
💡 앞으로 공부해야 할 유명하고 자주 쓰이는 자료구조와 알고리즘에 대해 간단하게 작성함
이를 토대로 더욱 넓게넓게 공부해야지 🙆♀️
Linked List
배열과 linked list의 차이
Array
- 정해진 크기
- 입력과 삭제가 비효율적
- 무작위 접근 가능 (ex:
array[4]이런식으로) - 메모리 낭비가 심할 수 있음
- 순차 접근이 더 빠름
- 이유: 각 요소의 메모리 위치가 순차적으로 있음
Linked list
- 크기가 동적임
- 입력과 삭제가 효율적
- 전체 데이터 구조를 재구성하지 않고, 노드를 링크된 목록에서 쉽게 제거하거나 추가할 수 있음.
- 무작위 접근 안됨
- 메모리 낭비 없음
- 순차 접근은 느림
- 이유: 각 요소의 메모리 위치가 순차적으로 있지 않음
- 단점
- 연결된 목록에서 검색 작업이 느림. 배열과 달리 데이터 요소의 임의 액세스는 허용되지 않음. 노드는 첫 번째 노드부터 순차적으로 액세스.
- 포인터의 저장 때문에 어레이보다 더 많은 메모리를 사용함.
singly linked list

- head 노드가 존재
- 각 노드는 데이터와 다음 노드에 대한 포인터를 갖고 있다.
- 일렬
doubly linked list

- head 노드가 존재
- 각 노드는 데이터와 다음, 이전 노드에 대한 포인터를 갖고 있다.
circular linked list

- head 노드가 존재
- 각 노드는 데이터와 다음 노드에 대한 포인터를 갖고 있다.
- 마지막 노드는 head node와 연결된다.
Binary Tree
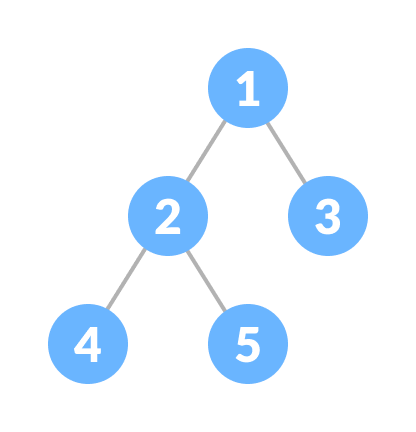
- tree structure 중에 가장 유명
- 면접 중에 가장 많이 물어볼 유형
- root가 있으며 각 노드는 최대 2개의 자식(left, right)이 있다.
Stack and Queue
언제 스택을 쓰고 큐를 쓸 지, 어떻게 작동하는지, 어떻게 만드는지 아는 것이 중요하다.
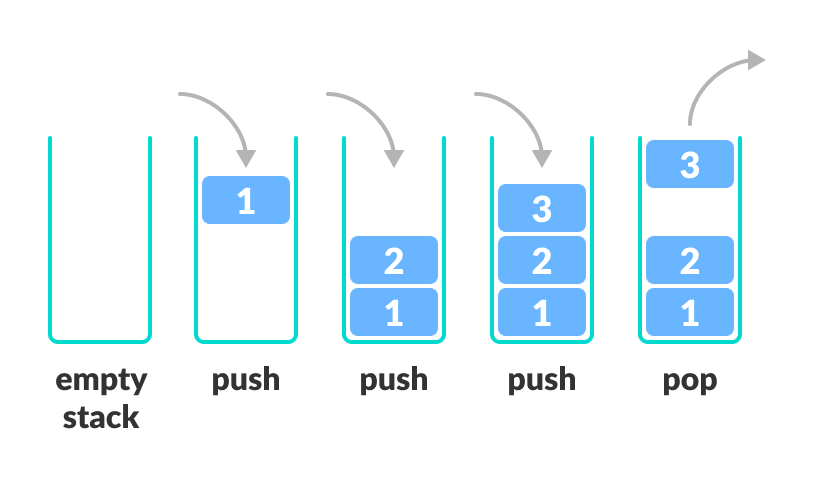
stack

