
맵 리듀스(MapReduce) 개념
맵리듀스(MapReduce)는 구글에서 정보 검색을 위한 데이터 가공(색인어 추출, 정렬 및 역 인덱스 생성)을 목적으로 개발된 분산 환경에서의 병렬 데이터 처리 기법이자 프로그래밍 모델이다.
맵리듀스는 비공유 구조(shared-nothing)로 연결된 여러 노드 pc들을 가지고 대량의 병렬처리 방식(MPP, Massively Parallet Processing)으로 대용량 데이터를 처리할 수 있는 방법을 제공한다. 맵리듀스는 LISP 프로그래밍 언어에서 맵(Map) 리듀스(Reduce)라는 함수의 개념을 차용하여 시스템 분산구조를 감추면서 병렬프로그래밍을 가능하게 한다.
맵(map) 리듀스(reduce) 라는 두개의 메서드로 구성되어 있으며 맵(map) 메서드는 키-값을 읽어 필터링 하거나 다른 값으로 변환하는 작업을 수행한다. 리듀스(reduce)는 맵(map) 함수를 통해 출력된 결과 값을 새로운 키 기준으로 그룹화(grouping) 한 후 집계연산(Aggregation)을 수행한 결과를 출력한다.
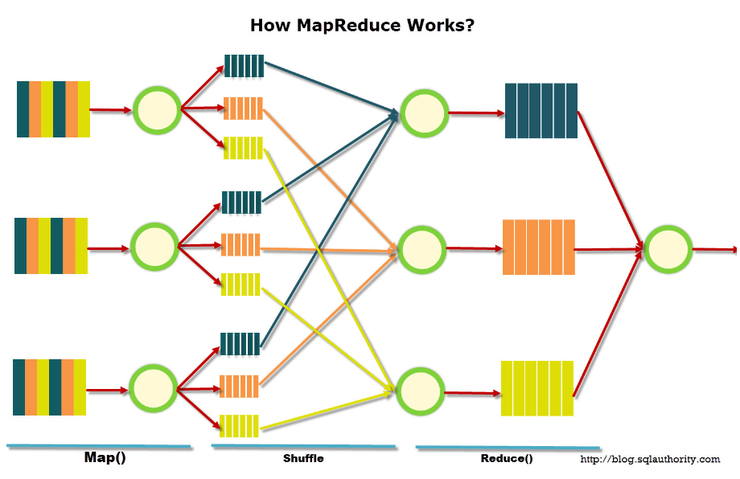
맵리듀스 수행 시 파일 시스템의 각 청크들은 맵 함수를 수행하는 Mapper 태스크에 할당된다. Mapper는 여러 노드에 분산되어 있으며 각기 청크를 받아 map 함수를 수행하여 결과를 각 mapper가 수행된 로컬 디스크에 기록한다. 만약 처리할 청크가 남아 잇으면 유휴 mapper에게 청크를 할당받아 부하를 분산한다. 모든 청크가 처리되었다면 맵리듀스 스케줄러는 Reducer 태스크를 수행한다.
리듀스는 여러 노드들로부터 처리해야 할 키 값을 이전 mapper들의 로컬 디스크로부터 읽어와 처리(그룹화, 연산)한다. 데이터 처리 중에 장애 발생 시 mapper의 경우 같은 청크를 대상으로 다시 수행하거나 유휴한 다른 mapper가 해당 청크를 수행하여 내고장성을 지원한다. 리듀스 장애의 경우 mapper의 작업은 건너뛰고 Reducer 작업을 다시 수행한다.
- 맵리듀스의 장단점
| 장점 | 단점 |
|---|---|
| - 단순하고 사용이 편리 - 특정 데이터모델이나 스키마, 질의에 의존적이지 않은 유연성 - 저장 구조의 독립성 -데이터복제에 기반한 내구성과 재수행을 통한 내고장성 확보 - 높은 확장성 | - 고정된 단일 데이터 흐름 - 기존 DBMS보다 불편한 스키마, 질의 - 단순한 스케줄링 - DBMS와 비교하여 상대적으로 낮은 성능 -개발도구의 불편함과 기술지원의 어려움 |
[참고자료]
l http://bart7449.tistory.com/276
l http://blog.sqlauthority.com/2013/10/09/big-data-buzz-words-what-is-mapreduce-day-7-of-21/
