @WebMvcTest(~~Controller::class) 를 사용하면 Controller 테스트에 필요한 만큼만 Spring을 사용한다.
- @AutoConfigureMockMvc, @MockkBean 등을 추가로 사용하면 간편하다.
- ex) createComment(todoId, request)가 있을시
- 시나리오 1. 정상적인 상황에 대한 결과 데이터 확인 (body & http status)
- 로직이 없기 때문에 테스트 내용이 많지 않다.
- MockMvc를 사용해서 Controller에 요청이 들어온 것처럼 테스트 가능하다.
- 시나리오 1. 정상적인 상황에 대한 결과 데이터 확인 (body & http status)
QueryDSL
- 어플리케이션의 문제중 많은 부분이 SQL 쿼리로 인해 발생한다. (특히 성능)
- JPA에 익숙해질수록 쿼리문을 예상하지 못하게 될 수도 있다.
- QueryDSL 버전은 Spring boot 버전이랑 잘 맞춰야 한다.
- Fetch join은 N+1을 해결하기 좋은 방법이지만 주의해야한다.
- Batch size는 N+1을 해결하는 근본적인 문제는 아니다.
챌린지반 - 클린 아키텍쳐
오늘은 지난번 OAuth에 이어서 클린 아키텍쳐에 대해 배웠다. 아키텍쳐라 하면 사실 별로 생각하고 싶지 않은게 제대로 이해해본 적이 없어서 영 반갑지가 않긴 하다.
그런데 오늘 수업에서 키워드가 꽤 자리잡을 수 있었던 것 같다.
아키텍처를 고민해야 하는 이유
사실 구조적인 문제가 항상 기술부채가 되는건 실무때 많이 겪어봤다. 나 혼자 개발할 때도 나중에 구조를 고치기 너무 어려웠는데 백엔드 팀에서 마이그레이션 진행하는걸 지켜볼 때는 정말 어려워보였었다.
그러니 아키텍처를 고민하는 이유는 나중에 고칠 시간은 없다고 가정하고 소프트웨어를 만들고 유지보수 하는 데에 필요한 인력을 최소화 하기 위해서라고 생각할 수 있다.
여기서 핵심으로 다뤄야 하는 키워드는 변경이라고 하셨다. 변경이 쉽게 가능하고 유연한 프로그램이 유지보수 하기 편한 것이다.
아키텍처란?
소프트웨어(시스템)를 개발하는데 구성 요소(객체, 서비스등)들을 어떤 구조로 배치하는지에 대한 것
강의에서 협력 구조를 다루는 것같은 행동도 아키텍처의 일부가 될 수 있다.
다양한 범위에서의 아키텍처가 있지만 강의에선 하나의 Spring boot 어플리케이션을 개발할 때의 아키텍처를 다룬다.
핵심 키워드 - 의존성 규칙
의존성이 또 등장했는데 의존성이 변경에 가장 큰 영향을 주기 때문인 것 같다.
객체지향에선 작은 범위를 다뤘지만 클린 아키텍처에선 모듈 단위로 다루게 된다.
핵심은 또 다시 한 번 의존성은 변경을 전파한다가 된다. 객체 단위가 아니라 모듈단위여도 저수준의 모듈은 고수준의 모듈을 의존하게 해야한다. 이것을 다시 의존성 규칙이라고 한다.
그림으로 보는 클린 아키텍처
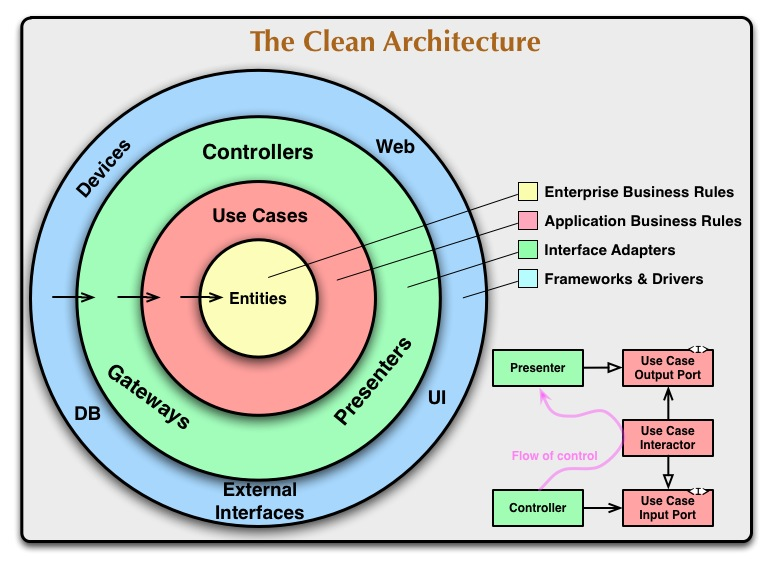
클린 아키텍처의 대표적인 그림으로 원 바깥이 안쪽으로 진행되지만 원 바깥이 원 안쪽에 전혀 영향을 주지 않는 것을 의미한다.