스택은 위처럼, 접시 더미와 같다고 생각하면 된다.
- 제일 위에 접시를 새로 올림
- 제일 위의 접시를 가져감
- 마지막 접시를 가져가고 싶다면, 위에 쌓여진 접시들을 모두 이동시켜야한다.
- LIFO === Last in First Out
- 시간복잡도 : O(1)
queue

- FIFO === First In First Out === 선입선출
- 시간복잡도 : O(1)
- 큐의 종류
Merge Sort

작동원리
- 병합정렬은 대표적인 정렬 알고리즘 중 하나
- 버블소트 보다 더 빠름
- quick sort와는 사소한 차이가 있음
- merge sort가 좀더 빠르나 space를 좀더 차지함
- quick sort와 merge sort의 차이를 이해할 것!
- 리스트 길이가 0 or 1이면 이미 정렬된 것.
- 길이가 그 이상이면, 정렬되지 않은 리스트의 절반을 잘라, 비슷한 크기로 나눈다
- 각 리스트를 또 비교하여 병합정렬을 이용해 정렬한다. (반복)
- 두개 리스트를 하나의 정렬된 리스트로 합친다.
작동 원리의 이해: 예제
- [3, 4][2, 1]
- 둘로 나눈 뒤 가장 작은 chunk로 나눈다.
- [3][4] [2][1]
- 나눈 chunk들을 정렬하여 합친다.
- [3, 4][1, 2]
- index 0 을 각각 비교했을 때, 1이 3보다 작으므로 따로 빼준다.
- [3, 4][2]
- sorted array: [1]
- 다시 index 0을 각각 비교하여 따로 빼준다
- [3,4][ ]
- sorted array: [1, 2]
- 하나의 어레이가 공백이 됐으므로 이제 합친다.
- [1, 2, 3, 4]
Graph
- Graph 자료구조는 노드들의 집합으로, 각 노드는 데이터를 갖고있으며 다른 노드와 연결되어있다.
- 데이터를 갖고 있는 모든 것들은 노드이다.
- 노드와 노드의 연결은 edge이다. 연결때문에 새로운 edge가 생겨난다.
- 비선형 자료구조이다 (non-linear)
- 그래프는 V(vertice), E(edge)의 집합체이다.
- G = (V, E) 로 정의
- V: 정점들의 집합 (노드)
- E: 정점을 연결하는 간선
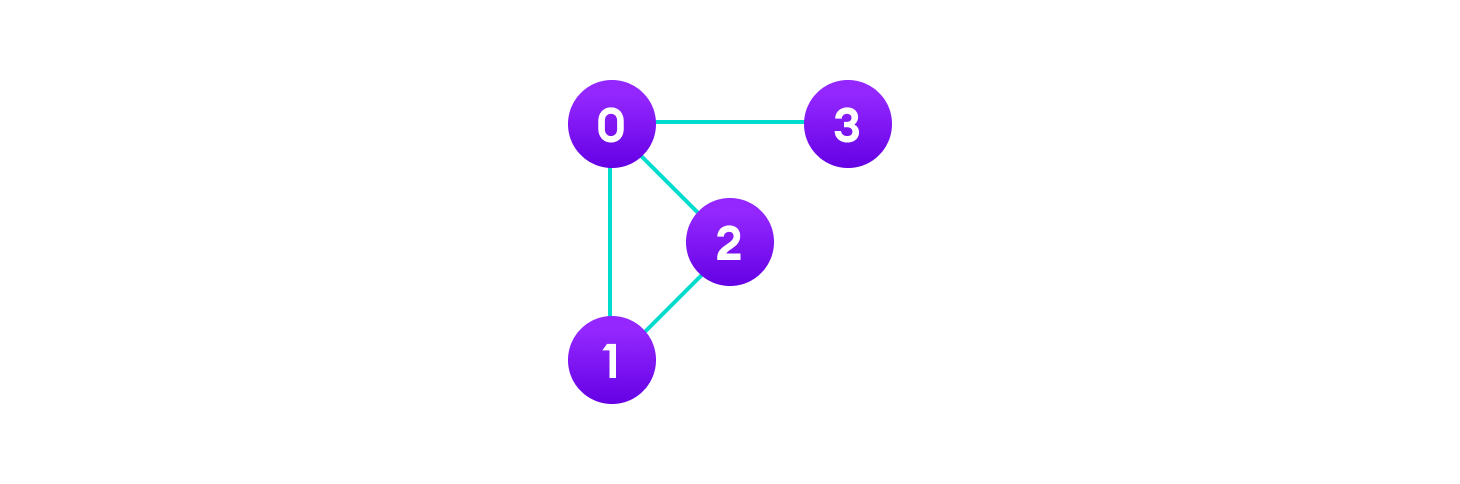
V = {0, 1, 2, 3} // 동그라미 : vertice
E = {(0,1), (0,2), (0,3), (1,2)} // 연결된 선 : edge
G = {V, E}
그래프와 트리의 차이

