
HDFS란?
Hadoop Distributed File System의 줄임말로, 하둡은 분산 시스템인 HDFS에 데이터를 저장하고, 맵리듀스를 이용해 데이터를 처리한다. 하둡은
HDFS 기본 컨셉
HDFS는 JAVA로 작성된 Google의 GFS 기반의 파일 시스템입니다. 기존의 파일 시스템(ext3, ext4, or xfs)의 상위에서 동작하게 됩니다.
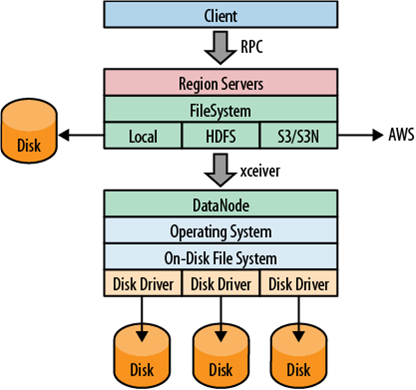
HDFS의 file 저장 방식
- File은 block 단위로 분할됩니다. (각 block은 기본적으로 64MB 또는 128MB 크기)
- 만약 데이터가 180M라면 (64+64+64 총 3개의 블럭에 나눠 들어가게 됩니다.)
- 데이터가 로드 될 때 여러 MACHINE에 분산되어 저장됩니다.
- 같은 file의 다른 block들은 서로 다른 machine에 저장됨
- 이를 통해 효율적인 MapReduce 처리가 가능
- Block들은 여러 machine에 복제되어 Data node에 저장됩니다.
- 기본 replication은 3개 (각 block은 서로 다른 3개의 machine에 저장되어 있다는 것을 의미)
- Name node로 불리는 master node는 어떤 block들이 file을 구성하고 있고, 어느 위치에 저장되어 있는지에 대한 정보를 meta data로 관리합니다.

데이터 file들은 block으로 분할되고, 데이터 노드에 분산되어 저장됩니다. 다시 각 block은 여러 node에 복제되어 저장되게 됩니다.
(defualt 3x) 3개의 노드로 카피되는 이유는 구글이 처음 시작할때 벤처회사로 시작하다보니 레거시 pc를 쓰다보니 고장 발생률이 높아 세개의 노드에 카피하게 되었습니다.
HDFS 사용법에서 hadoop fs -put 명령어를 입력하면 해당 데이터가 3개의 pc로 분산되어 자동 저장 될 것입니다. 이로 인해서 시스템 운영중 fault가 생겨도 잘 해결할 수 있게 됩니다. 이때 네임노느는 metadata를 저장하게 됩니다.
metadata란? 데이터에 대한 데이터(Data about Data/ Data on Data)를 칭합니다. 즉, 여기서 말하는 메타데이터는 파일 블럭 정보(데이터가 어떤 컴퓨터에 있는지)에 대한 데이터가 됩니다.
File이 64MB 또는 128MB의 block으로 분할 될 때, file이 block의 크기보다 작은 경우에는 block 크기 전체를 사용하지 않게 됩니다.
Block들은 Hadoop configuration에 설정된 디렉터리를 통해 저장됩니다. NameNode의 metadata를 사용하지 않으면, HDFS에 접근할수 있는 방법이 존재하지 않습니다.
클라이언트 애플리케이션이 file에 접근하는 경우:
NameNode와 통신하여 file을 구성하고 있는 block들의 정보와 DataNode의 Block의 위치 정보를 제공받습니다. 이후 데이터를 읽기 위해 DataNode와 직접 통신을 하게 됩니다. 결과적으로 읽기 작업만 일어나는 NameNode는 bottleneck이 되지 않습니다.
HDFS 접근 방법
HDFS 접근하는 방법에는 Shell 커맨드라인을 사용하거나 Java API 그리고 Ecosystem 프로젝트를 사용하는 방법이 있습니다. 대표적인 Ecosystem에는 Flume(network source로 부터 데이터 수집), Sqoop(HDFS와 RDBMS 사이의 데이터 전송),Hue(Web 기반의 interface UI로 browse, upload, download, file view 등이 가능) 등이 존재합니다.

HDFS 파일 저장과 조회
네임노드의 메타데이터 정보를 통해 /logs/031512.log 파일은 B1,B2,B3 블록에 /logs/041213.log 파일은 B4,B5 블럭에 존재한다는 것을 알아 낼 수 있습니다. 다시 블록 B1은 A, B, D 노드에 있다는 정보를 알아낼 수 있습니다. 전체 노드중 idle이 높은 노드를 선택하여 해당 노드로 부터 데이터를 액세스하게 됩니다.

HDFS 네임노드 가용성
NameNode daemon은 반드시 항상 실행되고 있어야 합니다. 만약, NameNode가 중단되면, 클러스터는 접근이 불가능합니다. 따라서 고가용성 모드 2개의 네임노드를 구성(Active와 Standby)하기도 합니다. 일반적인 Classic mode에서는 1개의 네임노드와 또다른 "helper" 노드는 SecondaryNameNode로 구성됩니다. 이 때, helper 노드는 백업 목적이 아니며, 네임노드를 복수할 수 있는 정보를 가지고 있는 PC입니다. 따라서 장애 발생시 NameNode를 대신하는 것이 불가능합니다.
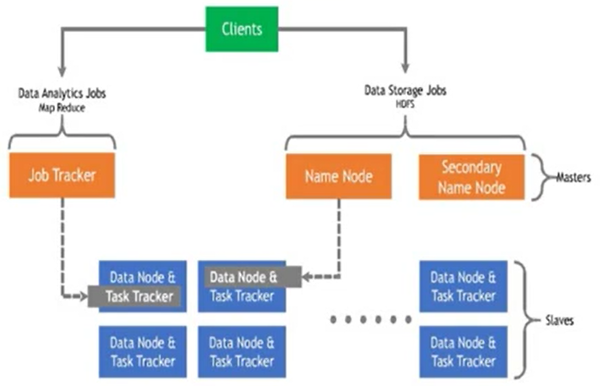
Hadoop의 구성요소
- Client: Name Node를 통해 정보를 받고 이후 직접적으로 Data Node와 통신을 합니다.
- Master node : 물리적으로 Master Node 역할(Job Tracker, Name Node)을 하는 노드로서, slave node에 대한 정보와 실행을 할 Tasks에 대한 관리를 담당합니다.
- Slave node : 물리적으로 Slave Node 역할(Data Node, Task Node)을 하는 노드로서, 실제로 데이터를 분산되어 있으며 Client에서 요청이 오면 데이터를 전달하는 역할 및 담당 Task를 수행하는 역할을 합니다.
Data Analytics 관점
Job Tracker: 노드에 있는 Task를 할당하는 역할과 모든 Task를 모니터링하고 실패할 경우 Task를 재실행하는 역할.Task Tracker: Task는 Map Task와 Reduce Task로 나눠질 수 있으며, Task가 위치한 HDFS의 데이터를 사용하여 MapReduce를 수행.
Data Storage 관점
Name Node: HDFS의 파일 및 디렉터리에 대한 메타 데이터를 유지. 클라이언트로 부터 데이터 위치 요청이 오면 전달, 장애 손상시 Secondary Node로 대체
Data Node: 데이터를 HDFS의 Block 단위로 구성. Fault Recovery를 위해 default로 3 copy를 유지, Heartbeat를 통하여 지속적으로 파일 위치 전달.