이 그림을 보면 원 내부가 원 외부를 전혀 알지 못하게 설계하는 것이 클린 아키텍처인데, 현재까지 배운 내용으로 비유하자면 Entity에 Dto의 변환 책임이 있는 것은 뭐가 어찌됐든 Entity 파일 내에 Dto의 정보를 가지는 것이기 때문에 클린 아키텍처적으로는 Dto가 책임을 갖는 것이 맞다고 생각할 수 있다.
즉 내가 작성한 코드가 어디에 위치해야 하는지에 대한 건 감각적이고 추상적인 부분이라 기본기의 영역이라고 한다. 경험이 코드를 보고 어색함/찜찜함을 느끼게 만든다.
Use case
Domain Entity에 포함되는 업무 규칙은 작고 순수해야한다.
하지만 항상 작을 수 없기 때문에 특정 어플리케이션에 특화된 업무 규칙이 필요하고 이걸 Use case라고 한다. 정말 추상적인 개념이라 이해하기가 어렵다.
Use case가 지켜야 할 것은
- 업무 규칙의 절차를 설명해야 한다.
- 구체적인 업무 규칙은 Domain Entity를 참조해 위임한다.
- Use case의 요청/응답 데이터는 간단한 형태여야 한다.
정리하면 Use case는 특정 목적을 이루기 위한 규칙 / 절차를 다루며 설명하고 그 과정에서 Entity가 어떻게 동작할지 위임하는 식이라고 하는데 여전히 추상적이게 느껴진다.
Hexagonal 아키텍처
클린 아키텍처는 단순히 개념이고 가이드라인이므로 구체적으로 클린 아키텍처를 구현했다고 표현하기는 어려운 감이 있다.
그러니 구체적인 방향성을 제시해주는 아키텍처도 있는데 그 중 강의에서 Hexagonal 아키텍처를 소개해주셨다.
클린 아키텍처 원형처럼 육각형 바깥에서 안쪽으로만 흐름이 진행되고 중심엔 Domain business logic이 위치한다.
그림만 보면 어지럽고 구성 요소에 따라 그림이 달라져서 개발하는 사람마다 구조가 달라질 수도 있다. Hexagonal 아키텍처도 구체적이래봤자 방향성과 흐름만 보여주는 느낌이다.
Port와 DbAdapter
실제로 사용중인 구조를 보여주셨는데 POJO 인터페이스인 Port 와 DbAdapter 를 사용하는데 Port에 Repository에 보내는 메소드를 정의하고 DbAdapter가 Port의 요청을 받아 구체적인 JpaRepository등을 이용하는 것이다.
많이 익숙한 구조였는데 Port는 내가 Pojo 인터페이스로 만들던 Repository고 DbAdapter는 이 Port를 상속받은 RepositoryImpl이었다. RepositoryImpl은 MemberJpaRepository를 상속받는다.
다만 차이가 있었는데 Port, DbAdapter가 사용하는 Entity는 JpaEntity가 아니라 그냥 POJO Entity다. DbAdapter에서 POJO Entity를 Mapper 같은 라이브러리를 써서mapper.toJpaEntity(member) 같은 식으로 변형을 진행해야 jpaRepository.save(member) 가 가능해지는 것이다.
이 목적은 Service가 Jpa에 관해 조금의 정보도 모르게 Entity 마저 숨긴건데 강의에서도 이 정도까지는 할 수도 있고 아닐 수도 있다고 하셨다.
다만 JpaRepository를 바깥에서 숨긴것도 Jpa에 대한 의존성을 숨기기 위함이었으니 Entity, JpaEntity를 구분하는 것도 말이 되는 것 같다.
그리고 Package 구조도 여러모로 바뀌는 측면이 있어서 내가 만들던 POJO Repository와 목적은 비슷하지만 구조적으로는 많이 다르다는 느낌을 받았다.
튜터님은 Port라는 이름이 와닿지 않아서 Port를 Repository, Adapter를 RepositoryAdapter라는 이름으로 사용한다고 하셨다.
-
API 모듈 레벨
Controller & Application Service(UseCase)
UseCase -> Domain Entity, Repository -
도메인 레벨
Domain Entity (Domain Service), Repository (Port) -
인프라(DB) 레벨
Repository Adaptor -> JpaRepository
도메인 로직은 Domain Entity에 넣는 걸 원칙으로 한다. 하지만 도메인 로직을 전부 도메인에만 넣으면 다른 Repository 사용을 필요로 하거나 다른 모듈을 처리해야할 수도 있기 때문에 Domain service가 존재한다.