그래프의 종류

- 무방향 그래프 (Undirection Graph)
- 양방향으로 이어져있음.
- 노드 E는 4개의 degree를 가짐
- 방향 그래프 (Direction Graph)
- 각각의 노드는 개별적인 In-degree, Out-degree를 가짐
- 노드 E는 2개의 in-degree와 2개의 out-degree를 가짐
- 완전 그래프
- 모든 노드가 edge로 연결되어있는 그래프
- 부분 그래프
- 그래프의 부분 집합
- 가중 그래프
- 정점을 연결하는 간선(Edge)에 가중치를 할당한 그래프
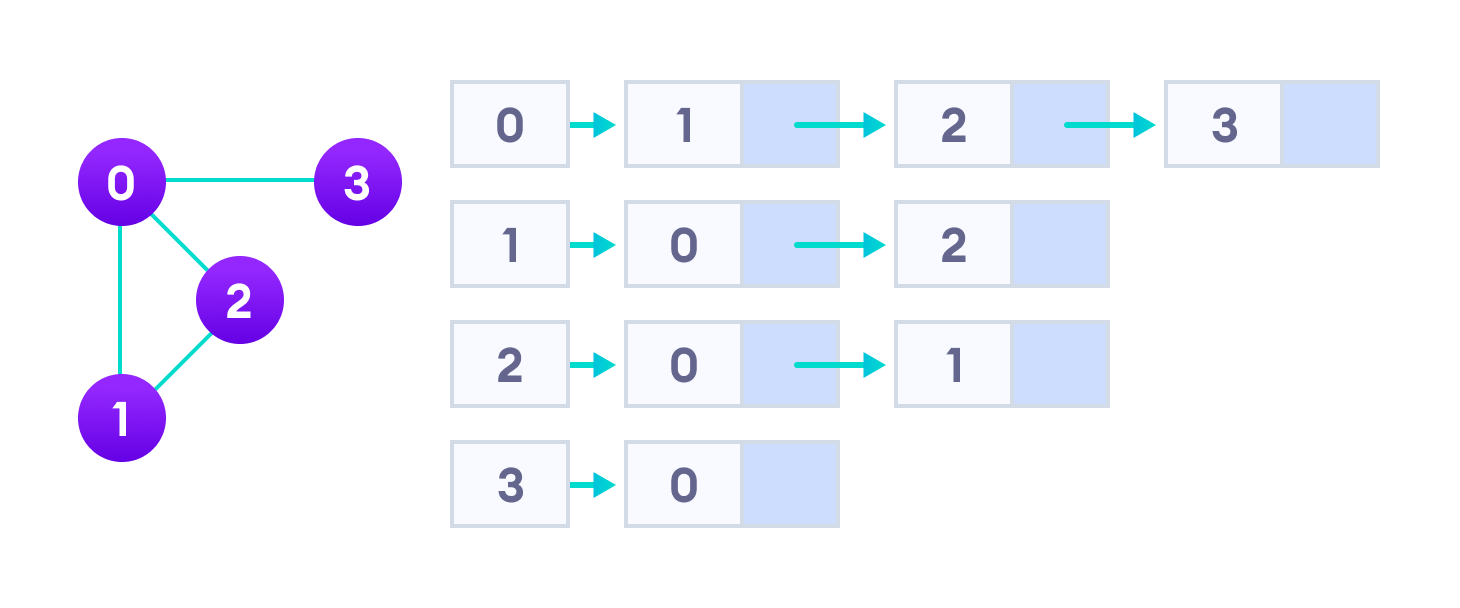
그래프를 코드로 구현하는 방법
vertex 개수가 작으면 이차원 배열, 크면 연결리스트를 사용하는게 효율적일 수 있다.
이차원 배열 (Adjacency Matrix)
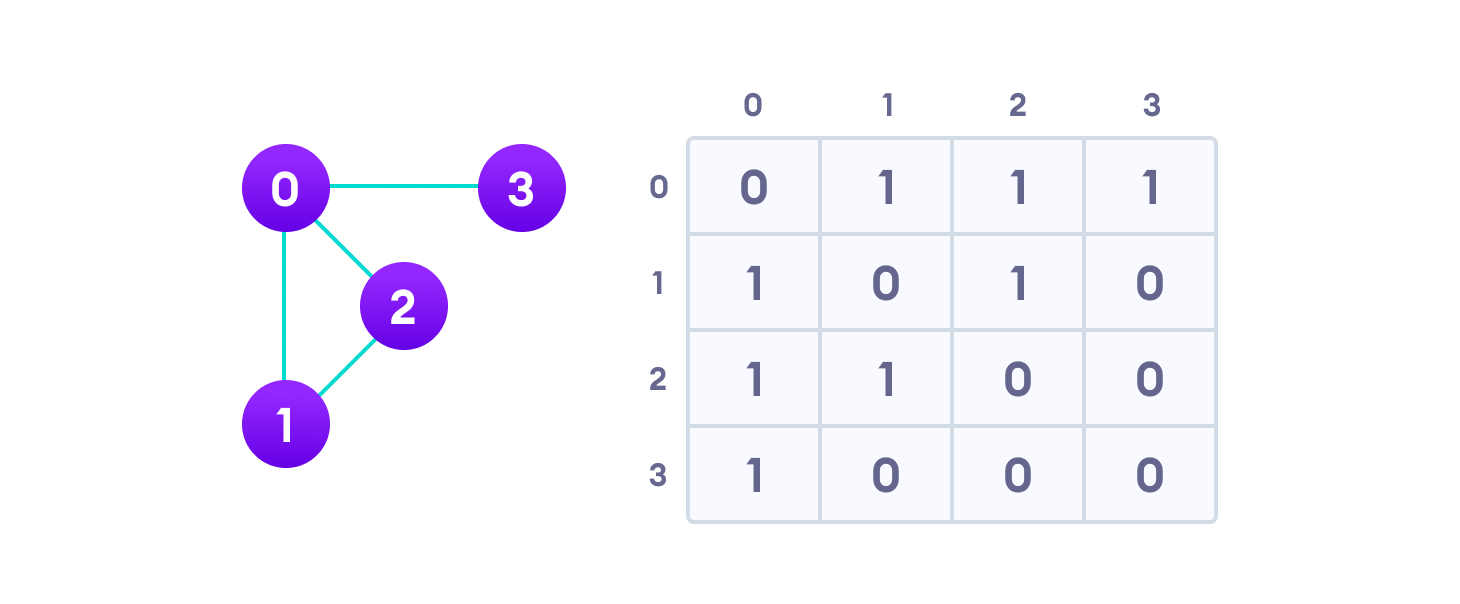
- 공간은 많이 차지하지만 간단하다.
연결 리스트 (Adjacency List)
Breadth / Depth First Search
Depth First Seach 깊이 우선 탐색
이해
- 그래프의 노드와 가장자리를 탐색하는데 사용되는 가장 기본적인 검색 알고리즘
- 0(V+E)의 시간복잡도
- 그다지 유용하진 않지만 특정한 케이스에선 유용함
- 모든 노드에 방문해야한다. 만약 이후의 노드가 없다면 뒤로 돌아가서 다른 노드에 방문. 이미 방문한 적 있는 노드에 도달했다면 다시 뒤로 돌아가서 다른 선택지의 노드를 방문한다. 그렇게 반복하며 모든 노드를 방문한다.
Breadth First Search 너비 우선 탐색