튜터님같은 경우 비즈니스 흐름은 방해하지만 도메인 로직은 아닌 친구들을 그냥 Service 라는 이름으로 API에 둔다고 하셨다.
최종 구조는 이런 느낌인 것 같다.
코드카타 - 프로그래머스 공원 산책
지나다니는 길을 'O', 장애물을 'X'로 나타낸 직사각형 격자 모양의 공원에서 로봇 강아지가 산책을 하려합니다. 산책은 로봇 강아지에 미리 입력된 명령에 따라 진행하며, 명령은 다음과 같은 형식으로 주어집니다.
- ["방향 거리", "방향 거리" … ]
예를 들어 "E 5"는 로봇 강아지가 현재 위치에서 동쪽으로 5칸 이동했다는 의미입니다. 로봇 강아지는 명령을 수행하기 전에 다음 두 가지를 먼저 확인합니다.
- 주어진 방향으로 이동할 때 공원을 벗어나는지 확인합니다.
- 주어진 방향으로 이동 중 장애물을 만나는지 확인합니다.
위 두 가지중 어느 하나라도 해당된다면, 로봇 강아지는 해당 명령을 무시하고 다음 명령을 수행합니다.
공원의 가로 길이가 W, 세로 길이가 H라고 할 때, 공원의 좌측 상단의 좌표는 (0, 0), 우측 하단의 좌표는 (H - 1, W - 1) 입니다.

공원을 나타내는 문자열 배열 park, 로봇 강아지가 수행할 명령이 담긴 문자열 배열 routes가 매개변수로 주어질 때, 로봇 강아지가 모든 명령을 수행 후 놓인 위치를 [세로 방향 좌표, 가로 방향 좌표] 순으로 배열에 담아 return 하도록 solution 함수를 완성해주세요.
fun solution(park: Array<String>, routes: Array<String>): IntArray {
var dogPoint = 0 to 0
var objectPointList = mutableListOf<Pair<Int, Int>>()
val width = park[0].length
val height = park.size
park.forEachIndexed { y, row ->
row.forEachIndexed { x, char ->
if (char == 'S') {
dogPoint = y to x
}
if (char == 'X') {
objectPointList.add(y to x)
}
}
}
routes.forEach routeForEach@ { route ->
val direction = route.split(" ")[0]
val distance = route.split(" ")[1].toInt()
var calculatedPoint = 0 to 0
when (direction) {
"N" -> calculatedPoint = dogPoint.first - distance to dogPoint.second
"S" -> calculatedPoint = dogPoint.first + distance to dogPoint.second
"W" -> calculatedPoint = dogPoint.first to dogPoint.second - distance
"E" -> calculatedPoint = dogPoint.first to dogPoint.second + distance
}
if (calculatedPoint.second < 0 || calculatedPoint.second >= width || calculatedPoint.first < 0 || calculatedPoint.first >= height)
return@routeForEach
}
val minX = minOf(dogPoint.second, calculatedPoint.second)
val maxX = maxOf(dogPoint.second, calculatedPoint.second)
val minY = minOf(dogPoint.first, calculatedPoint.first)
val maxY = maxOf(dogPoint.first, calculatedPoint.first)
objectPointList.forEach { objectPoint ->
if (objectPoint.second == dogPoint.second && objectPoint.first in minY .. maxY ||
objectPoint.first == dogPoint.first && objectPoint.second in minX .. maxX) {
return@routeForEach
}
}
dogPoint = calculatedPoint
}
return intArrayOf(dogPoint.first, dogPoint.second)
}코드의 속도는 그럭저럭 준수했는데 가독성이 미친듯이 떨어지는 느낌이다. 이번에도 여러모로 삽질을 많이 한것도 좀 슬프다.
우선 문제에서 y, x가 반대로 되어있어서 머릿속에서 자꾸 x, y로 계산하다보니 코드의 수정이 많아진 건 그냥 내가 머리가 안좋아서라고 할 수 있겠다.
그 다음은 역시나 경로의 조건에 대한 문제였다.
우선 방향을 기준으로 park의 범위를 벗어나는지까진 금방 체크했는데 장애물에 대한 처리에서 상당히 골치가 아팠다.
우선 동일 x좌표에서 y좌표를 검사하거나 그 반대의 경우를 제대로 생각 못해서 첫 제출은 절반이 틀렸고
그 다음은 x..x or y..y 범위에 대해서 책정을 잘못해서 잔뜩 틀려 minX, maxX등 추가 변수까지 가져와서 적용하게 됐다.
이렇게 하다보니 변수가 미친듯이 쓰였고 크게 마음에 들기는 어려운 코드가 됐다.
다른 사람들의 코드를 보면서 느낀건 Pair<Int, Int> 로 관리하지 않고 x, y에 대해 별도로 작성했으면 조건 검사, 계산이 훨씬 쉬웠을 것 같은데 이것도 참 아쉽게 됐다.