이해
- 정점들과 같은 레벨에 있는 노드들(형제 노드들)을 먼저 탐색하는 방식
- 두 개의 큐를 사용한다.
- root와 가까운 node들부터 찾기 때문에 최단거리를 탐색할 때 유용하다.
- queue에 각 노드의 정보를 기록해야 하기 때문에 메모리를 많이 잡아 먹는다.
- 찾고자 하는 target node가 root node와 가까이 있다고 예상될 경우 BFS를 사용한다.
- 지도 어플에서 특정 위치까지의 최단거리 안내, 혹은 소셜미디어에서 친구 추천 등에 이용된다.
- 깊이 우선 탐색(Depth First Search): 정점의 자식들을 먼저 탐색하는 방식
- 한 개의 큐와 한 개의 스택을 사용한다.
- BFS보다 속도가 느릴 수 있다.
- 미로 게임 등에서 경로가 존재하는지를 판별할 때 유용하다.
차이
- BFS 구조는 두 개의 큐를 활용하는데, DFS는 한 개의 스택과 한 개의 큐를 사용한다는 차이가 있음
- BFS 구조는 이전 노드와 연결된 노드들을 먼저 탐색해야 하기 때문에 queue,
- DFS는 이전 노드가 아니라 자기 자신과 연결되었던 노드들 먼저 탐색하기 때문에 stack을사용한다.
Memoization 메모이제이션
중복된 연산이 있을 때, 결과를 메모리에 저장하여 중복되는 연산을 줄이는 코딩 기법
제로초님의 설명
Recursion
자기 자신을 호출하는 함수
Big O Notation 표기법
시간복잡도의 종류
- Big-O
- Ω(Omega)
- Θ(Theta)
Θ표기법을 쓰는것이 가장 이상적이지만, 계산이 복잡하기때문에 보통은 Big-O표기법을 사용하여 시간복잡도를 나타낸다.
Big O 계산
- O(1) 알고리즘
- 입력 데이터의 크기에 상관없이 일정한 시간이 걸리는 알고리즘 표현.
- 연산 횟수 = 1, Big-O Notation = O(1)
- O(n)
- 입력 데이터의 크기에 비례해서 처리시간이 걸리는 알고리즘 표현.
- 연산 횟수 = 2n, Big-O Notation = O(n)
- O(n^2)
- 루프
- 연산 횟수 = n², Big-O Notation = O(n²)
- 실행 시간이 데이터의 크기가 늘어남에 따라 같이 증가하고, 그 증가율또한 증가한다. 데이터가 클수록 시간복잡도는 점점 더 빠르게 증가한다.
배열 method를 통해 시간복잡도를 이해해보자
자바스크림트의 배열은 다른 언어와 다르다.
typeof(array)가 object인 이유!
배열은 하나의 타입이 아니어도 되고, 연속적으로 이어져 있지 않다.
엄밀히 말하면 객체와 마찬가지.
index를 key로 가지며 length를 갖는 객체.
- push, pop
- 단순히 배열의 맨끝에 요소를 추가, 삭제
- O(1)
- unshift, splice
- 배열의 맨 앞과 중간에 요소를 추가하는 함수
- 기존의 index가 바뀌어야 하므로 1회 순회를 하며 작업
- O(n)
- sort
- 구현의 방식에 따라 속도와 복잡도가 달라짐
- filter, map, forEach
- O(n)
- 2중으로 사용하게 될 시, O(n^2)
- forEach와 단순 for구문은 일반적으로 for구문이 약 1.4배 빠르다고 함.
- 성능을 위해선 for loop을 쓰는 게 좋을 듯

고양이를 사랑하는 개발자😽